
讓機器人在“想象”中學習世界的模型來了!PI聯創課題組&清華陳建宇團隊聯合出品
零真機、長時穩定、厘米級控制
Ctrl-World團隊 投稿
量子位 | 公眾號 QbitAI
這兩天,Physical Intelligence(PI)聯合創始人Chelsea Finn在上,對斯坦福課題組一項最新世界模型工作kuakua連續點贊。
生成看起來不錯的視頻很容易,難的是構建一個真正對機器人有用的通用模型——它需要緊密跟隨動作,還要足夠準確以避免頻繁幻覺。


這項研究,正是她在斯坦福帶領的課題組與清華大學陳建宇團隊聯合提出的可控生成世界模型Ctrl-World。
這是一個能讓機器人在“想象空間”中完成任務預演、策略評估與自我迭代的突破性方案。
核心數據顯示,該模型使用零真機數據,大幅提升策略在某些在下游任務的指令跟隨能力,成功率從38.7%提升至83.4%,平均改進幅度達44.7%。
其相關論文《CTRL-WORLD:A CONTROLLABLE GENERATIVE WORLD MODEL FOR ROBOT MANIPULATION》已發布于arXiv平臺。

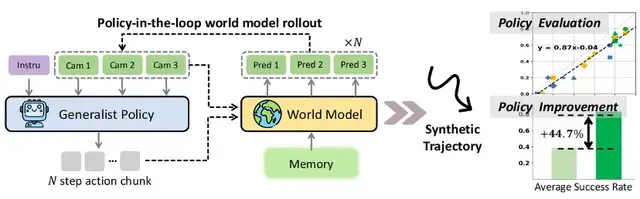
注:Ctrl-World專為通用機器人策略的策略在環軌跡推演而設計。它生成聯合多視角預測(包括腕部視角),通過幀級條件控制實現細粒度動作控制,并通過姿態條件記憶檢索維持連貫的長時程動態。這些組件實現了:(1)在想象中進行精準的策略評估,并與真實世界軌跡推演對齊(2)通過合成軌跡實現針對性的策略改進
研究背景:機器人訓練的“真實世界困境”與世界模型的破局價值
當前,視覺-語言-動作(VLA)模型雖在多種操作任務與場景中展現出卓越性能,但在開放世界場景中仍面臨兩大核心難題,這也是團隊研發CTRL-WORLD的核心動因:
難題一,策略評估成本高,真實測試燒錢又低效。
驗證機器人策略性能需在不同場景、任務中反復試錯。
以“抓取物體”任務為例,研究者需準備大小、材質、形狀各異的物體,搭配不同光照、桌面紋理的環境,讓機器人重復成百上千次操作。
不僅如此,測試中還可能出現機械臂碰撞(故障率約5%-8%)、物體損壞(損耗成本單輪測試超千元)等問題,單策略評估周期常達數天。更關鍵的是,抽樣測試無法覆蓋所有潛在場景,難以全面暴露策略缺陷。
難題二,策略迭代同樣難,真實場景數據永遠不夠用。
即便在含95k軌跡、564個場景的DROID數據集上訓練的主流模型π?.?,面對“抓取左上角物體”“折疊帶花紋毛巾”等陌生指令或“手套、訂書機”等未見過的物體時,成功率僅38.7%。
傳統改進方式依賴人類專家標注新數據,但標注速度遠趕不上場景更新速度——標注100條高質量折疊毛巾軌跡需資深工程師20小時,成本超萬元,且無法覆蓋所有異形物體與指令變體。
開放世界尚存在棘手問題,另一邊,傳統世界模型目前也還面臨三大痛點——
為解決真實世界依賴,學界曾嘗試用世界模型(即虛擬模擬器)讓機器人在想象中訓練。
但研究團隊在論文《CTRL-WORLD:A CONTROLLABLE GENERATIVE WORLD MODEL FOR ROBOT MANIPULATION》中指出,現有世界模型多數方法聚焦于被動視頻預測場景,無法與先進通用策略進行主動交互。
具體來說,存在三大關鍵局限,阻礙其支持策略在環(policy-in-the-loop)推演:
- 單視角導致幻覺
- 多數模型僅模擬單一第三人稱視角,導致“部分可觀測性問題”——例如機械臂抓取物體時,模型看不到腕部與物體的接觸狀態,可能出現“物體無物理接觸卻瞬移到夾爪中”的幻覺;
- 動作控制不精細
- 傳統模型多依賴文本或初始圖像條件,無法綁定高頻、細微的動作信號,例如機械臂“Z軸移動6厘米”與“Z軸移動4厘米”的差異無法被準確反映,導致虛擬預演與真實動作脫節;
- 長時一致性差
- 隨著預測時間延長,微小誤差會不斷累積,導致“時序漂移”——論文實驗顯示,傳統模型在10秒預演后,物體位置與真實物理規律的偏差,失去參考價值。
為此,清華大學陳建宇與斯坦福大學Chelsea Finn兩大團隊聯合提出CTRL-WORLD,旨在構建一個“能精準模擬、可長期穩定、與真實對齊”的機器人虛擬訓練空間,讓機器人通過“想象”訓練。
三大創新技術,讓CTRL-WORLD突破傳統世界模型局限
Ctrl-World通過三項針對性設計,解決了傳統世界模型的痛點,實現“高保真、可控制、長連貫”的虛擬預演。
論文強調,這三大創新共同將“被動視頻生成模型”轉化為“可與VLA策略閉環交互的模擬器”。
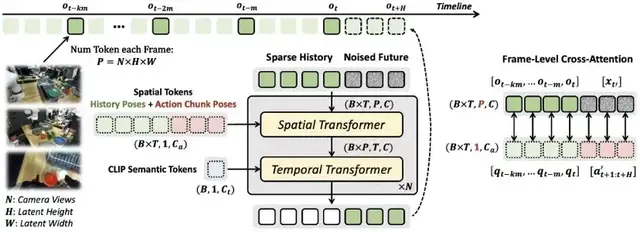
Ctrl-World基于預訓練視頻擴散模型初始化,并通過以下方式適配為一個可控且時間一致的世界模型:
- 多視角輸入與聯合預測
- 幀級動作條件控制
- 姿態條件記憶檢索
第一,多視角聯合預測:解決“視野盲區”,降低幻覺率
一般來說,以往模型靠單視圖預測,存在部分觀測問題與幻覺。
而Ctrl-World結合第三人稱與腕部視圖聯合預測,生成的未來軌跡精準且貼合真實情況。

