
具身空間數(shù)據(jù)技術(shù)的路線之爭:合成重建VS全端生成
合成數(shù)據(jù)不只是“虛擬的替代品”,更可能是具身智能邁向通用智能的關(guān)鍵推動力
生境科技投稿
量子位 | 公眾號 QbitAI
具身智能的突破離不開高質(zhì)量數(shù)據(jù)。
現(xiàn)實(shí)數(shù)據(jù)采集成本實(shí)在太高,于是,合成數(shù)據(jù)的技術(shù)就顯得尤為重要。
目前,具身合成數(shù)據(jù)有兩條主要技術(shù)路線之爭:“視頻合成+3D重建”or “端到端3D生成”。
參考自動駕駛的成功經(jīng)驗(yàn),前者模態(tài)轉(zhuǎn)換鏈路過長容易導(dǎo)致誤差累積;后者“直接合成3D數(shù)據(jù)”理論上有信息效率優(yōu)勢,但需要克服“常識欠缺”等挑戰(zhàn)。
英偉達(dá)在CES 2025指出“尚無互聯(lián)網(wǎng)規(guī)模的機(jī)器人數(shù)據(jù)”,自動駕駛已具備城市級仿真,但家庭等復(fù)雜室內(nèi)環(huán)境缺乏3D合成平臺。

△“沒有數(shù)據(jù),就創(chuàng)造數(shù)據(jù)。”NVIDIA Cosmos World Foundation Models, CES 2025
為解決“常識欠缺”困境,沿用“端到端三維生成”的技術(shù)路徑,本文提出“模態(tài)編碼”的全新技術(shù)解決方案:打破“排布=幾何”舊范式,將空間方案本身進(jìn)行數(shù)字化編碼、特征提取以及隱式學(xué)習(xí)。
結(jié)合強(qiáng)化學(xué)習(xí)策略,探索一種新的可能:不僅生成空間,更生成“可被理解與使用”的空間。

具身智能的現(xiàn)實(shí)挑戰(zhàn)
智能困境:強(qiáng)身體,弱大腦
在機(jī)器人的發(fā)展史中,“身體”往往走得比“大腦”更快。
我們已經(jīng)能讓機(jī)器人精準(zhǔn)行走、翻滾甚至跑酷,但當(dāng)它們被放入一個(gè)陌生的房間,任務(wù)就變得不再簡單。
機(jī)器不懂墻后是什么,也不知道為什么沙發(fā)要靠墻放——更別提主動理解人類的意圖。

△具身“大腦”整體框架Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI, 09 Jul 2024
具身智能的本質(zhì),是“感知 + 推理 + 決策”的一體化能力。
而這一切的前提,是系統(tǒng)必須擁有對空間的理解力。不是二維圖像中的像素點(diǎn),而是結(jié)構(gòu)清晰、語義明確的三維場景知識。
缺乏這種能力,即使控制算法再精妙,也難以支撐復(fù)雜環(huán)境下的自主行為。
今天的AI正處于一個(gè)臨界點(diǎn):算力與模型能力迅速提升,但如果沒有足夠優(yōu)質(zhì)的空間數(shù)據(jù)作支撐,“聰明的大腦”也無法真正落地。
數(shù)據(jù)困境
眼下的現(xiàn)實(shí)是,具身智能的數(shù)據(jù),不但少,而且不夠用。
現(xiàn)有的數(shù)據(jù)來源大致可以分為三類:
真實(shí)掃描數(shù)據(jù)(如 Matterport3D),數(shù)量有限且覆蓋場景單一;
游戲引擎搭建環(huán)境(如 AI2-THOR),生成效率低、交互性弱;
開源合成數(shù)據(jù)集(如 SUNCG),語義標(biāo)簽粗略,缺乏物理一致性。
相比之下,自動駕駛領(lǐng)域已構(gòu)建起完整的數(shù)據(jù)閉環(huán),從城市建模到傳感器仿真,鏈條清晰、效率高。
而在室內(nèi)具身智能場景中,空間數(shù)據(jù)不僅要“看起來像”,還要“行為上真實(shí)”——比如桌子不僅要有形狀,還要能承重;門不僅要有鉸鏈,還要能被打開。
更復(fù)雜的問題在于“家庭”。每個(gè)家庭都有獨(dú)特的布置習(xí)慣和使用方式,這種多樣性決定了:現(xiàn)實(shí)中幾乎不可能采集到覆蓋全部變體的訓(xùn)練數(shù)據(jù)。
換句話說,靠傳統(tǒng)手段“掃遍全世界”來訓(xùn)練模型,不現(xiàn)實(shí),也不經(jīng)濟(jì)。

