谷歌新架構(gòu)突破Transformer超長上下文瓶頸!Hinton靈魂拷問:后悔Open嗎?
RNN的速度+Transformer的性能
魚羊 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
Transformer的提出者谷歌,剛剛上來給了Transformer梆梆就兩拳(doge)。
兩項(xiàng)關(guān)于大模型新架構(gòu)的研究一口氣在NeurIPS 2025上發(fā)布,通過“測試時訓(xùn)練”機(jī)制,能在推理階段將上下文窗口擴(kuò)展至200萬token。

兩項(xiàng)新成果分別是:
- Titans:兼具RNN速度和Transformer性能的全新架構(gòu);
- MIRAS:Titans背后的核心理論框架。
核心要解決的,就是Transformer架構(gòu)在處理超長上下文時的根本局限:計(jì)算成本會隨著序列長度的增加而猛增。
不得不說,從Nano Banana到Gemini 3 Pro,再到基礎(chǔ)研究方面的進(jìn)展,谷歌最近一段時間就是一個窮追猛打的架勢。
也難怪奧特曼要給OpenAI拉“紅色警報”了。
突破Transformer超長上下文瓶頸
現(xiàn)在AI領(lǐng)域已經(jīng)達(dá)成共識的是,Transformer雖好,但自注意力機(jī)制的效率問題正在日益凸顯:每個token都要“關(guān)注”其他所有token,導(dǎo)致計(jì)算量和內(nèi)存消耗與序列長度的平方成正比(O(N2))。
學(xué)界已經(jīng)探索了多種解決方案,比如線性循環(huán)網(wǎng)絡(luò)(RNNs)和狀態(tài)空間模型(SSMs)等。
這類模型通過將上下文壓縮到固定大小來實(shí)現(xiàn)快速線性擴(kuò)展。問題是,這種方法仍然無法充分捕捉超長序列中的豐富信息。
Titans + MIRAS,是谷歌提出的新架構(gòu)和理論藍(lán)圖,目的是將RNN的速度和Transformer的性能結(jié)合到一起。
其中Titans可以理解為具體的工具,而MIRAS則是理論框架。兩者共同推進(jìn)了測試時記憶的概念:
即模型在運(yùn)行過程中,無需專門的離線重新訓(xùn)練,就能通過整合更多信息來維持長期記憶。
本質(zhì)上,可以說這個新架構(gòu)的重點(diǎn),是重新定義Transformer的“記憶模式”,將其進(jìn)化為一種更強(qiáng)大的混合架構(gòu)。
Titans:在線將上下文擴(kuò)展至200萬
具體來說,Titans引入了一種新的神經(jīng)長期記憶模塊。
與傳統(tǒng)RNN中固定大小的向量或矩陣記憶不同,該模塊本質(zhì)上是一個在測試時動態(tài)更新權(quán)重的多層感知機(jī)(MLP)。
其獨(dú)特之處就在于,通常模型訓(xùn)練完后,權(quán)重就固定了,但在Titans中,這個記憶模塊在推理階段依然在更新。
MAC(Memory as Context)是Titans架構(gòu)的一種主要變體,設(shè)計(jì)思路是,將長期記憶作為一種額外的上下文信息,直接“喂”給注意力機(jī)制。
MAC并沒有改變注意力機(jī)制本身的計(jì)算方式,而是改變了注意力機(jī)制的輸入來源。它把從長期記憶中提取的信息,當(dāng)作是歷史信息的“摘要”,與當(dāng)前的短期輸入一起進(jìn)行處理。
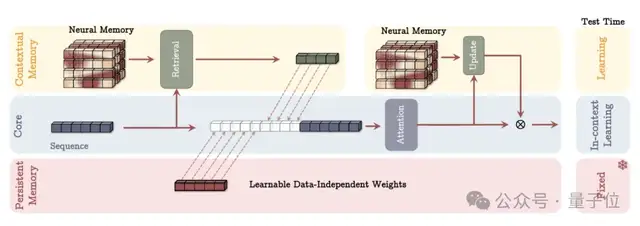
△MAC架構(gòu)
研究人員發(fā)現(xiàn),這個新的記憶模塊能顯著提升模型的表達(dá)能力,使其在不丟失重要上下文的情況下概括并理解大量信息。
更為重要的是,Titans并非被動地存儲數(shù)據(jù),而是能在輸入數(shù)據(jù)中,主動學(xué)習(xí)如何識別并保留連接各個token的重要關(guān)系和概念。其中的關(guān)竅是“意外”。
在人類心理學(xué)中,我們很容易忘記一些常規(guī)的、預(yù)期之內(nèi)的事情,但往往對“意外事件”印象深刻。
對于Titans也存在類似的情況。研究人員將其定義為“驚喜指標(biāo)”(surprise metric):指模型檢測到當(dāng)前記憶的內(nèi)容和新輸入內(nèi)容之間存在較大差異。
- 低意外度:比如新詞是“貓”,而模型的記憶狀態(tài)已經(jīng)預(yù)測到會有一個動物詞,那么梯度(意外度)就很低。這時模型僅將這個詞作為短期記憶來處理即可。
- 高意外度:如果模型的記憶狀態(tài)是正在總結(jié)一份嚴(yán)肅的財務(wù)報告,而新的輸入是香蕉皮的圖片(意外事件),則意外度將非常高。這表明新的輸入很重要或異常,需要優(yōu)先將其存儲到長期記憶模塊中。
這樣對“意外”的判斷使得Titans架構(gòu)能夠有選擇地更新長期記憶,從而保持快速和高效。
實(shí)驗(yàn)表明,Titans的MAC變體能夠有效將上下文窗口擴(kuò)展到200萬,并在“大海撈針”任務(wù)中保持高準(zhǔn)確率。
MIRAS:序列建模的統(tǒng)一框架
如果說Titans是跑車,那么MIRAS就是背后的核心引擎。
MIRAS核心目標(biāo)是讓模型在推理階段也能進(jìn)行學(xué)習(xí)。其獨(dú)特之處在于,它不把不同的架構(gòu)視為不同問題的解決方法,而是將其視為解決同一問題的不同途徑:
高效地將新信息與舊信息相結(jié)合,同時又不遺漏關(guān)鍵概念。
MIRAS將任意序列模型結(jié)構(gòu)為4個關(guān)鍵設(shè)計(jì)選擇:
- 內(nèi)存架構(gòu):存儲信息的結(jié)構(gòu)(如向量、矩陣,或Titans中的MLP)。
- 注意力偏差:模型優(yōu)化的內(nèi)部學(xué)習(xí)目標(biāo),決定模型優(yōu)先考慮的內(nèi)容。
- 保留門控(Retention Gate):即“遺忘機(jī)制”,用于平衡“學(xué)習(xí)新知識”與“保留舊記憶”。
- 記憶算法:用于更新記憶狀態(tài)的優(yōu)化算法。

