
開源標桿!最強中英雙語大模型來了,340億參數,超越 Llama2-70B等所有開源模型
“全家桶”級開源,毫無保留
金磊 發自 凹非寺
量子位 | 公眾號 QbitAI
開源界最強的中英雙語大模型,悟道·天鷹 34B,來了!
有多強?一言蔽之:
中英綜合能力、邏輯推理能力等,全面超越 Llama2-70B和此前所有開源模型!
推理能力方面對話模型IRD評測基準僅次于 GPT4。

不僅模型夠大夠能打,而且還一口氣送上整套“全家桶”級豪華周邊。
能有如此大手筆的,正是中國大模型開源派先鋒——智源研究院。
而若是縱觀智源在數年來的大模型開源之道,不難發現它正在引領著一種新風向:
早在2021年就把全球最大語料庫公開,2022年最早前瞻布局FlagOpen大模型技術開源體系,連續推出了FlagEval評測體系、COIG數據集、BGE向量模型等全技術棧明星項目。
這一魄力正是來自智源非商業、非營利的中立研究機構定位,主打的就是一個“誠心誠意開源共創”。
據了解,Aquila2-34B 基座模型在22個評測基準的綜合排名領先,包括語言、理解、推理、代碼、考試等多個評測維度 。
一張圖來感受一下這個feel:
 △圖:Base 模型評測結果(詳細數據集評測結果見官方開源倉庫介紹)
△圖:Base 模型評測結果(詳細數據集評測結果見官方開源倉庫介紹)正如剛才提到的,北京智源人工智能研究院還非常良心地將開源貫徹到底,一口氣帶來開源全家桶:
- 全面升級Aquila2模型系列:Aquila2-34B/7B基礎模型,AquilaChat2-34B/7B對話模型,AquilaSQL“文本-SQL語言”模型;
- 語義向量模型BGE新版本升級:4大檢索訴求全覆蓋。
- FlagScale 高效并行訓練框架:訓練吞吐量、GPU 利用率業界領先;
- FlagAttention 高性能Attention算子集:創新支撐長文本訓練、Triton語言。

接下來,我們繼續深入了解一下這次的“最強開源”。
“最強開源”能力一覽
正如我們剛才提到的Aquila2-34B,它是此次以“最強開源”姿勢打開的基座模型之一,還包括一個較小體量的Aquila2-7B。
而它倆的到來,也讓下游的模型收益頗豐。
最強開源對話模型
在經指令微調得到了優秀的的AquilaChat2對話模型系列:
- AquilaChat2-34B:是當前最強開源中英雙語對話模型,在主觀+客觀綜合評測中全面領先 ;
- AquilaChat2-7B:也取得同量級中英對話模型中綜合性能最佳成績。
 △ SFT 模型評測結果(詳細數據集評測結果見官方開源倉庫介紹)
△ SFT 模型評測結果(詳細數據集評測結果見官方開源倉庫介紹)評測說明:
對于生成式對話模型,智源團隊認為需要嚴格按照“模型在問題輸入下自由生成的答案”進行評判,這種方式貼近用戶真實使用場景,因此參考斯坦福大學HELM[1]工作進行評測,該評測對于模型的上下文學習和指令跟隨能力要求更為嚴格。實際評測過程中,部分對話模型回答不符合指令要求,可能會出現“0”分的情況。
例如:根據指令要求,正確答案為“A”,如果模型生成為“B”或“答案是 A ”,都會被判為“0”分。
同時,業內也有其他評測方式,比如讓對話模型先拼接“問題+答案”,模型計算各個拼接文本的概率后,驗證概率最高的答案與正確答案是否一致,評測過程中對話模型不會生成任何內容而是計算選項概率。這種評測方式與真實對話場景偏差較大,因此在生成式對話模型評測中沒有采納。
[1] https://crfm.stanford.edu/helm/latest/
不僅如此,在對于大語言模型來說非常關鍵的推理能力上,AquilaChat2-34B的表現也非常的驚艷——
