
規(guī)格拉滿!Llama和Sora作者都來刷臉的中國(guó)AI春晚,還開源了一大堆大模型成果
大模型發(fā)展是時(shí)候參考前沿研究機(jī)構(gòu)的動(dòng)向和理解了
魚羊 明敏 發(fā)自 凹非寺
量子位 | 公眾號(hào) QbitAI
本周國(guó)內(nèi)最受關(guān)注的AI盛事,今日啟幕。
活動(dòng)規(guī)格之高,沒有哪個(gè)關(guān)心AI技術(shù)發(fā)展的人能不為之吸引——
Sora團(tuán)隊(duì)負(fù)責(zé)人Aditya Ramesh與DiT作者謝賽寧同臺(tái)交流,李開復(fù)與張亞勤爐邊對(duì)話,Llama2/3作者Thomas Scialom,王小川、楊植麟等最受關(guān)注AI創(chuàng)業(yè)者……也都現(xiàn)場(chǎng)亮相。

一年一度,中國(guó)“AI春晚”智源大會(huì)如約而至,依然AI大佬密度拉滿,依然干貨成果滿滿當(dāng)當(dāng)。
從學(xué)術(shù)向的“語言智能與視覺智能融合創(chuàng)造世界模擬器”,到產(chǎn)業(yè)向的“大模型價(jià)格戰(zhàn)有何影響”,活動(dòng)開啟第一個(gè)上午,頂級(jí)AI學(xué)者、專家們的觀點(diǎn)交鋒已經(jīng)讓線上線下觀眾直呼過癮。

不僅如此,主辦方智源研究院,還拋出了一籮筐重磅新進(jìn)展,開源開放的那種:
- 萬億稠密模型TeleFLM核心技術(shù)、訓(xùn)練細(xì)節(jié)、52B版本;
- 原生多模態(tài)大模型Emu 3最新成果,以及輕量級(jí)圖文多模態(tài)模型Bunny的參數(shù)、訓(xùn)練代碼、訓(xùn)練數(shù)據(jù);
- 千萬級(jí)高質(zhì)量指令微調(diào)數(shù)據(jù)集InfinityInstruct;
- ……
大模型趨勢(shì)以來,創(chuàng)業(yè)公司大廠的動(dòng)向吸引了諸多關(guān)注。
但更回歸技術(shù)本身,當(dāng)下大模型發(fā)展還需要關(guān)注哪些方面?是時(shí)候參考研究機(jī)構(gòu)的動(dòng)向和理解了。
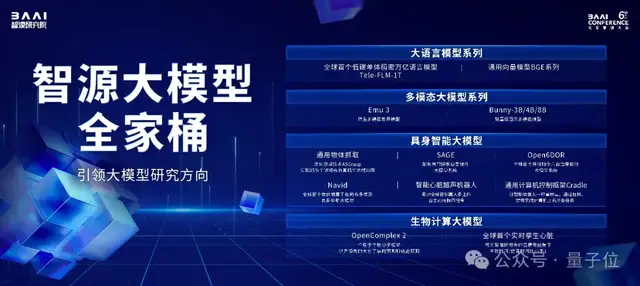
智源大模型“全家桶”發(fā)布
智源研究院帶來的最新發(fā)布主要有大模型進(jìn)展以及底層算力基座。
智源大模型“全家桶”由4部分組成:
- 智源語言大模型
- 智源多模態(tài)大模型
- 智源具身大模型
- 智源生物計(jì)算大模型
首先在大語言模型方面,智源表示不會(huì)重復(fù)造輪子,最新發(fā)布的成果主要面向產(chǎn)業(yè)界正面臨的共同難點(diǎn),比如算力缺乏問題。
智源與中國(guó)電信人工智能研究院(TeleAI)聯(lián)合研發(fā)了基于生長(zhǎng)技術(shù)訓(xùn)練的全球首個(gè)低碳單體稠密萬億語言模型。

