
智源王仲遠(yuǎn):多模態(tài)大模型對(duì)產(chǎn)業(yè)更加重要,得多模態(tài)大模型得天下
其實(shí)Scaling Law在人工智能發(fā)展領(lǐng)域中一直起著作用
大模型的出現(xiàn),成了AI第三次浪潮的新拐點(diǎn)。
正值“Scaling Law是否撞墻”熱議之際,北京智源人工智能研究院院長(zhǎng)王仲遠(yuǎn)表示:
看過去七、八十年,每一次新的科技浪潮背后都有一些本質(zhì)規(guī)律,即隨著模型參數(shù)、訓(xùn)練數(shù)據(jù)及計(jì)算能力提升,模型效果也會(huì)有巨大提升。
也就是說,如果拉長(zhǎng)時(shí)間維度,其實(shí)Scaling Law在人工智能發(fā)展領(lǐng)域中一直起著作用。
此外,在本次量子位MEET 2025智能未來大會(huì)上,他還介紹了智源在過去6年里,建立了一支最早在國內(nèi)從事大模型研發(fā)的頂尖團(tuán)隊(duì),并且從2020年10月開始,就成立了技術(shù)攻關(guān)團(tuán)隊(duì)來持續(xù)推動(dòng)大模型技術(shù)研發(fā)探索。
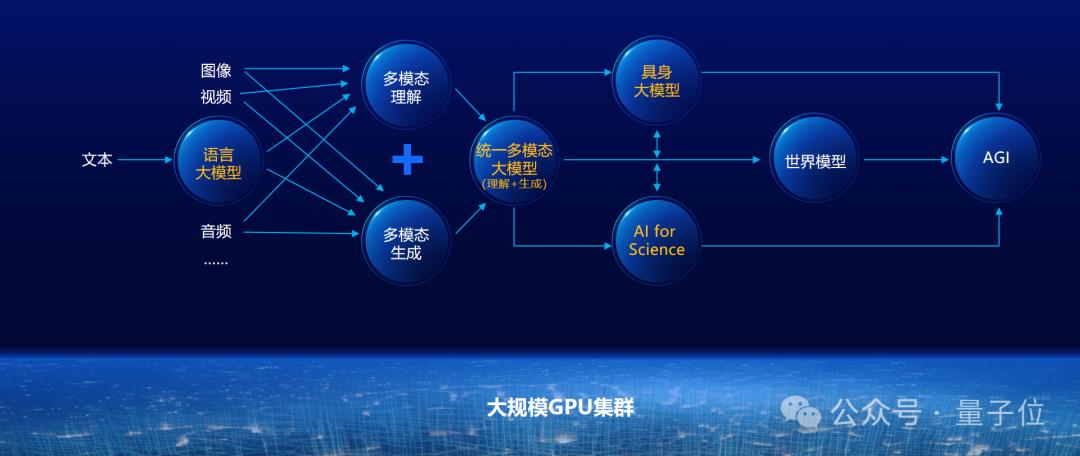
至于大模型未來的發(fā)展方向,在他看來,除了文本數(shù)據(jù),世界上還存在大量的圖像、音頻、視頻等多模態(tài)數(shù)據(jù)。如何激發(fā)這些數(shù)據(jù)中的智能,是未來大模型研究的重要方向。
原生統(tǒng)一的多模態(tài)大模型才能更好支撐產(chǎn)業(yè)落地應(yīng)用,實(shí)現(xiàn)人工智能對(duì)世界的感知、理解和推理。

