DeepSeek-V3.2系列開源,性能直接對標Gemini-3.0-Pro
開源模型又靠DS上大分
衡宇 發自 奧特賽德
量子位 | 公眾號 QbitAI
突襲!
ChatGPT發布三周年,DeepSeek嚯一下發出兩個模型:
- DeepSeek-V3.2
- DeepSeek-V3.2-Speciale
前者聚焦平衡實用,適用于日常問答、通用Agent任務、真實應用場景下的工具調用。
推理達GPT-5水平,略低于Gemini-3.0-Pro。
后者主打極致推理,推理基準性能媲美Gemini-3.0-Pro。
還一把斬獲IMO 2025、CMO 2025、ICPC World Finals 2025、IOI 2025金牌。
劃重點,ICPC達到人類選手第二、IOI人類選手第十名水平。

具體來說,DeepSeek-V3.2側重于平衡推理能力與輸出長度,降低計算開銷。
DeepSeek官微推文中寫道,“DeepSeek-V3.2模型在Agent評測中達到了當前開源模型的最高水平”。
該模型其他情況如下:
- 推理能力比肩GPT-5;
- 相比Kimi-K2-Thinking大幅縮短輸出長度,減少用戶等待時間;
- DeepSeek旗下首個“思考融入工具調用” 的模型,支持思考/非思考雙模式工具調用;
- 基于1800+環境、85000+復雜指令的大規模Agent訓練數據,泛化能力強。
下圖展示的是DeepSeek-V3.2與其他模型在各類Agent工具調用評測集上的得分
——特別強調,DeepSeek-V3.2并沒有針對這些測試集的工具做特殊訓練。

DeepSeek-V3.2-Speciale是DeepSeek-V3.2的長思考增強版,融合了DeepSeek-Math-V2的定理證明能力。
在指令跟隨、數學證明、邏輯驗證方面,DeepSeek-V3.2-Speciale能力出眾,推薦用來完成高度復雜數學推理、編程競賽、學術研究類任務。
特別注明!這個版本目前沒有針對日常對話與寫作做專項優化。
而且僅供研究使用,不支持工具調用。
在高度復雜任務上,Speciale模型大幅優于標準版本,但消耗的Tokens也顯著更多,成本更高。

目前,DeepSeek的App和Web端,都已經更新為正式版DeepSeek-V3.2;Speciale版本目前僅供臨時API使用。
模型發布同時,技術報告也已經掛出來了。
論文里透露的技術細節相當硬核:
新的稀疏注意力機制DSA大幅降低計算復雜度,強化學習訓練的計算量超過預訓練的10%,還有全新的大規模Agent任務合成管線……
具體情況,我們詳細來看。
提出DSA高效稀疏注意力機制,長文本不再是負擔
DeepSeek-V3.2最大的架構創新是引入了DSA(DeepSeek Sparse Attention)機制。
傳統的注意力機制在處理長序列時計算復雜度是O(L2),嚴重制約了模型的部署效率和后續訓練的可擴展性。
DSA讓計算復雜度降低到O(L·k),k遠小于L。
與此同時,DSA讓模型在長上下文任務中顯著加速推理,且無明顯性能損失。
支持FP8精度,適配MLA(Multi-Query Attention)架構,訓練友好。