傳統世界模型僅模擬單一第三方視角,本質是“信息不全”。
而CTRL-WORLD創新性地聯合生成第三方全局視角+腕部第一視角:
- 第三方視角提供環境全局信息(如物體在桌面的整體布局),腕部視角捕捉接觸細節(如機械爪與毛巾的摩擦、與抽屜的碰撞位置);
- 模型通過空間Transformer將多視角圖像token拼接(單幀含3個192×320圖像,編碼為24×40latent特征),實現跨視角空間關系對齊。

論文實驗驗證了這一設計的價值:
在涉及機械臂與物體接觸的精細操作任務中(如抓取小型物體),腕部視角可精準捕捉夾爪與物體的接觸狀態(如捏合力度、接觸位置),顯著減少“無物理接觸卻完成抓取的幻覺”。
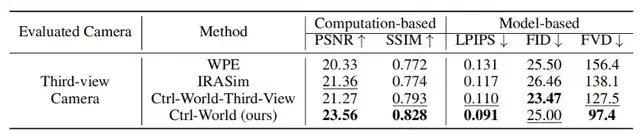
定量數據顯示,該設計使物體交互幻覺率降低;在多視角評估中,Ctrl-World的峰值信噪比(PSNR)達23.56,遠超傳統單視角模型WPE(20.33)和IRASim(21.36),結構相似性(SSIM)0.828也顯著高于基線(WPE0.772、IRASim0.774),證明虛擬畫面與真實場景的高度契合。
第二,幀級動作控制:綁定動作與視覺因果,實現厘米級精準操控
要讓虛擬預演“可控”,必須建立“動作-視覺”的強因果關系。
Ctrl-World的解決方案是“幀級動作綁定”:
- 將機器人輸出的動作序列(如關節速度)轉化為笛卡爾空間中的機械臂姿態參數;
- 通過幀級交叉注意力模塊,讓每一幀的視覺預測都與對應的姿態參數嚴格對齊——就像“分鏡腳本”對應每一幕劇情,確保“動作A必然導致視覺結果B”。