為了完整體現(xiàn)王仲遠(yuǎn)的思考,在不改變?cè)獾幕A(chǔ)上,量子位對(duì)演講內(nèi)容進(jìn)行了編輯整理,希望能給你帶來更多啟發(fā)。
MEET 2025智能未來大會(huì)是由量子位主辦的行業(yè)峰會(huì),20余位產(chǎn)業(yè)代表與會(huì)討論。線下參會(huì)觀眾1000+,線上直播觀眾320萬+,獲得了主流媒體的廣泛關(guān)注與報(bào)道。
核心觀點(diǎn)梳理
- 當(dāng)下我們正處在人工智能七八十年歷程的第三次浪潮新拐點(diǎn),尤其是出現(xiàn)了大模型;
- 可以預(yù)期明年會(huì)有越來越多基于大模型的各種場(chǎng)景應(yīng)用的誕生;
- Scaling Law在大語言模型上開始放緩的一個(gè)非常重要的原因是文本數(shù)據(jù)消耗殆盡;
- 多模態(tài)數(shù)據(jù)如何進(jìn)一步激發(fā)大模型的智能,是一個(gè)非常重要的研究方向;
- 原生統(tǒng)一的多模態(tài)大模型才能更好支撐產(chǎn)業(yè)落地應(yīng)用,實(shí)現(xiàn)人工智能對(duì)世界的感知、理解、推理;
- ……
以下為王仲遠(yuǎn)演講全文:
大模型:AI第三次浪潮的新拐點(diǎn)
大家上午好,我是來自北京智源人工智能研究院的王仲遠(yuǎn)。
當(dāng)下我們正處在人工智能七八十年歷程的第三次浪潮新拐點(diǎn),尤其是出現(xiàn)了大模型。
以2023年大模型出現(xiàn)前后做一個(gè)分界線,可以認(rèn)為過去屬于弱人工智能,也就是針對(duì)特定的場(chǎng)景,特定的任務(wù),收集特定的數(shù)據(jù),訓(xùn)練一個(gè)模型,然后在特定場(chǎng)景解決問題。
像AlphaGO,能夠戰(zhàn)勝世界圍棋冠軍,但是無法直接用來解決醫(yī)療問題,解決無人駕駛問題等。
在大模型之后,弱人工智能開始向通用人工智能方向轉(zhuǎn)變,從專精尖的模型到通用模型,開啟了一個(gè)新的時(shí)代。由于能力還在不斷提升的過程中,所以我們還會(huì)覺得大模型依然不夠好用。

但是可以看到,過去七八十年每一次新的浪潮背后都有的本質(zhì)規(guī)律:模型參數(shù)、訓(xùn)練數(shù)據(jù)以及計(jì)算能力的提升,會(huì)帶來模型效果的巨大提升,這就是反復(fù)討論的Scaling Law。
最近關(guān)于Scaling Law是否失效,有很多爭(zhēng)論。
如果時(shí)間維度足夠長(zhǎng),會(huì)發(fā)現(xiàn)Scaling Law一直都在整個(gè)人工智能的發(fā)展歷程中不斷發(fā)揮作用。至于最近談到的Scaling Law已經(jīng)失效,一個(gè)很大原因是數(shù)據(jù)、算力,這些支撐Scaling Law發(fā)展的要素出現(xiàn)瓶頸。
智源研究院:國內(nèi)最早、國際同步布局大模型研發(fā)
通用人工智能時(shí)代的到來,對(duì)各行各業(yè)都有非常多的影響。
今年以來,大模型開始加速落地。
如果說過去兩年,中國依然在不斷地追基礎(chǔ)模型的能力,那么現(xiàn)階段國產(chǎn)模型的能力已經(jīng)接近GPT4了,足以支撐更多的應(yīng)用落地,因此可以預(yù)期在明年會(huì)有越來越多基于大模型的各種場(chǎng)景應(yīng)用的誕生。

智源研究院是第三次浪潮中在北京成立的一家非營利性質(zhì)的新型研發(fā)機(jī)構(gòu)。
在過去六年時(shí)間里建立起了一支非常頂尖的科研團(tuán)隊(duì),科研人員60%有博士學(xué)位,30%有海外教育研究背景和經(jīng)歷。正是因?yàn)橛羞@樣一支年輕有活力、有國際視野的團(tuán)隊(duì),智源研究院在國內(nèi)最早開始了大模型的研發(fā)。
而且智源研究院在2020年10月就成立了一支百余人的技術(shù)攻關(guān)團(tuán)隊(duì),專做大模型研發(fā)。并在2021年分別發(fā)布了悟道1.0、悟道2.0,2023年發(fā)布悟道3.0系列。