盡管模型參數(shù)規(guī)模達(dá)到萬億級(jí)別,但訓(xùn)練實(shí)際只用了112臺(tái)A800,這相當(dāng)于業(yè)界普通訓(xùn)練方案9%的算力資源。
通過優(yōu)越超參預(yù)測(cè)技術(shù),訓(xùn)練全過程零調(diào)整、零重試。
目前Tele-FLM 1TB版本還在訓(xùn)練中,中間版Tele-FLM 52B已開源。
評(píng)估結(jié)果顯示,在中文方面,Tele-FLM的BPB曲線優(yōu)于Llama3-70B。英文方面,其BPB評(píng)測(cè)接近Llama3-70B,優(yōu)于Llama2-70B。
之后,團(tuán)隊(duì)將開源1TB版本,以及訓(xùn)練技術(shù)細(xì)節(jié)以及l(fā)oss曲線。以期為開源社區(qū)提供一個(gè)優(yōu)秀的稠密萬億模型的初始參數(shù)版本,避免萬億參數(shù)模型早期難以收斂等問題。
同時(shí),智源對(duì)基于該基座模型訓(xùn)練出的對(duì)話模型Tele-FLM-Chat(52B)進(jìn)行評(píng)測(cè)。
AlignBench評(píng)測(cè)顯示,它已達(dá)到GPT-4中文語言能力的96%,總體能力可達(dá)GPT-4的80%。現(xiàn)在已在ModelScope上可體驗(yàn)。

算力之外,大模型應(yīng)用落地的另一大挑戰(zhàn)是幻覺問題。
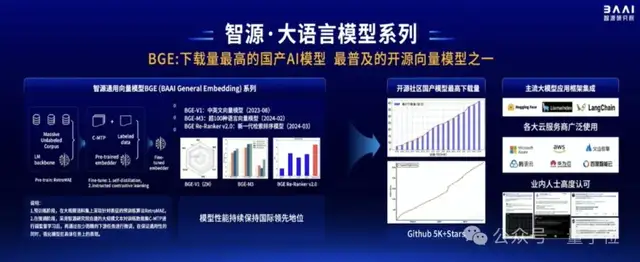
在這方面,智源帶來了通用向量模型BGE(BAAI General Embedding)。
該系列模型如今已是全球范圍內(nèi)下載量最高的國(guó)產(chǎn)AI模型,也是最普及的開源向量模型之一。
它基于無監(jiān)督預(yù)訓(xùn)練和多階段對(duì)比學(xué)習(xí),構(gòu)建了多語言關(guān)聯(lián)文本數(shù)據(jù)集C-MTP。
從去年8月發(fā)布至今,BGE模型得到了全球主流應(yīng)用大模型框架的集成,包括Hugging Face、LlamaIndex等。如Azure、AWS、火山引擎、騰訊云、華為云、百度智能云等主流云廠商,也都集成了BGE模型,對(duì)外提供商用。
其次,智源聚焦多模態(tài)領(lǐng)域,帶來了最新進(jìn)展——Emu3。
去年7月,智源研究院發(fā)布生成式多模態(tài)模型Emu,12月迭代至Emu2。
最新發(fā)布的Emu3采用自回歸技術(shù)路徑,將圖像、視頻、文字共同訓(xùn)練,統(tǒng)一實(shí)現(xiàn)了圖像、視頻、文字的輸入和輸出,并且具備更多模態(tài)可擴(kuò)展性。
它具備圖像生成能力、視頻生成能力:

并且可以理解圖像和視頻內(nèi)容:

目前,Emu3還在持續(xù)訓(xùn)練中,在經(jīng)過安全評(píng)估后會(huì)逐步開源。Emu1和Emu2已經(jīng)開源。
另外在多模態(tài)方面,智源還帶來了一個(gè)輕量級(jí)圖文模型:Bunny-3B/4B/8B。
該模型采用靈活架構(gòu),可基于不同視覺編碼器,如EVA-CLIP、SigLIP;也能基于不同的語言基座模型,比如Phi、StableLM等。
Bunny的模型、數(shù)據(jù)、代碼將全部開源。