怎么做到的?
DSA主要包含兩個組件,一個叫lightning indexer(閃電索引器),另一個叫fine-grained token selection(細粒度token選擇)機制。
閃電索引器負責快速計算查詢token和歷史token之間的相關性分數,然后只選擇top-k個最相關的token進行注意力計算。
團隊特意選用了ReLU激活函數來提升吞吐量。
DeepSeek-V3.1-Terminus開始繼續訓練時,團隊采用了兩階段策略。
第一階段是Dense Warm-up,保持密集注意力,只訓練lightning indexer,讓它學會對齊主注意力的分布。
這個階段只用了1000步,處理了21億個tokens。
第二階段才引入稀疏機制,每個查詢token選擇2048個鍵值對,訓練了15000步,總共處理了9437億個tokens。
實測效果相當給力——
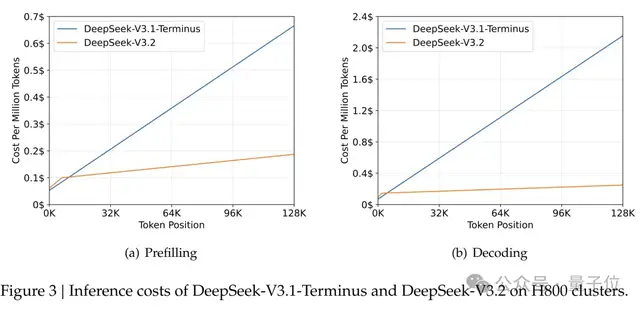
在128k長度的序列上,DeepSeek-V3.2的推理成本比V3.1-Terminus降低了好幾倍。
H800集群上的測試顯示,當序列長度達到128K時,預填充階段每百萬token的成本從0.7美元降到了0.2美元左右,解碼階段從2.4美元降到了0.8美元。
后訓練算力超過預訓練的10%
值得注意的是,DeepSeek團隊這次在強化學習上下了血本。
論文里明確提到,RL訓練的計算預算已經超過了預訓練成本的10%,這在開源模型里相當罕見。

DeepSeek在技術報告中提到,開源模型在post-training階段的計算資源投入不足,限制了其在困難任務上的性能。
為此,團隊開發了穩定、可擴展的RL協議,使訓練后階段的計算預算超過了預訓練成本的10%,從而解鎖了模型的先進能力。
展開講講——
為了穩定地擴展RL計算規模,團隊在GRPO(Group Relative Policy Optimization)算法基礎上做了好幾項改進。
首先是無偏KL估計,修正了原始的K3估計器,消除了系統性誤差。
原來的估計器在某些情況下會給出無界的梯度權重,導致訓練不穩定。
其次是離線序列掩碼策略。
在實際訓練中,為了提高效率通常會生成大批量的rollout數據,然后分成多個mini-batch進行梯度更新。這種做法本身就引入了off-policy行為。
團隊通過計算數據采樣策略和當前策略之間的KL散度,把那些偏離太遠的負樣本序列給mask掉,避免它們干擾訓練。
團隊還特別針對MoE模型設計了Keep Routing操作。
推理框架和訓練框架的實現差異可能導致同樣的輸入激活不同的專家,這會造成參數空間的突變。通過保存推理時的路由路徑并在訓練時強制使用相同路徑,確保了參數優化的一致性。
在具體訓練上,團隊采用了專家蒸餾的策略。
先為每個任務訓練專門的模型,包括數學、編程、通用邏輯推理、通用Agent任務、Agent編程和Agent搜索這6個領域,每個領域都支持思考和非思考兩種模式。
然后用這些專家模型生成特定領域的數據來訓練最終模型。
Agent能力的突破
此外,此次新模型在Agent任務上的突破也讓人眼前一亮。
這次團隊找到了讓模型同時具備推理和工具使用能力的方法。
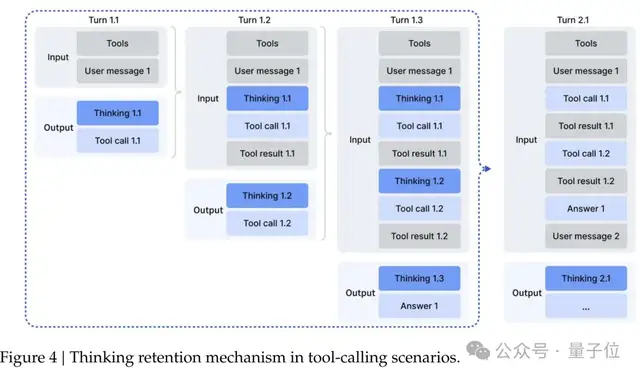
在思考上下文管理方面,團隊發現DeepSeek-R1那種每次開啟新對話就丟棄推理內容的策略,實在是太——浪費token了。
于是設計了新的管理機制:
只有在引入新的用戶消息時才丟棄歷史推理內容,如果只是添加工具相關消息,推理內容會被保留。即使推理痕跡被刪除,工具調用歷史和結果也會保留在上下文中。
冷啟動階段,DeepSeek-V3.2團隊采用了巧妙的prompt設計。
團隊通過精心設計的系統提示,讓模型學會在推理過程中自然地插入工具調用。
比如在處理編程競賽題目時,系統會明確要求模型先思考再給出答案,并用特殊標簽標記推理路徑。
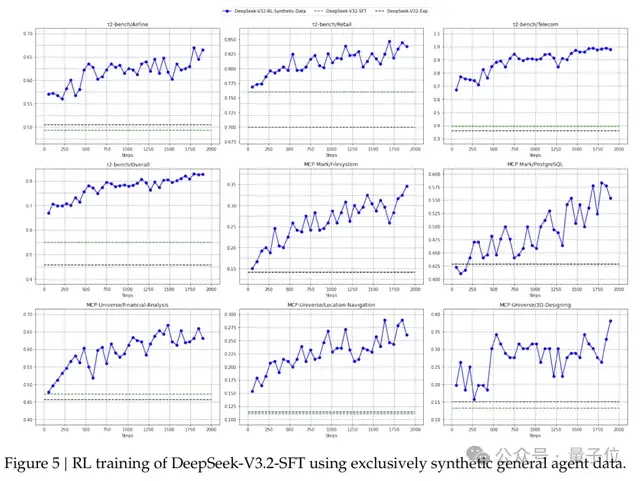
最硬核的是團隊開發了一個自動環境合成pipeline,生成了1827個任務導向的環境和85000個復雜提示。
以旅行規劃為例,模型需要在滿足各種約束條件下規劃三天的行程,包括不重復城市、根據酒店價格調整餐廳和景點預算等復雜邏輯。