在IRD評測基準中排名第一,超越 Llama2-70B、GPT3.5等模型,僅次于 GPT4。
 △圖:SFT模型在IRD數據集上的評測結果
△圖:SFT模型在IRD數據集上的評測結果從種種成績上來看,無論是基座模型亦或是對話模型,Aquila2系列均稱得上是開源界最強了。
上下文窗口長度至16K
對于大語言模型來說,能否應對長文本輸入,并且在多輪對話過程中保持上下文的流暢度,是決定其體驗好壞的關鍵。
為了解決這一“苦大模型久矣”的問題,北京智源人工智能研究院便在20萬條優質長文本對話數據集上做了SFT,一舉將模型的有效上下文窗口長度擴展至16K。
而且不僅僅是長度上的提升,效果上更是得到了優化。
例如在LongBench的四項中英文長文本問答、長文本總結任務的評測效果上,就非常的明顯了——
AquilaChat2-34B-16K處于開源長文本模型的領先水平,接近GPT-3.5長文本模型。
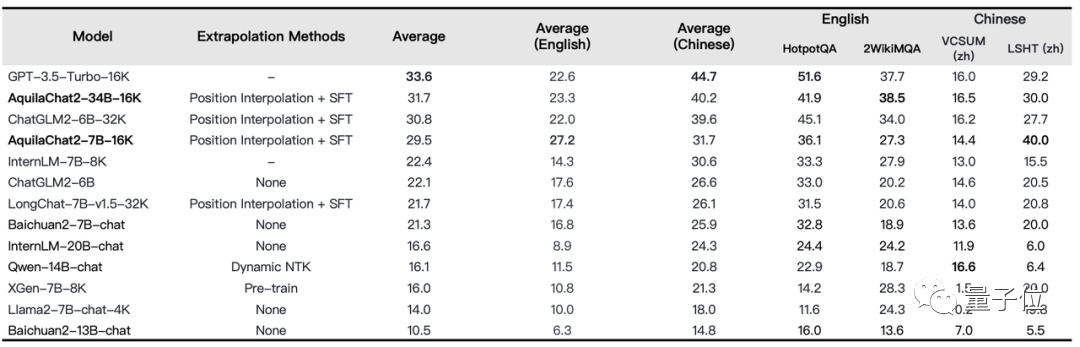 △圖:長文本理解任務評測
△圖:長文本理解任務評測除此之外,智源團隊對多個語言模型處理超長文本的注意力分布做了可視化分析,發現所有的語言模型均存在固定的相對位置瓶頸,顯著小于上下文窗口長度。
為此,智源團隊創新提出NLPE(Non-Linearized Position Embedding,非線性位置編碼)方法,在 RoPE 方法的基礎上,通過調整相對位置編碼、約束最大相對長度來提升模型外延能力。
在代碼、中英文Few-Shot Leaning、電子書等多個領域上的文本續寫實驗顯示,NLPE可以將4K的Aquila2-34B模型外延到32K長度,且續寫文本的連貫性遠好于Dynamic-NTK、位置插值等方法。
 △圖:NLPE與主流Dynamic-NTK外延方法在Base模型上的能力對比(ppl值越低越好)
△圖:NLPE與主流Dynamic-NTK外延方法在Base模型上的能力對比(ppl值越低越好)不僅如此,在長度為5K~15K的HotpotQA、2WikiMultihopQA等數據集上的指令跟隨能力測試顯示,經過 NLPE 外延的 AquilaChat2-7B(2K)準確率為 17.2%,而 Dynamic-NTK 外延的 AquilaChat2-7B 準確率僅為 0.4%。
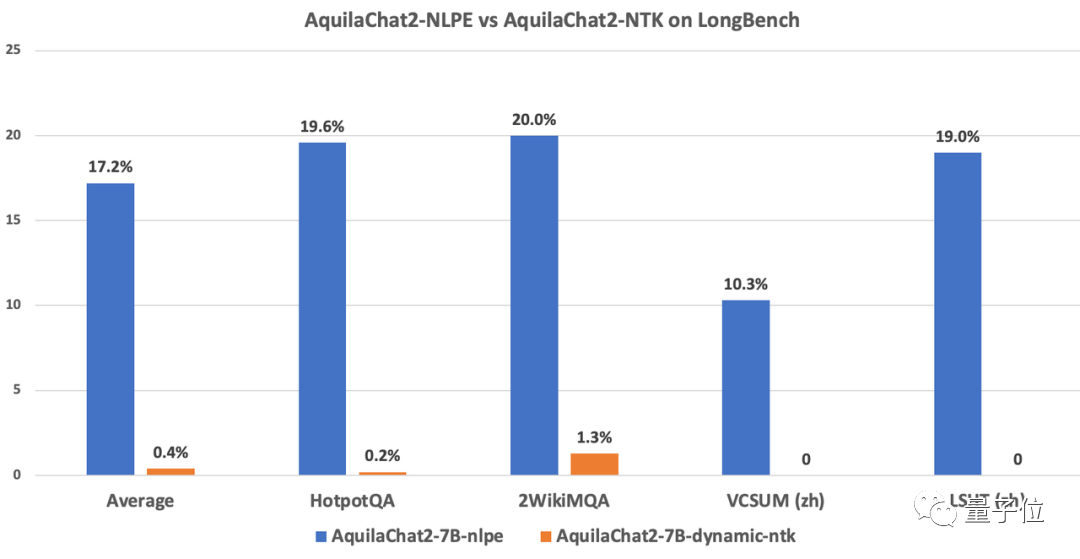 △圖:NLPE與主流Dynamic-NTK外延方法在SFT模型上的能力對比
△圖:NLPE與主流Dynamic-NTK外延方法在SFT模型上的能力對比各類真實應用場景均能hold住
“成績”好,只是檢驗大模型的標準之一,更重要的是“好用才是硬道理”。
這也就是大模型的泛化能力了,即使遇到沒有見過的問題,也能輕松應對。
為此,悟道·天鷹團隊通過三個真實應用場景驗證了Aquila2模型的泛化能力。
《我的世界》里打造強大智能體
《我的世界》這款游戲可以說是AI界檢驗技術的很好的試煉場。
它具有無限生成的復雜世界和大量開放的任務,為智能體提供了豐富的交互接口。
智源研究院與北京大學團隊便基于此,提出了在無專家數據的情況下高效解決 Minecraft 多任務的方法—— Plan4MC。
Plan4MC可以使用內在獎勵的強化學習訓練智能體的基本技能,使得智能體可以利用大語言模型AquilaChat2的推理能力進行任務規劃。
例如在下面的這段視頻中,便展示了智能體利用AquilaChat2進行自動完成多輪對話交互的效果。
將游戲“當前環境狀態”、“需要完成的任務”等信息輸入AquilaChat2模型,AquilaChat2 反饋給角色“下一步使用什么技能”等決策信息,最終完成了在《我的世界》中設定的任務“伐木并制作工作臺放在附近”的任務。