第三,面向具身智能的終局,智源還帶來了一個(gè)端到端具身導(dǎo)航大模型,并已在人形機(jī)器人上應(yīng)用。
NaVid是世界首個(gè)端到端基于視頻的多模態(tài)具身大模型,它實(shí)現(xiàn)了“輸入視頻和語言,輸出動(dòng)作”。它無需離線建圖,是純視覺、純Sim2Real方案,能在虛擬世界中訓(xùn)練,在現(xiàn)實(shí)世界中直接泛化。

另外智源也關(guān)注了具身智能幾個(gè)關(guān)鍵點(diǎn)。
比如通用抓取模型ASGrasp。通過在仿真系統(tǒng)內(nèi)構(gòu)建千萬量級(jí)場(chǎng)景以及超過10億抓取數(shù)據(jù),實(shí)現(xiàn)了抓取技術(shù)顯著提升,在工業(yè)級(jí)真機(jī)上能夠?qū)崿F(xiàn)超過95%的抓取成功率,打破世界紀(jì)錄,該成果已被ICRA 2024接收。

SAGE模型是一個(gè)操作系統(tǒng)大模型,基于三維視覺小模型和圖文大模型,它能讓機(jī)器人在操作失敗后進(jìn)行思考,就像人一樣,然后重新規(guī)劃動(dòng)作,進(jìn)而完成任務(wù)。該模型也被ICRA 2024接收。
Open6DOR則是全球首個(gè)開放指令六自由度取放大模型系統(tǒng),它能讓機(jī)器人既關(guān)注物體的位置,也考慮物體的姿態(tài),從而讓抓取更有效。
基于如上成果,智源的具身智能已經(jīng)可以理解人類的指令并進(jìn)行對(duì)話、執(zhí)行任務(wù),比如在聽到人類說“我渴了/我餓了”之后,它會(huì)遞上可樂或橘子。

在實(shí)際落地方面,智源還與清華大學(xué)301研究院帶來了全球首創(chuàng)智能心臟超聲機(jī)器人。
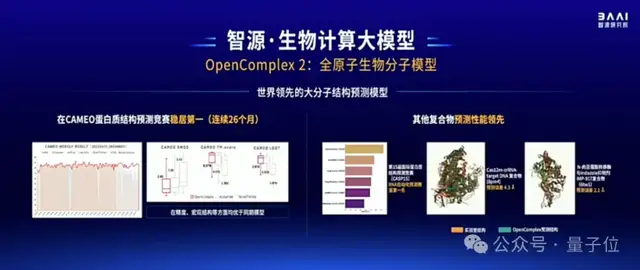
最后,在生物計(jì)算方面,智源發(fā)布了OpenComplex2全原子生物分子模型。
這是一個(gè)decoder-only模型,它基于生成式AI,能在原子層面對(duì)RNA、DNA等小分子的結(jié)構(gòu)和相互關(guān)系進(jìn)行預(yù)測(cè),精度可達(dá)超算水平。
在CAMEO蛋白質(zhì)結(jié)構(gòu)預(yù)測(cè)競(jìng)賽中,OpenComplex已經(jīng)連續(xù)26個(gè)月穩(wěn)居第一,在精度和宏觀結(jié)構(gòu)等方面均優(yōu)于同期模型(如AlphaFold2)。同時(shí)也能對(duì)RNA、DNA、蛋白質(zhì)復(fù)合物進(jìn)行預(yù)測(cè)。
在與超算結(jié)果的對(duì)比中顯示,OpenComplex已經(jīng)初步具備通路預(yù)測(cè)能力。
以上便是智源在過去一年中在大模型領(lǐng)域方面的進(jìn)展。
帶來這些進(jìn)展其實(shí)都離不開底層算力基座的支持。
去年,智源發(fā)布了FlagOpen1.0。這是一個(gè)面向異構(gòu)芯片、支持多種框架的大模型全棧開源技術(shù)基座。
今年FlagOpen升級(jí)至2.0版本。在1.0的基礎(chǔ)上,進(jìn)一步完善了模型、數(shù)據(jù)、算法、評(píng)測(cè)、系統(tǒng)五大版圖布局,旨在打造大模型時(shí)代的Linux。