雖然在巨大的組合空間中找到滿足所有約束的方案很困難,但驗證給定方案是否滿足約束相對簡單,這種”難解易驗”的特性非常適合RL訓練。
在代碼Agent方面,團隊從GitHub挖掘了數百萬個issue-PR對,經過嚴格篩選和自動環境構建,成功搭建了數萬個可執行的軟件問題解決環境,涵蓋Python、Java、JavaScript等多種語言。
搜索Agent則采用多Agentpipeline生成訓練數據,先從大規模網絡語料中采樣長尾實體,再通過問題構建、答案生成和驗證等步驟產生高質量數據。
評測結果顯示,DeepSeek-V3.2在SWE-Verified上達到73.1%的解決率,在Terminal Bench 2.0上準確率46.4%,都大幅超越了現有開源模型。
在MCP-Universe和Tool-Decathlon等工具使用基準測試上,DeepSeek-V3.2也展現出了接近閉源模型的性能。
這些提升,證明了模型能夠將推理策略泛化到訓練時未見過的Agent場景。

One More Thing
技術報告最后,研究人員坦誠地指出了一些局限性。
由于總訓練FLOPs較少,DeepSeek-V3.2的世界知識廣度仍落后于領先的閉源模型。
Token效率也是個挑戰。通常情況下,本次上新的兩個模型需要生成更長的軌跡,才能達到Gemini-3.0-Pro的輸出質量。
但團隊發話了,這些都是未來版本的改進方向。
不過——
DeepSeek啊DeepSeek,我們心心念念的R2,什么時候給抬上來啊!!!!
- 誤入人均10個頂級offer的技術天團活動,頂尖AI人才的選擇邏輯我悟了2025-12-04
- 字節“豆包手機”剛開賣,吉利系進展也曝光了:首月速成200人團隊,挖遍華為小米榮耀2025-12-01
- 居然有21%的ICLR 2026評審純用AI生成…2025-11-30
- 階躍開源4B Agent模型,跑通所有安卓設備,手搓黨一鍵部署2025-11-30
相關閱讀

千行百業,可信開源,2022 OSCAR開源產業大會成功召開