通過Aquila2+BGE2鏈接向量數據庫
向量數據庫近年來在大模型圈里成為了香餑餑,但在面對復雜、需要深度理解問題時,能力上還是略顯捉襟見肘。
為此,智源研究院便將Aqiula2和自研的開源語義向量模型BGE2做了結合,徹底解鎖了一些僅基于傳統向量庫的檢索方法不能解決的復雜檢索任務。
例如在下面的這個例子中,我們可以明顯看到,在處理“檢索某個作者關于某個主題的論文”、“針對一個主題的多篇論文的生成總結文本”這樣的任務,會變得非常絲滑。

最優“文本-SQL語言”生成模型
很多用戶在處理數據庫查詢等任務時,對于SQL語言可謂是頭疼不已。
若是能用我們常用的大白話來進行操作,豈不美哉?
現在,這種便捷的方式已經可以實現了——AquilaSQL。
在實際應用場景中,用戶還可以基于AquilaSQL進行二次開發,將其嫁接至本地知識庫、生成本地查詢 SQL,或進一步提升模型的數據分析性能,讓模型不僅返回查詢結果,更能進一步生成分析結論、圖表等。
例如在處理下面這個復雜查詢任務時,現在只需要說一句自然語言即可:
從包含汽車銷量(car_sales)、汽車顏色(car_color)的兩個數據表中篩選銷量大于100并且顏色為紅色的汽車。

而且AquilaSQL的“成績”同樣非常亮眼。
在經過SQL語料的繼續預訓練和SFT 兩階段訓練,最終以67.3%準確率超過“文本-SQL語言生成模型”排行榜 Cspider 上的SOTA模型。
而未經過SQL語料微調的 GPT4模型準確率僅為 30.8%。
還有全家桶級的開源
正如我們前文提到的,智源研究院對開源這事向來主打的就是徹徹底底。
這一次在大模型升級之際,智源研究院同樣是毫無保留地把一系列包括算法、數據、工具、評測方面的明星項目都開源了出來。
據了解,Aquila2系列模型不僅全面采用商用許可協議,允許公眾廣泛應用于學術研究和商業應用。
接下來,我們便來速覽一下這些開源全家桶。
高效并行訓練框架FlagScale
FlagScale 是 Aquila2-34B 使用的高效并行訓練框架,可以提供一站式語言大模型的訓練功能。
智源團隊將 Aquila2 模型的訓練配置、優化方案和超參數通過 FlagScale 項目分享給大模型開發者,在國內首次完整開源訓練代碼和超參數。
FlagScale 基于 Megatron-LM 擴展而來,提供了一系列功能增強,包括分布式優化器狀態重切分、精確定位訓練問題數據以及參數到Huggingface轉換等。
經過實測,Aquila2 訓練吞吐量和 GPU 利用率均達到業界領先水平。
 △圖:FlagScale 訓練吞吐量與GPU利用率(數據來源和估算公式見文末)
△圖:FlagScale 訓練吞吐量與GPU利用率(數據來源和估算公式見文末)據了解,FlagScale在未來還將繼續保持與上游項目 Megatron-LM 最新代碼同步,引入更多定制功能,融合最新的分布式訓練與推理技術以及主流大模型、支持異構AI硬件,力圖構建一個通用、便捷、高效的分布式大模型訓練推理框架,滿足不同規模和需求的模型訓練任務。
FlagAttention高性能Attention開源算子集
FlagAttention 是首個支持長文本大模型訓練、使用 Triton語言開發的高性能Attention開源算子集,針對大模型訓練的需求,對 Flash Attention 系列的 Memory Efficient Attention 算子進行擴展。
目前已實現分段式 Attention 算子——PiecewiseAttention。