現(xiàn)有的序列模型大多依賴均方誤差(MSE)或點(diǎn)積相似度來更新記憶。
MIRAS的另一個創(chuàng)新,是引入非歐幾里得目標(biāo)函數(shù),允許使用更復(fù)雜的數(shù)學(xué)懲罰機(jī)制。
谷歌的研究人員基于MIRAS,創(chuàng)建了三個特定的無注意力模型:
- YAAD:使用更溫和Huber Loss來處理錯誤,對異常值(如文檔中的拼寫錯誤)不敏感,魯棒性更強(qiáng)。
- MONETA:使用Generalized Norms(廣義范數(shù)),通過更嚴(yán)格的規(guī)則來管理注意力和遺忘,提升記憶穩(wěn)定性。
- MEMORA:強(qiáng)制記憶像概率圖一樣運(yùn)作,確保信息整合過程的受控和平衡。
實(shí)驗(yàn)結(jié)果顯示,基于Titans和MIRAS的模型性能優(yōu)于最先進(jìn)的線性循環(huán)模型(如Mamba 2),以及規(guī)模相近的Transformer基線模型。
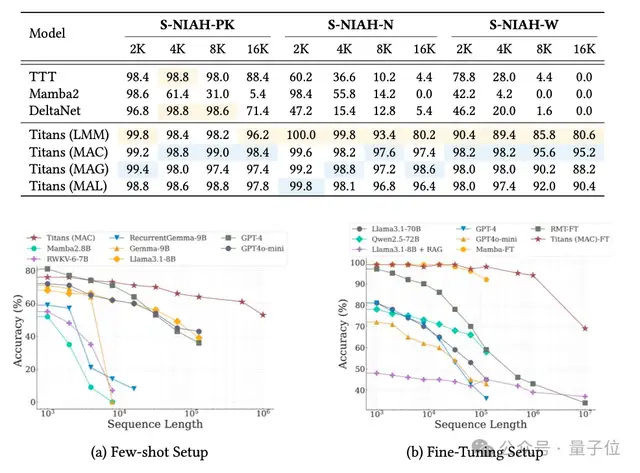
更顯著的優(yōu)勢在于,新架構(gòu)能夠處理極長上下文,在參數(shù)規(guī)模小得多的情況下,性能優(yōu)于GPT-4等大規(guī)模模型。
One More Thing
超越Transformer的探索還在繼續(xù),但不可否認(rèn)的是,Transformer依然是大模型時代的理論基石。
那么,曾經(jīng)一度在競爭中落后的谷歌,是否會后悔公開了Transformer的研究呢?
同樣是在NeurIPS 2025上,Jeff Dean回答了諾獎得主、圖靈獎得主Hinton提出的這個問題:
不,它對世界產(chǎn)生了巨大的積極影響。

這格局,谷谷人人又希希了。
參考鏈接:
[1]https://research.google/blog/titans-miras-helping-ai-have-long-term-memory
[2]https://arxiv.org/abs/2501.00663
[3]https://arxiv.org/abs/2504.13173
- 蘋果芯片主管也要跑路!庫克被曝出現(xiàn)健康問題2025-12-07
- 世界模型和具身大腦最新突破:90%生成數(shù)據(jù),VLA性能暴漲300%|開源2025-12-02
- 90后華人副教授突破30年數(shù)學(xué)猜想!結(jié)論與生成式AI直接相關(guān)2025-11-26
- 首位“80后”院士,來自北大數(shù)院2025-11-22
相關(guān)閱讀



谷歌大模型研究陷重大爭議:訓(xùn)練數(shù)據(jù)之外完全無法泛化?網(wǎng)友:AGI奇點(diǎn)推遲了
網(wǎng)友找出論文中更多關(guān)鍵卻被忽略的細(xì)節(jié),比如只做了GPT-2規(guī)模的試驗(yàn)等