注:上圖展示的是Ctrl-World的可控性及其消融實驗。不同的動作序列可以在Ctrl-World中以厘米級的精度產生不同的展開結果。移除記憶會導致預測模糊(藍色),而移除幀級姿勢條件會降低控制精度(紫色)。注意力可視化(左側)在預測(t=4)秒幀時,對具有相同姿勢的(t=0)秒幀顯示出強烈的注意力,說明了記憶檢索的有效性。為了清晰起見,每個動作塊都用自然語言表達(例如,“Z軸-6厘米”)。由于空間限制,僅可視化了中間幀的腕部視角。

論文中給出了直觀案例:
當機械臂執行不同的空間位移或姿態調整動作時(如沿特定軸的厘米級移動、夾爪開合),Ctrl-World能生成與動作嚴格對應的預演軌跡,即使是細微的動作差異(如幾厘米的位移變化),也能被準確區分和模擬。
定量ablation實驗顯示,若移除“幀級動作條件”,模型的PSNR會從23.56降至21.20,LPIPS(感知相似度,數值越低越好)從0.091升至0.109,證明該設計是精準控制的核心。
第三,姿態條件記憶檢索:給長時模擬“裝穩定器”,20秒長時預演不漂移
長時預演的“時序漂移”,本質是模型“忘記歷史狀態”。
Ctrl-World引入“姿態條件記憶檢索機制”,通過兩個關鍵步驟解決:
- 稀疏記憶采樣:從歷史軌跡中以固定步長(如1-2秒)采樣k幀(論文中k=7),避免上下文過長導致的計算負擔;
- 姿態錨定檢索:將采樣幀的機械臂姿態信息嵌入視覺token,在預測新幀時,模型會自動檢索“與當前姿態相似的歷史幀”,以歷史狀態校準當前預測,避免漂移。

注:上圖展示的是Ctrl-World的一致性。由于腕部攝像頭的視野在單一軌跡中會發生顯著變化,利用多視角信息和記憶檢索對于生成一致的腕部視角預測至關重要。綠色框中突出顯示的預測是從其他攝像頭視角推斷出來的,而紅色框中的預測則是從記憶中檢索得到的。


論文實驗顯示,該機制能讓Ctrl-World穩定生成20秒以上的連貫軌跡,時序一致性指標FVD(視頻幀距離,數值越低越好)僅97.4,遠低于WPE(156.4)和IRASim(138.1)。
ablation實驗證明,若移除記憶模塊,模型的FVD會從97.4升至105.5,PSNR從23.56降至23.06,驗證了記憶機制對長時一致性的關鍵作用。
實驗驗證:從“虛擬評估”到“策略提升”的全流程實效
團隊在DROID機器人平臺(含Panda機械臂、1個腕部相機+2個第三方相機)上開展三輪實驗測試,從生成質量、評估準確性、策略優化三個維度全面驗證CTRL-WORLD的性能:
生成質量:多指標碾壓傳統模型
在10秒長軌跡生成測試中(256個隨機剪輯,15步/秒動作輸入),CTRL-WORLD在核心指標上全面領先基線模型(WPE、IRASim):
- PSNR:23.56(WPE為20.33,IRASim為21.36),虛擬畫面與真實場景的像素相似度提升15%-16%;
- SSIM:0.828(WPE為0.772,IRASim為0.774),物體形狀、位置關系的結構一致性顯著增強;
- LPIPS:0.091(WPE為0.131,IRASim為0.117),從人類視覺感知看,虛擬與真實畫面幾乎難以區分;
- FVD:97.4(WPE為156.4,IRASim為138.1),時序連貫性提升29%-38%。
更關鍵的是,面對訓練中未見過的相機布局(如新增頂部視角),CTRL-WORLD能零樣本適配,生成連貫多視角軌跡,證明其場景泛化能力。
策略評估:虛擬打分與真實表現高度對齊
論文結果顯示:
虛擬預演的“指令跟隨率”與真實世界的相關系數達0.87(擬合公式y=0.87x-0.04)。
虛擬“任務成功率”與真實世界的相關系數達0.81(y=0.81x-0.11)。

