Ilya剛預言完,世界首個原生多模態架構NEO就來了:視覺和語言徹底被焊死
1/10數據追平GPT-4V
金磊 發自 凹非寺
量子位 | 公眾號 QbitAI
當Ilya Sutskever最近公開宣稱“純靠Scaling Law的時代已經結束”,并斷言“大模型的未來不在于單純的規模更大,而是要架構變得更聰明”時,整個AI界都意識到了一場范式轉移正在發生。
因為過去幾年,行業似乎沉迷于用更多數據、更大參數、更強算力堆出更強的模型,但這條路正逼近收益遞減的臨界點。
Ilya和LeCun等頂尖AI大佬不約而同地指出:真正的突破,必須來自架構層面的根本性創新,而非對現有Transformer流水線的修修補補。
就在如此關鍵節點,一個來自中國研究團隊的新物種橫空出世:
全球首個可大規模落地的開源原生多模態架構(Native VLM),名曰NEO。

△《黑客帝國》主角Neo,圖片由AI生成
要知道,此前主流的多模態大模型,例如我們熟悉的GPT-4V、Claude 3.5等,它們的底層邏輯本質上其實玩的就是拼接。
什么意思呢?
就是將一個預訓練好的視覺編碼器(比如 ViT)通過一個小小的投影層,嫁接到一個強大的大語言模型上。
這種模塊化的方式雖說是實現了多模態,但視覺和語言始終是兩條平行線,只是在數據層面被粗暴地拉到了一起。
而這項來自商湯科技與南洋理工大學等高校的聯合研究,要做的就是從根上顛覆這一切。

在NEO這里,大模型不僅能看、會說,而且天生就懂視覺和語言是一體兩面的道理。
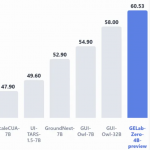
更驚人的一組數據是,憑借這種原生多模態架構,NEO僅用十分之一的訓練數據,就在多項關鍵評測中追平甚至超越了那些依賴海量數據和復雜模塊堆砌的旗艦級對手!
那么NEO到底是怎么如何做到的,我們繼續往下看。
為什么非得是原生架構?
在深入了解原理之前,我們還需要理解多模態當前的現狀。
正如我們剛才提到的,當前主流的模塊化架構,實則存在三大難以跨越的技術鴻溝。
首先是效率鴻溝。
模塊化模型的訓練流程極其復雜,通常分為三步:先分別預訓練視覺編碼器和語言模型,再通過一個對齊階段讓二者學會溝通,最后可能還需要指令微調。
這個過程不僅耗時耗力,成本高昂,而且每個階段都可能引入新的誤差和不一致性;視覺和語言的知識被割裂在不同的“房間”里,需要不斷“傳紙條”才能勉強協作。
其次是能力鴻溝。
視覺編碼器在設計之初就帶有強烈的歸納偏置。比如,它通常要求輸入圖像必須是固定的分辨率(如224×224),或者必須被強行展平成一維的token序列。