同時(shí),智源也構(gòu)建了為大模型而生、支持異構(gòu)芯片的算力集群“操作系統(tǒng)”FlagOS。

它包括異構(gòu)算力智能調(diào)度管理平臺(tái)九鼎、支持多元AI異構(gòu)算力的并行訓(xùn)推框架FlagScale、支持多種AI芯片架構(gòu)的高性能算子庫(kù)FlagAttention和FlagGems,集群診斷工具FlagDiagnose和AI芯片評(píng)測(cè)工具FlagPerf。
可向上支撐大模型訓(xùn)練推理評(píng)測(cè)等,向下管理底層異構(gòu)算力、高速網(wǎng)絡(luò)、分布式存儲(chǔ)等。
目前,F(xiàn)lagOS已支持了超過50個(gè)團(tuán)隊(duì)的大模型研發(fā),支持8種芯片,管理超過4600個(gè)AI加速卡,穩(wěn)定運(yùn)行20個(gè)月,SLA超過99.5%。
此外,智源研究院還推出了開源Triton算子庫(kù)、首個(gè)千萬級(jí)高質(zhì)量開源指令微調(diào)數(shù)據(jù)集InfinityInstruct、全球最大開源中英文多行業(yè)數(shù)據(jù)集IndustryCorpus等等新進(jìn)展。
可見在過去一年中,智源研究院的腳步走得非常快、且布局廣泛。
而值得關(guān)注的是,在發(fā)布新進(jìn)展同時(shí),智源研究院這一國(guó)內(nèi)頂級(jí)AI研究機(jī)構(gòu),此次也明確地公布了對(duì)未來技術(shù)趨勢(shì)的判斷。
面向更前沿技術(shù)問題
與大模型領(lǐng)域的工業(yè)界玩家不同,智源研究院是一家非營(yíng)利研究機(jī)構(gòu),相較于短期應(yīng)用,更聚焦AI的前沿研究。
在與智源研究院院長(zhǎng)王仲遠(yuǎn)的交流中,他對(duì)此解釋說:
企業(yè)已經(jīng)在做的事,智源不會(huì)做,而是聚焦于更前沿的技術(shù)問題。