這意味著,研究者無需啟動真實機器人,僅通過Ctrl-World的虛擬預演,就能準確判斷策略的真實性能,將策略評估周期從“周級”縮短至“小時級”。
策略優化:400條虛擬軌跡實現44.7%性能飛躍
Ctrl-World的終極價值在于用虛擬數據改進真實策略。
團隊以π?.?為基礎策略,按以下步驟進行優化(對應論文Algorithm1):
- 虛擬探索:在Ctrl-World中,通過“指令重述”(如將“放手套進盒子”改為“拿起布料放入盒子”)和“初始狀態隨機重置”,生成400條陌生任務的預演軌跡;
- 篩選高質量數據:由人類標注員篩選出25-50條“成功軌跡”(如準確折疊指定方向的毛巾、抓取異形物體);
- 監督微調:用這些虛擬成功軌跡微調π?.?策略。
論文給出的細分任務改進數據極具說服力:
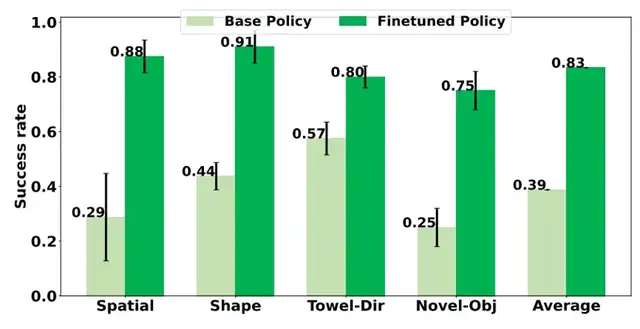
- 空間理解任務:識別“左上角物體”、“右下角物體”等指令的成功率,從平均28.75%升至87.5%;
- 形狀理解任務:區分“大/小紅塊”、“大/小綠塊”的成功率,從43.74%升至91.25%;
- 毛巾折疊(指定方向):按“左右折疊”、“右左折疊”等指令執行的成功率,從57.5%升至80%;
- 新物體任務:抓取“手套”、“訂書機”等未見過物體的成功率,從25%升至75%。
綜合所有陌生場景,π?.?的任務成功率從38.7%飆升至83.4%,平均提升44.7%——更關鍵的是,整個過程未消耗任何真實物理資源,成本僅為傳統專家數據方法的1/20。
研究與未來:讓“想象”更貼近真實物理規律
盡管成果顯著,團隊也坦言CTRL-WORLD仍有改進空間:
首先,復雜物理場景適配不足。
在“液體傾倒”“高速碰撞”等任務中,虛擬模擬與真實物理規律的偏差,主要因模型對重力、摩擦力的建模精度不足。
其次,初始觀測敏感性高。
若第一幀畫面模糊(如光照過暗),后續推演誤差會快速累積。
未來,團隊計劃從兩方面突破——
一方面將視頻生成與強化學習結合,讓機器人在虛擬世界自主探索最優策略;
另一方面擴大訓練數據集(當前基于DROID),加入“廚房油污環境”、“戶外光照變化”等復雜場景數據,提升模型對極端環境的適配能力。
總的來說,此前機器人學習依賴“真實交互-數據收集-模型訓練”的循環,本質是用物理資源換性能;而CTRL-WORLD構建了“虛擬預演-評估-優化-真實部署”的新閉環,讓機器人能通過“想象”高效迭代。
該成果的價值不僅限于實驗室。
對工業場景而言,它可降低機械臂調試成本(單條生產線調試周期從1周縮至1天)。
對家庭服務機器人而言,它能快速適配“操作異形水杯”“整理不規則衣物”等個性化任務。
隨著視頻擴散模型對物理規律建模的進一步精準,未來的CTRL-WORLD有望成為機器人“通用訓練平臺”,推動人形機器人更快走向開放世界。
論文地址:
https://arxiv.org/pdf/2510.10125
GitHub鏈接:
https://github.com/Robert-gyj/Ctrl-World
- DeepSeek-V3.2系列開源,性能直接對標Gemini-3.0-Pro2025-12-01
- 誤入人均10個頂級offer的技術天團活動,頂尖AI人才的選擇邏輯我悟了2025-12-04
- 字節“豆包手機”剛開賣,吉利系進展也曝光了:首月速成200人團隊,挖遍華為小米榮耀2025-12-01
- 居然有21%的ICLR 2026評審純用AI生成…2025-11-30
相關閱讀