ChatGPT發(fā)布之后,產(chǎn)業(yè)界開始關(guān)注大模型,智源實(shí)際對(duì)國內(nèi)大模型創(chuàng)業(yè)公司做了非常大的貢獻(xiàn),包括孵化了一些公司,轉(zhuǎn)化了一些技術(shù)。就在今年智源大會(huì)上,頭部大模型公司對(duì)智源在過去這些年的貢獻(xiàn)也給予了充分肯定。
面向未來,大模型還遠(yuǎn)沒有到發(fā)展的盡頭。百模大戰(zhàn),很大程度上依然聚焦于大語言模型,Scaling Law在大語言模型上開始放緩的一個(gè)非常重要的原因是文本數(shù)據(jù)消耗殆盡。
ChatGPT后的o1,想要通過Post-Training(后訓(xùn)練)的方式進(jìn)一步激發(fā)大語言模型的智能。
面向未來看更多的技術(shù)發(fā)展趨勢(shì),可以看到除了文本數(shù)據(jù),還存在著大量的圖像、音頻、視頻等多模態(tài)數(shù)據(jù),這些數(shù)據(jù)如何進(jìn)一步激發(fā)大模型的智能,是一個(gè)非常重要的研究方向。
我們知道現(xiàn)階段有多模態(tài)理解的模型,也有多模態(tài)生成的模型。像Sora是Diffusion-Transformer的技術(shù)路線,多模態(tài)理解的模型基本上還是以大語言模型為核心,把不同模態(tài)的視覺信號(hào)等往語言模型上做映射。
我們認(rèn)為原生統(tǒng)一的多模態(tài)大模型才能更好支撐產(chǎn)業(yè)落地應(yīng)用,實(shí)現(xiàn)人工智能對(duì)世界的感知、理解、推理。如果與真實(shí)物理世界的硬件結(jié)合就是具身智能,與微觀世界的生命科學(xué)結(jié)合就是AI for Science,這一切最終都推動(dòng)整個(gè)AGI時(shí)代的到來。
過程中,智源研究院會(huì)針對(duì)一些產(chǎn)業(yè)界的共性問題,進(jìn)行科研層面的解決,以始終引領(lǐng)未來大模型的發(fā)展,支撐產(chǎn)業(yè)發(fā)展方向。
大模型一直有一個(gè)非常大的痛點(diǎn)就是幻覺。
去年,我們發(fā)布的通用向量模型被廣泛用在檢索增強(qiáng)中,在過去的兩年里,BGE已經(jīng)成為全球知名開源平臺(tái)Hugging face上120多萬個(gè)開源AI模型中下載量最高的模型(超過20%)。
不僅在社區(qū)里廣受歡迎,而且主流的云廠商平臺(tái)集成了BGE模型。因?yàn)槲覀兺耆_源,也允許商用。這就是智源研究院對(duì)產(chǎn)業(yè)界的支撐。