△NVIDIA Cosmos World Foundation重大更新,用于大規(guī)模可控合成數(shù)據(jù)生成,2025 年 3 月 18 日
場景生成(Gen)與模擬(Sim)
機(jī)器人合成數(shù)據(jù)可拆解成兩個(gè)關(guān)鍵部分:場景生成(Gen)與模擬(Sim)。
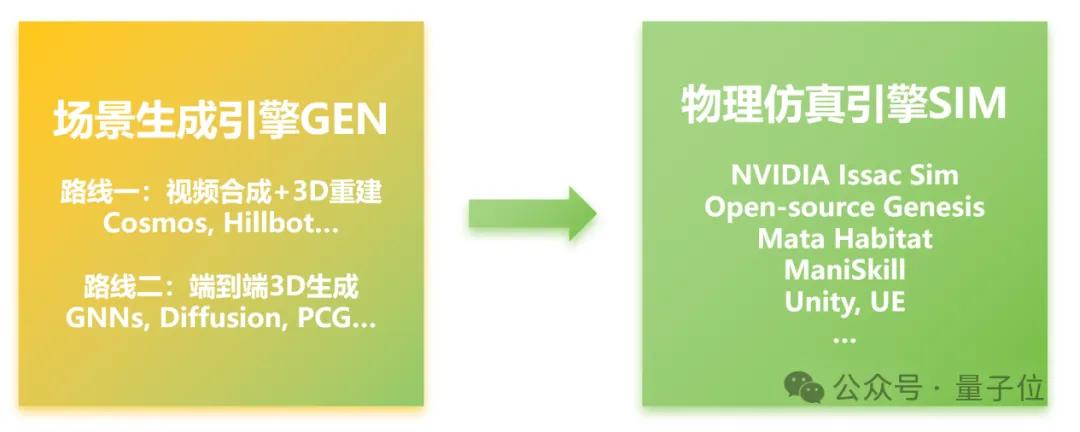
相比之下,豐富多樣、結(jié)構(gòu)合理的室內(nèi)空間生成(Gen)?已成為系統(tǒng)性能瓶頸,主要存在兩種技術(shù)路徑:
合成視頻+3D重建:基于像素流驅(qū)動,先生成視頻或圖像,再重建為點(diǎn)云或mesh等非結(jié)構(gòu)化3D數(shù)據(jù),最終轉(zhuǎn)為結(jié)構(gòu)化語義模型。如Hillbot、群核科技、李飛飛“World Models”項(xiàng)目等。此方法路徑長、誤差易累積,結(jié)構(gòu)精度有限。
AIGC直接合成3D數(shù)據(jù):利用圖神經(jīng)網(wǎng)絡(luò)(GNN)、擴(kuò)散模型(Diffusion)、注意力機(jī)制(Attention)等方法,直接合成結(jié)構(gòu)化空間數(shù)據(jù)。如 ATISS、LEGO-Net、DiffuScene、RoomFormer 等代表模型,部分方案結(jié)合程序化生成技術(shù),如 Infinigen(CVPR 2024)。

△“3D場景合成+仿真模擬+現(xiàn)實(shí)交互”sim2real技術(shù)框架,生境科技繪制
路線一:視頻合成+3D重建
早在2021年,李飛飛團(tuán)隊(duì)的BEHAVIOR基準(zhǔn)及“世界模型”研究提出了基于像素和視頻幀的具身智能建模思路,生成的場景僅為mesh殼體,缺乏清晰的空間結(jié)構(gòu)和語義標(biāo)注,物體邊界模糊,難以直接用于物理仿真。