總結(jié)起來,智源對(duì)技術(shù)路線發(fā)展的判斷很明確:
在基礎(chǔ)模型層面上,是要解決大語言模型發(fā)展過程中面臨的核心痛點(diǎn)。
比如算力問題。
2023年9月,智源研究院就聯(lián)合中科院計(jì)算所、南洋理工大學(xué)、電子科技大學(xué)、哈爾濱工業(yè)大學(xué)等研究團(tuán)隊(duì),提出了一種“生長(zhǎng)策略”(growth strategy)。
簡(jiǎn)單來說,基于生長(zhǎng)策略,模型的參數(shù)量在訓(xùn)練過程中并不是固定的,而是可以隨著訓(xùn)練進(jìn)行,從較小的參數(shù)規(guī)模擴(kuò)展到更大的參數(shù)規(guī)模。
這次發(fā)布的稠密萬億參數(shù)語言模型Tele-FLM,就是通過生長(zhǎng)技術(shù)來訓(xùn)練的。王仲遠(yuǎn)透露,訓(xùn)練這一模型只用了112臺(tái)A800,也就是不到1000張卡。
又比如多模態(tài)問題。
盡管多模態(tài)已經(jīng)成為當(dāng)下大模型發(fā)展的主流方向,但在現(xiàn)階段,很多多模態(tài)大模型其實(shí)是單一跨模態(tài)模型,無法同時(shí)實(shí)現(xiàn)視頻、圖片的生成和理解。
智源的Emu項(xiàng)目,旨在最終實(shí)現(xiàn)原生多模態(tài)世界模型。
從訓(xùn)練數(shù)據(jù)的角度,從一開始,文字、圖像、視頻數(shù)據(jù)就被放在一起聯(lián)合訓(xùn)練;從技術(shù)路線的角度,智源也選擇了難度更高的自回歸路線而非Sora帶火的DiT路線。
我們認(rèn)為,像OpenAI,未來也可能會(huì)將ChatGPT和Sora做進(jìn)一步的融合。
從技術(shù)判斷上,我們想要瞄準(zhǔn)真正的多模態(tài)大模型,因此選擇了自回歸這樣一個(gè)我們認(rèn)為終極的技術(shù)路線。
而在更具體的應(yīng)用層面上,重點(diǎn)關(guān)注具身智能和生物計(jì)算, 也并非是單純追熱點(diǎn)。
王仲遠(yuǎn)甚至主動(dòng)降了一波預(yù)期:
大家要客觀理性地來看待技術(shù)的發(fā)展周期,具身智能未來幾年內(nèi)也可能進(jìn)入低谷。但我們堅(jiān)信智能體會(huì)從數(shù)字世界進(jìn)入到物理世界。
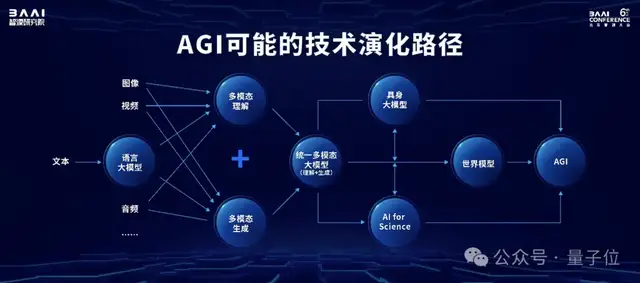
有此布局的核心原因還是要做“原始的創(chuàng)新”、“集中資源關(guān)注核心技術(shù)的突破”,智源研究院認(rèn)為,數(shù)字世界的智能體進(jìn)入物理世界,主要有兩條路線:
一是在宏觀世界賦能硬件,也就是具身智能。
二是進(jìn)入微觀世界,也就是用大模型對(duì)生命分子進(jìn)行研究。
這兩條技術(shù)路線“會(huì)跟世界模型相互促進(jìn),并且最終實(shí)現(xiàn)AGI”。
值得關(guān)注的是,在更面向未來的技術(shù)路線選擇之外,智源研究院在最新發(fā)布中,再次強(qiáng)調(diào)了開源開放。
比如Tele-FLM的核心技術(shù)“生長(zhǎng)策略”,其技術(shù)細(xì)節(jié)此前就已完全公開。此番發(fā)布的多模態(tài)圖文模型Bunny,同樣是基座模型、模型參數(shù)、訓(xùn)練代碼、訓(xùn)練數(shù)據(jù)全部開源。Tele-FLM的萬億參數(shù)版本和Emu 3也計(jì)劃在安全評(píng)估之后對(duì)外開源。
事實(shí)上,無論是高舉高打的技術(shù)布局思路,還是一以貫之的技術(shù)共享模式,都是智源研究院創(chuàng)立之始就刻寫在基因里的。
2018年,智源研究院作為人工智能領(lǐng)域的新型研發(fā)機(jī)構(gòu)正式成立,其使命可以概括為:
- 推動(dòng)5大源頭創(chuàng)新,包括基礎(chǔ)理論、學(xué)術(shù)思想、頂尖人才、企業(yè)創(chuàng)新和發(fā)展政策。
- 改變?nèi)斯ぶ悄芟乱粋€(gè)10年,包括人才到生態(tài),成果到系統(tǒng)。
- 創(chuàng)造30年后依然有價(jià)值的代表作:判斷人工智能發(fā)展大方向,創(chuàng)造經(jīng)得起時(shí)間檢驗(yàn)的代表作。
2020年,智源“悟道”項(xiàng)目立項(xiàng)。2021年3月,悟道1.0發(fā)布,智源研究院正式使用“大模型”這個(gè)說法,此后被業(yè)界廣泛采納。
而悟道系列開源大模型,也成為過去一年中國(guó)產(chǎn)大模型快速發(fā)展的技術(shù)基石之一。一方面,悟道的7個(gè)開源模型成果涵蓋文本類、圖文類、蛋白質(zhì)類等多個(gè)領(lǐng)域,在發(fā)布時(shí)連續(xù)創(chuàng)下“中國(guó)首個(gè)+世界最大”記錄。另一方面,悟道系列也為中國(guó)大模型產(chǎn)業(yè)培養(yǎng)了一大批大模型人才,不少現(xiàn)如今在產(chǎn)業(yè)界擔(dān)當(dāng)主力的大模型研究者,都是“智源系”出身。
可以說,智源研究院是最早系統(tǒng)布局大模型研究的國(guó)內(nèi)科研機(jī)構(gòu)之一,是中國(guó)大模型研究的啟蒙先行者。
大會(huì)現(xiàn)場(chǎng),幾位國(guó)內(nèi)AI大咖也對(duì)此有頗多感慨。
楊植麟提到,智源研究院至少是在亞洲地區(qū)最早投入、而且真的投入去做大模型的機(jī)構(gòu)。
這是非常難得、非常領(lǐng)先的一個(gè)想法。
王小川覺得,智源在中國(guó)大模型產(chǎn)業(yè)中有著非常好的定位。
智源既有技術(shù)高度,又有智庫(kù)的角色。這兩方面有獨(dú)有的意義,在生態(tài)里能夠幫助我們更加快速健康的發(fā)展。
李大海則提到,在大模型領(lǐng)域的快速發(fā)展過程中,有一些事可能商業(yè)公司沒有動(dòng)力、沒有資源去做。從創(chuàng)企角度出發(fā),非常期待在智源的撮合跟帶領(lǐng)下,搭建一個(gè)更好的平臺(tái),把需要做好的事情一起協(xié)作好。
張鵬表示,非常非常希望跟智源長(zhǎng)期在學(xué)術(shù)研究、落地應(yīng)用合作,甚至包括公共政策相關(guān)方面繼續(xù)保持合作,也祝愿智源大會(huì)越辦越好。
也正是這樣的技術(shù)領(lǐng)導(dǎo)力和技術(shù)影響力,使得智源研究院成為國(guó)內(nèi)最具國(guó)際號(hào)召力的研究機(jī)構(gòu)之一。一年一度的智源大會(huì),已然成為國(guó)內(nèi)國(guó)際頂尖AI學(xué)者交流的重要平臺(tái)。
2019年首屆智源大會(huì)起,每年都不乏圖靈獎(jiǎng)得主、明星項(xiàng)目大咖、行業(yè)關(guān)鍵人物現(xiàn)身這場(chǎng)“AI春晚”。深度學(xué)習(xí)三巨頭、貝葉斯網(wǎng)絡(luò)提出者Judea Pearl、RISC-V掌門人David Patterson……都曾先后參與其中,帶來精彩觀點(diǎn)的碰撞。
今年,是智源大會(huì)舉辦的第6年,現(xiàn)場(chǎng)依舊爆滿,足見其在AI從業(yè)者和相關(guān)專業(yè)學(xué)生中的影響力。