這種處理方式,對于理解一幅畫的整體構圖或許足夠,但在面對需要捕捉細微紋理、復雜空間關系或任意長寬比的場景(比如一張長圖、一張工程圖紙)時,就顯得力不從心。
因為模型看到的,只是一個被過度簡化和結構化的骨架。
最后是融合鴻溝。
那個連接視覺和語言的映射,幾乎都是停留在簡單的表層,無法觸及深層次的語義對齊。這就導致了模型在處理需要細粒度視覺理解的任務時常常捉襟見肘。
例如,讓它描述一張復雜圖表,它可能會混淆圖例和數據;讓它理解一個帶有空間指示的指令,比如“把左邊第二個紅蘋果放到右邊籃子里”,它可能會搞錯左右或數量。
究其根本,是因為在模型內部,視覺信息和語言信息從未被放在同一個語義空間里進行真正的、深度融合的推理。
也正因如此,NEO背后研究團隊從第一性原理出發,直接打造一個視覺與語言從誕生之初就血脈相連的統一模型——
這個模型不再有視覺模塊和語言模塊的區分,只有一個統一的、專為多模態而生的大腦。
回顧AI發展史,從RNN到Transformer,每一次真正的飛躍都源于架構層面的根本性創新。
而過去幾年,行業陷入了“唯規模論”的路徑依賴,直到今天,以Ilya為代表的一批頂尖研究者才集體發出警示:Transformer架構的固有局限已日益凸顯,僅靠堆疊算力和數據,無法通往真正的通用智能。
NEO的誕生,恰逢其時。它用一個簡潔而統一的原生架構,有力地證明了:下一代AI的競爭力,關鍵在于架構有多聰明。
NEO背后的三大原生技術
NEO 的核心創新,體現在三個底層技術維度上,它們共同構建了模型的原生能力。

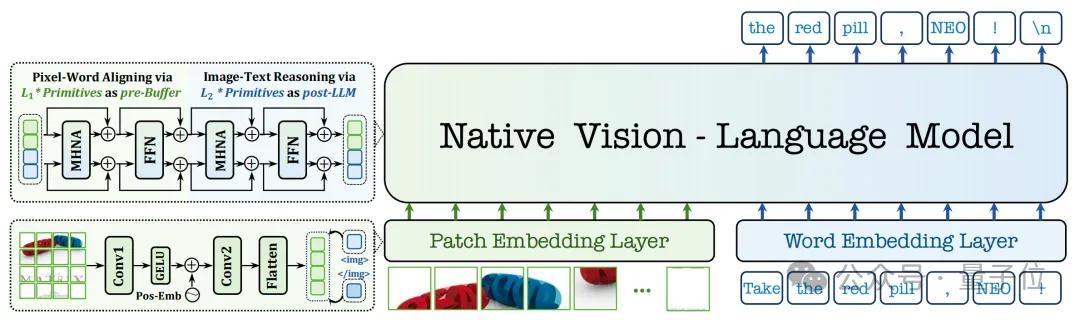
第一,原生圖塊嵌入?(Native Patch Embedding)。
傳統模型常預先采用離散的tokenizer或者連接vision encoder壓縮圖像信息或語義token。
NEO則是直接摒棄了這一步,它設計了一個輕量級的圖塊嵌入層,通過兩層卷積神經網絡,直接從像素出發,自底向上地構建一個連續的、高保真的視覺表征。
這就像讓AI學會了像人類一樣,用眼睛直接感受光影和細節,而不是先看一張被馬賽克化的抽象圖。
這種設計讓模型能更精細地捕捉圖像中的紋理、邊緣和局部特征,從根本上突破了主流模型的圖像建模瓶頸。
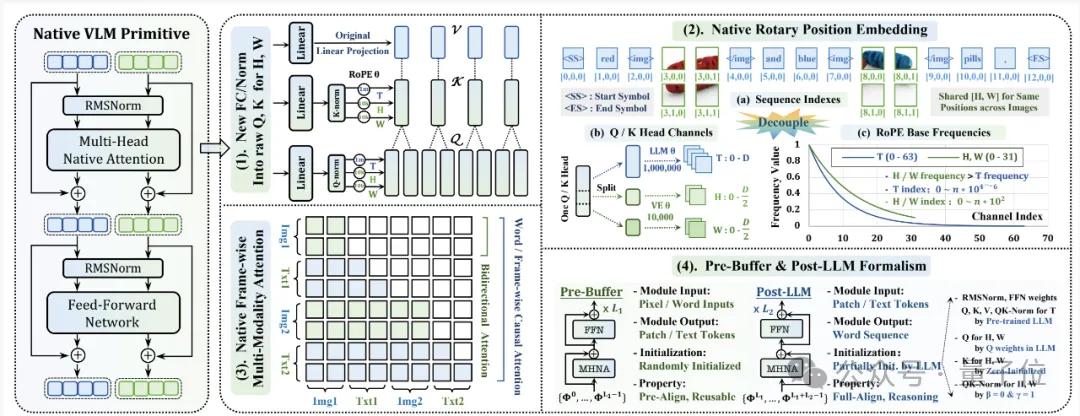
第二,原生三維旋轉位置編碼?(Native-RoPE)。
位置信息對于理解任何序列都至關重要。文本是一維的,而圖像是二維的,視頻更是三維的(時空)。傳統模型要么給所有模態用同一個一維位置編碼,要么簡單地拼接,這顯然無法滿足不同模態的天然結構。