前沿探索中,智源一直在開展視覺和多模態(tài)方向的研究。
當(dāng)前階段,不同模態(tài)的模型依然采用不同的技術(shù)架構(gòu),它能夠在局部上展現(xiàn)出非常好的效果,但從長(zhǎng)期的技術(shù)發(fā)展或最終落地來講,還是會(huì)面臨很多挑戰(zhàn)。
所以我們一直都在挑戰(zhàn)一個(gè)終極形態(tài)的技術(shù)路線——將所有的模態(tài),包括理解和生成統(tǒng)一。
今年10月正式發(fā)布的Emu3原生多模態(tài)世界模型,我們將視覺信號(hào)和所有文本變成了token,通過類似大語言模型的訓(xùn)練架構(gòu)訓(xùn)練出了一個(gè)統(tǒng)一的原生多模態(tài)大模型。
視頻所展現(xiàn)出來的所有關(guān)于圖像的生成、圖像的理解,視頻的生成、視頻的理解都是基于一個(gè)基礎(chǔ)模型。具體來說,基于Autoregressive技術(shù)路線的Emu3 ,還能夠做視頻的續(xù)寫,以及對(duì)于復(fù)雜圖像、視頻的理解。
我們已經(jīng)將Emu3基礎(chǔ)模型以及微調(diào)的模型在開源社區(qū)開源,大家都可以使用。對(duì)比各種開源模型,可以發(fā)現(xiàn)Emu3在圖像生成、視頻生成以及圖像視頻的理解上都做得非常不錯(cuò)。
我們的技術(shù)報(bào)告和模型發(fā)布之后,國際同行也對(duì)Emu3給予了非常高的評(píng)價(jià)。
事實(shí)上,統(tǒng)一的多模態(tài)大模型對(duì)于最終落地各行各業(yè)有非常大的幫助。因?yàn)樵谡鎸?shí)的工業(yè)場(chǎng)景、醫(yī)療場(chǎng)景、教育場(chǎng)景,其實(shí)存在著大量的多模態(tài)數(shù)據(jù),不僅僅是文本的數(shù)據(jù)。當(dāng)人工智能模型進(jìn)入物理世界,跟硬件結(jié)合,更需要的還是多模態(tài)模型。
正在研發(fā)具身大模型
面向未來,我們正在研發(fā)具身智能一腦多體的具身大模型。
具體來說,具身大腦能夠更好地理解世界規(guī)律,跟環(huán)境交互,能夠做好規(guī)劃、決策的任務(wù);小腦能夠?qū)崿F(xiàn)跨不同的本體,進(jìn)行整個(gè)本體的控制,靈巧手能夠做更加精細(xì)化的操作。
在規(guī)劃決策上,o1能夠不斷反思思考,在具身智能上顯得尤其重要。我們有快系統(tǒng)和慢系統(tǒng),在真實(shí)世界交互中,對(duì)于某一個(gè)決策能夠反思,即執(zhí)行失敗了能糾正自己的行為非常重要。
當(dāng)然,我們也要意識(shí)到具身智能處在非常早期的階段,有非常多的技術(shù)依然亟待突破,尤其是泛化能力。比如泛化抓取、泛化操作,以及不同自由度操作的能力,包括具身導(dǎo)航的泛化導(dǎo)航能力等。
而智源在具身智能上也有一些進(jìn)展。
在今年兩會(huì)央視連線智源研究員時(shí),研究員說“我渴了”,機(jī)器人的機(jī)器手臂上的攝像頭疊加多模態(tài)大模型,它就能夠去理解、思考、抓取透明物體。

我們也將這樣的技術(shù)用在了所孵化的一家企業(yè)(北京銀河通用)的第一代機(jī)器人上,它能夠在零售場(chǎng)景下理解人類語言,做一些抓取工作。
當(dāng)然我們也深刻意識(shí)到,具身智能依然處在非常早期的階段,因此我們現(xiàn)在也在不斷加強(qiáng)和高校、院所、企業(yè)之間的合作,從數(shù)據(jù)采集到模型,包括大腦模型、小腦模型、端到端模型,到最終場(chǎng)景的落地應(yīng)用。
最后,非常歡迎各個(gè)企業(yè)、學(xué)校能跟智源研究院一起推動(dòng)具身智能技術(shù)的發(fā)展。
- 10億美元OpenAI股權(quán)兌換迪士尼版權(quán)!米老鼠救Sora來了2025-12-12
- 跳過“逐字生成”!螞蟻集團(tuán)趙俊博:擴(kuò)散模型讓我們能直接修改Token | MEET20262025-12-12
- 梁文鋒,Nature全球年度十大科學(xué)人物!2025-12-09
- 英偉達(dá)巧用8B模型秒掉GPT-5,開源了2025-12-06
相關(guān)閱讀

開源標(biāo)桿!最強(qiáng)中英雙語大模型來了,340億參數(shù),超越 Llama2-70B等所有開源模型
“全家桶”級(jí)開源,毫無保留


規(guī)格拉滿!Llama和Sora作者都來刷臉的中國AI春晚,還開源了一大堆大模型成果
大模型發(fā)展是時(shí)候參考前沿研究機(jī)構(gòu)的動(dòng)向和理解了

一塊顯卡理解一部電影,最新超長(zhǎng)視頻理解大模型出爐!“大海撈針”準(zhǔn)確率近95%,代碼已開源
智源研究院聯(lián)合多所高校帶來

具身智能大腦+首個(gè)SaaS開源框架,智源研究院刷新10項(xiàng)測(cè)評(píng)基準(zhǔn),加速群體智能新范式
加速具身智能技術(shù)從實(shí)驗(yàn)室走向真實(shí)場(chǎng)景





