
機器人感知大升級!輕量化注入幾何先驗,成功率提升31%
讓機器人真正“看懂”三維世界
Evo-0團隊 投稿
量子位 | 公眾號 QbitAI
在機器人學習領域,如何讓AI真正“看懂”三維世界一直是個難題。
VLA模型通常建立在預訓練視覺語言模型(VLM)之上,僅基于2D圖像-文本數據訓練,缺乏真實世界操作所需的3D空間理解能力。
當前基于顯式深度輸入的增強方案雖有效,但依賴額外傳感器或深度估計網絡,存在部署難度、精度噪聲等問題。

為此,上海交通大學和劍橋大學提出一種增強視覺語言動作(VLA)模型空間理解能力的輕量化方法Evo-0,通過隱式注入3D幾何先驗,無需顯式深度輸入或額外傳感器。
該方法利用視覺幾何基礎模型VGGT,從多視角RGB圖像中提取3D結構信息,并融合到原有視覺語言模型中,實現空間感知能力的顯著提升。
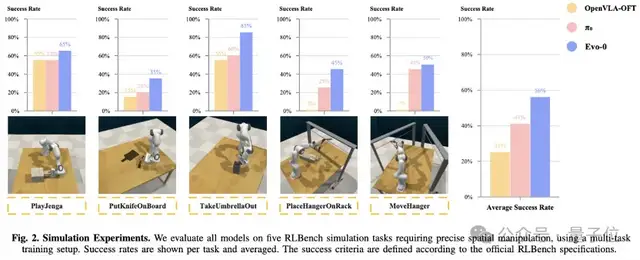
在rlbench仿真實驗中,Evo-0在5個需要精細操作的任務上,平均成功率超過基線pi0 15%,超過openvla-oft 31%。
Evo-0:實現2D–3D表征的融合
Evo-0提出將VGGT作為空間編碼器,引入VGGT訓練過程中針對3D結構任務提取的t3^D token。這些token包含深度上下文、跨視圖空間對應關系等幾何信息。
模型引入一個cross-attention融合模塊,將ViT提取的2D視覺token作為query,VGGT輸出的3D token作為key/value,實現2D–3D表征的融合,從而提升對空間結構、物體布局的理解能力。

融合后的token與語言指令共同輸入凍結主干的VLM,預測動作由flow-matching策略生成。訓練中,僅微調融合模塊、LoRA適配層與動作專家,降低計算成本。
研究團隊通過在5個rlbench模擬任務、5個真實世界操作任務上的全面實驗,以及在5種不同干擾條件下的魯棒性評估,證明了空間信息融合方法的有效性。在所有設置中,Evo-0都一致地增強了空間理解,并且優于最先進的VLA模型。
除了上述展示的效果外,在超參數實驗中,為了分析超參數如何影響模型性能,團隊在5個RLBench任務上進行了額外的實驗。他們重點關注兩個方面:訓練步數和執行步數,并評估它們對任務成功率的影響。
值得注意的是,僅用15k步訓練的Evo-0已經超過了用20k步訓練的π0,這表明Evo-0具有更高的訓練效率。

在真機實驗部分,實驗設計五個空間感知要求高的真實機器人任務,包括目標居中放置、插孔、密集抓取、置物架放置及透明物體操作等。所有任務均對空間精度容忍度極低。
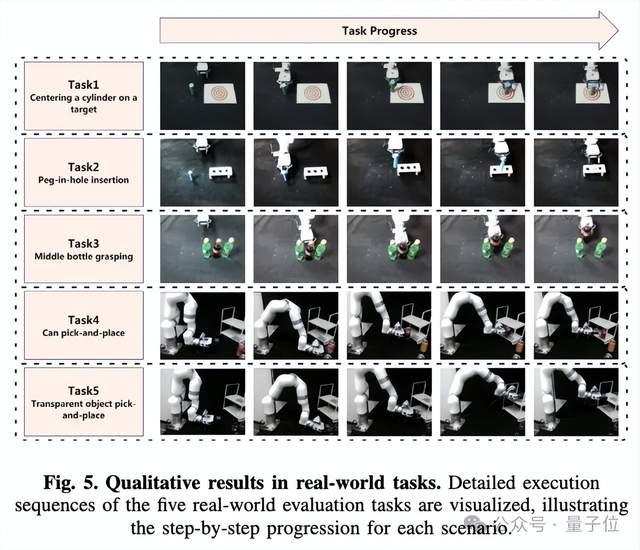
Evo-0在全部任務中均超越基線模型pi0,平均成功率提升28.88%。尤其在插孔與透明物抓取任務中,表現出對復雜空間關系的理解與精準操控能力。

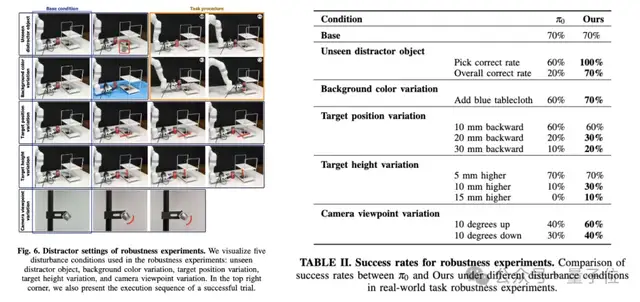
在魯棒性實驗中,論文設計了5類干擾條件:(1)引入一個未見過的干擾物體,(2)背景顏色的變化,(3)目標位置的位移,(4)目標高度的變化,(5)相機角度的變化。Evo-0均有相對魯棒的結果,并且強于基準pi0。
綜上所述,Evo-0的關鍵在于通過VGGT提取豐富的空間語義,繞過深度估計誤差與傳感器需求,以插件形式增強VLA模型的空間建模能力,訓練高效、部署靈活,為通用機器人策略提供新的可行路徑。
論文鏈接:https://arxiv.org/abs/2507.00416
- 快手進軍AI編程!“模型+工具+平臺”一口氣放三個大招2025-10-24
- 匯報一下ICCV全部獎項,恭喜朱俊彥團隊獲最佳論文2025-10-22
- OpenAI以為GPT-5搞出了數學大新聞,結果…哈薩比斯都覺得尷尬2025-10-20
- 首創“AI+真人”雙保障模式!剛剛,百度健康推出7×24小時「能聊、有料、會管」AI管家2025-10-18
相關閱讀