NEO的Native-RoPE創新性地為時間(T)、高度(H)、寬度(W)三個維度分配了不同的頻率:視覺維度(H, W)使用高頻,以精準刻畫局部細節和空間結構;文本維度(T)兼顧高頻和低頻,同時處理好局部性和長距離依賴。
更巧妙的是,對于純文本輸入,H和W的索引會被置零,完全不影響原有語言模型的性能。
這相當于給AI裝上了一個智能的、可自適應的時空坐標系,不僅能精準定位圖像中的每一個像素,也為無縫擴展到視頻理解和3D交互等復雜場景鋪平了道路。
第三,原生多頭注意力?(Native Multi-Head Attention)。
注意力機制是大模型的思考方式,在傳統模塊化模型里,語言模型的注意力是因果的(只能看到前面的詞),而視覺編碼器的注意力是雙向的(能看到所有像素)。
NEO采取的方法,則是在一個統一的注意力框架下,讓這兩種模式并存。
當處理文本token時,它遵循標準的自回歸因果注意力;而當處理視覺token時,它則采用全雙向注意力,讓所有圖像塊之間可以自由地交互和關聯。
這種“左右腦協同工作”的模式,極大地提升了模型對圖像內部空間結構的理解能力,從而能更好地支撐復雜的圖文交錯推理,比如理解“貓在盒子上方”和“貓在盒子里”的細微差別。
除了這三大核心,NEO還配套了一套名為Pre-Buffer & Post-LLM的雙階段融合訓練策略。
在預訓練初期,模型會被臨時劃分為兩部分:一個負責視覺語言深度融合的Pre-Buffer和一個繼承了強大語言能力的Post-LLM。
前者在后者的引導下,從零開始高效地學習視覺知識,建立初步的像素-詞語對齊;并且隨著訓練的深入,這個劃分會逐漸消失,整個模型融為一個端到端的、不可分割的整體。
這種策略便巧妙地解決了原生架構訓練中如何在不損害語言能力的前提下學習視覺的難題。
十分之一的數據,追平旗艦
紙上談兵終覺淺,實測數據見分曉。接下來我們就來看下NEO在實測中的表現。
縱觀結果,最直觀的體現就是數據效率——
NEO僅使用了3.9億個圖像文本對進行訓練,這個數量級僅僅是同類頂級模型所需數據的十分之一!
它無需依賴龐大的視覺編碼器或海量的對齊數據,僅憑其簡潔而強大的原生架構,就在多項視覺理解任務上追平了 Qwen2-VL、InternVL3等頂級模塊化旗艦模型。
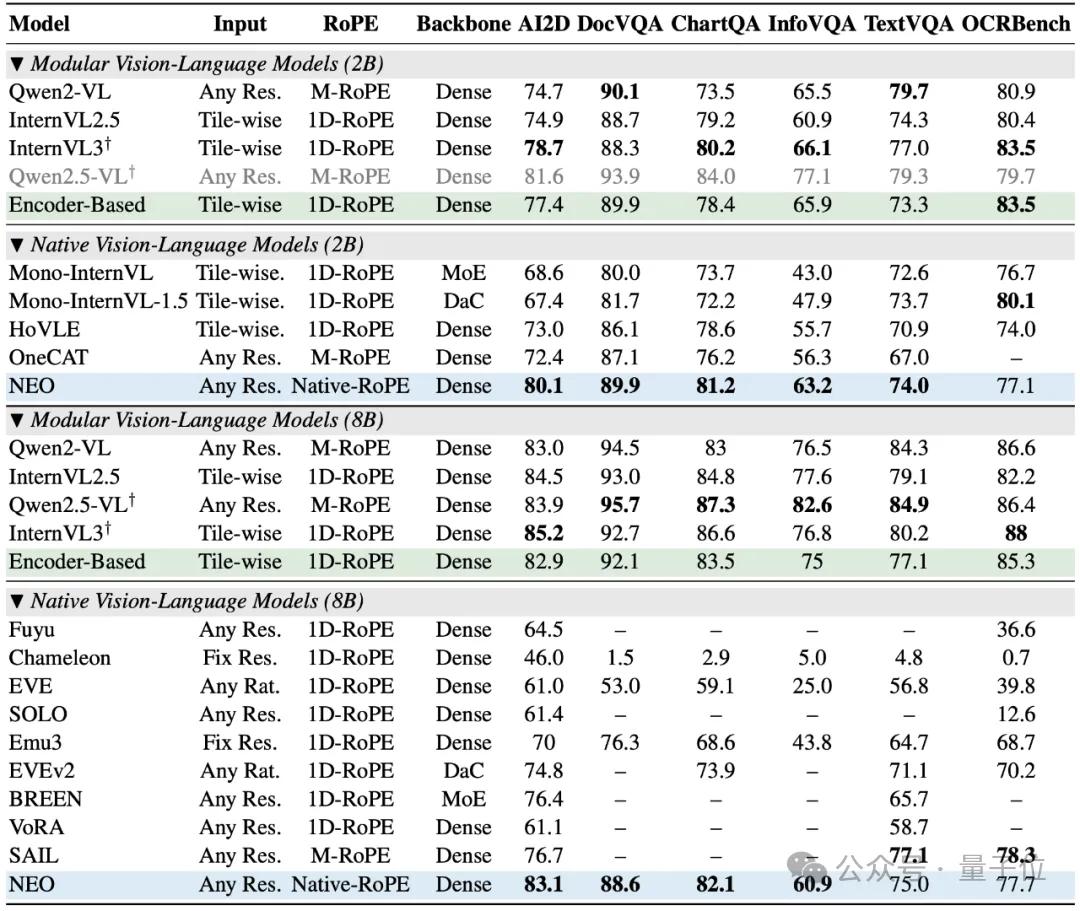
在權威的評測榜單上,NEO的表現也是較為亮眼。
在MMMU(多學科綜合理解)、MMBench(綜合多模態能力)、MMStar(空間與科學推理)、SEED-I(視覺感知)以及POPE(衡量模型幻覺程度)等多個關鍵基準測試中,NEO均取得了高分,展現出優于其他原生VLM的綜合性能,真正做到了精度無損。