PiecewiseAttention主要解決了帶旋轉位置編碼 Transformer 模型(Roformer)的外推問題,它所具備的特點可以總結為:
通用性:對使用分段式計算 Attention 的模型具有通用性,可以輕松遷移至 Aquila 之外的大語言模型。
易用性:FlagAttention 基于 Triton 語言實現并提供 PyTorch 接口,構建和安裝過程相比 CUDA C 開發的 Flash Attention 更加便捷。
擴展性:同樣得益于 Triton 語言,FlagAttention 算法本身的修改和擴展門檻較低,開發者可便捷地在此之上拓展更多新功能。
未來,FlagAttention項目將繼續針對大模型研究需求,支持其他功能擴展的 Attention 算子,進一步優化算子性能,并適配更多異構AI硬件。
BGE2 新一代語義向量模型
新一代BGE語義向量模型,也將隨 Aquila2 同步開源。
BGE2 中的 BGE – LLM Embedder 模型集成了“知識檢索”、“記憶檢索”、“示例檢索”、“工具檢索”四大能力。
它首次實現了單一語義向量模型對大語言模型主要檢索訴求的全面覆蓋。
結合具體的使用場景,BGE – LLM Embedder將顯著提升大語言模型在處理知識密集型任務、長期記憶、指令跟隨、工具使用等重要領域的表現。
……
那么對于如此徹底的“最強開源”,你心動了嗎?
One More Thing
智源研究院會在10月28日至29日舉辦新一期大模型前沿技術講習班,9位主力研究員會詳細介紹 FlagOpen 的近期進展和落地實踐。
感興趣的小伙伴也可以碼住了。
Aquila2 模型全系開源地址:
https://github.com/FlagAI-Open/Aquila2
https://model.baai.ac.cn/
https://huggingface.co/BAAI
AquilaSQL 開源倉庫地址:
https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila/Aquila-sql
FlagAttention 開源代碼倉庫:
https://github.com/FlagOpen/FlagAttention
BGE2 開源地址
paper: https://arxiv.org/pdf/2310.07554.pdf
model: https://huggingface.co/BAAI/llm-embedder
repo: https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder
_________________________
LLAMA2吞吐量估算公式:total tokens / (total GPU hours * 3600) ,根據Llama 2: Open Foundation and Fine-Tuned Chat Models論文:1)7B的total tokens為2.0 T, total GPU hours 為184320,代入公式得3014 Tokens/sec/GPU;2)34B的total tokens為2.0 T, total GPU hours 為1038336,代入公式得535 Tokens/sec/GPU。
- 共推空天領域智能化升級!趨境科技與金航數碼強強聯手2025-12-09
- Ilya剛預言完,世界首個原生多模態架構NEO就來了:視覺和語言徹底被焊死2025-12-06
- 看完最新國產AI寫的公眾號文章,我慌了!2025-12-08
- 給機器人打造動力底座,微悍動力發布三款高功率密度關節模組2025-12-08
相關閱讀