如果說,過去頂級(jí)的AI學(xué)術(shù)、交流活動(dòng)都遠(yuǎn)在大洋彼岸,現(xiàn)在,就在中國(guó),就在北京,以智源大會(huì)為代表,我們也有了屬于自己的頂級(jí)AI盛會(huì)。
在探討多模態(tài)大模型、AGI的全體大會(huì)之外,今年的智源大會(huì)依然圍繞大家最關(guān)注的前沿技術(shù)問題,設(shè)置了大模型產(chǎn)業(yè)技術(shù)、Agent、具身智能、數(shù)據(jù)新基建等等分論壇和技術(shù)報(bào)告。
如果你感興趣,更多詳情,可以關(guān)注:
https://2024.baai.ac.cn/schedule
— 完 —
相關(guān)閱讀
.png)


智源王仲遠(yuǎn):多模態(tài)大模型對(duì)產(chǎn)業(yè)更加重要,得多模態(tài)大模型得天下
其實(shí)Scaling Law在人工智能發(fā)展領(lǐng)域中一直起著作用

開源標(biāo)桿!最強(qiáng)中英雙語大模型來了,340億參數(shù),超越 Llama2-70B等所有開源模型
“全家桶”級(jí)開源,毫無保留


一塊顯卡理解一部電影,最新超長(zhǎng)視頻理解大模型出爐!“大海撈針”準(zhǔn)確率近95%,代碼已開源
智源研究院聯(lián)合多所高校帶來