尤其值得注意的是,當前NEO在2B到8B的中小參數規模區間內,展現出了較高的推理性價比。
對于動輒數十B甚至上百B的大模型來說,這些中小模型似乎只是玩具。但正是這些模型,才是未來在手機、機器人、智能汽車等邊緣設備上落地的關鍵。
NEO不僅在這些規模上實現了精度與效率的雙重躍遷,更大幅降低了推理成本。
這意味著,強大的多模態視覺感知能力,將不再是云端大模型的專屬,而是可以真正普及到每一個終端設備上。
如何評價NEO?
最后,我們還需要討論一個問題:NEO有什么用?
從我們上述的內容不難看出,NEO真正的價值,不僅在于性能指標的突破,更在于它為多模態AI的演進指明了一條新路徑。
它原生一體化的架構設計,從底層打通了視覺與語言的語義鴻溝,天然支持任意分辨率圖像、長圖文交錯推理,并為視頻理解、3D空間感知乃至具身智能等更高階的多模態交互場景預留了清晰的擴展接口。
這種為融合而生的設計哲學,可以讓它成為構建下一代通用人工智能系統的理想底座。
更關鍵的是,商湯已開源基于NEO架構的2B與9B兩種規格模型,釋放出強烈的共建信號。
這一舉措有望推動整個開源社區從當前主流的模塊拼接范式,向更高效、更統一的原生架構遷移,加速形成新一代多模態技術的事實標準。
與此同時,NEO在中小參數規模下展現出的性價比,正在打破大模型壟斷高性能的固有認知。
它大幅降低了多模態模型的訓練與部署門檻,使得強大的視覺理解能力不再局限于云端,而是可以真正下沉到機器人、智能汽車、AR/VR 眼鏡、工業邊緣設備等對成本、功耗和延遲高度敏感的終端場景。
從這個角度看,NEO不僅是一個技術模型,更是通向下一代普惠化、終端化、具身化AI基礎設施的關鍵雛形。
更重要的是,NEO的出現,為當前迷茫的AI界提供了一個清晰而有力的答案。
在Ilya等人共同指出行業亟需新范式的當下,NEO以其徹底的原生設計理念,成為了“架構創新重于規模堆砌”這一新趨勢的首個成功范例。
它不僅重新定義了多模態模型的構建方式,更向世界宣告:AI的下一站,是回歸到對智能本質的探索,通過根本性的架構創新,去構建能真正理解并融通多維信息的通用大腦。
這一步,是中國團隊對全球AI演進方向的一次關鍵性貢獻。或如預言,這正是通往下一代AI的必經之路。
- 云計算一哥10分鐘發了25個新品!Kimi和MiniMax首次上桌2025-12-03
- 前端沒死,AI APP正在返祖2025-12-02
- 華為新架構砍了Transformer大動脈!任意模型推理能力原地飆升2025-12-06
- 記憶張量 × 商湯大裝置:國產 GPGPU 推理成本反超 A100!2025-12-04