△“視頻合成+3D重建”技術(shù)路線,生境科技繪制

△李飛飛世界模型,基于mesh網(wǎng)格,無語義

△結(jié)構(gòu)化矢量數(shù)據(jù),物理一致,語義完備,易于交互
SpatialVerse + SpatialLM(群核科技)

#△群核科技具身合成技術(shù)路線,生境科技基于公開資料繪制
群核科技的SpatialLM和SpatialVerse是該路線的代表性技術(shù)。
SpatialLM通過微調(diào)大規(guī)模語言模型(LLM)來理解3D數(shù)據(jù)的語義,SpatialVerse則結(jié)合酷家樂的技術(shù)進(jìn)行數(shù)據(jù)增強(qiáng)、分割注釋和渲染優(yōu)化。
盡管該技術(shù)能夠從視頻中提取3D場景數(shù)據(jù),但依然面臨物理一致性和精度的問題。
通過這種方式,機(jī)器人的路徑規(guī)劃和行為決策得到了增強(qiáng),盡管從理論上來說,模態(tài)鏈路仍然是一個(gè)挑戰(zhàn) 。

△SpatialLM: Large Language Model for Spatial Understanding,群核科技,2025
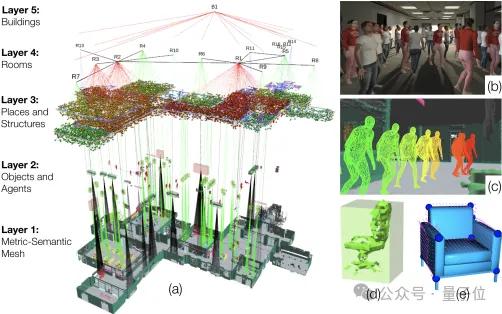
△Kimera: from SLAM to Spatial Perception with 3D Dynamic Scene Graphs, MIT, 2021
Cosmos+Sapien/ManiSkill (Hillbot(美國))

△Hillbot具身合成技術(shù)路線,生境科技基于公開資料繪制
Hillbot是另一具身合成數(shù)據(jù)企業(yè),其技術(shù)路徑包括通過 NVIDIA Cosmos 快速生成環(huán)境視頻片段,利用 Sapien/ManiSkill 對視頻進(jìn)行3D場景解析和重建。
此過程中,Hillbot通過標(biāo)簽化的三維模型庫將物體(如冰箱、餐桌)替換為仿真中的對應(yīng)對象,并賦予物理屬性,從而實(shí)現(xiàn)機(jī)器人與虛擬環(huán)境的交互。
核心問題與挑戰(zhàn)
盡管該路線已實(shí)現(xiàn)從圖像生成到任務(wù)訓(xùn)練的鏈條構(gòu)建,但其問題也相對集中:
精度瓶頸:像素驅(qū)動方式在轉(zhuǎn)換為結(jié)構(gòu)化模型時(shí)常出現(xiàn)細(xì)節(jié)缺失與物理不一致;
鏈路復(fù)雜:多模態(tài)轉(zhuǎn)換增加誤差傳遞風(fēng)險(xiǎn),使生成結(jié)果對任務(wù)泛化能力不足;
控制力弱:現(xiàn)有系統(tǒng)在場景結(jié)構(gòu)約束、家具邏輯布局等方面控制精度有限;
訓(xùn)練不穩(wěn)定:受限于視頻幀數(shù)據(jù)的間斷性,難以支撐長序列任務(wù)推理。
尤其在需要?jiǎng)討B(tài)交互的家庭場景中,這一路線更易暴露其“語義弱”和“控制難”的根本問題。

△SpatialLM測試:泛化能力弱,目前結(jié)構(gòu)精度無法落地

△OpenRooms項(xiàng)目,對實(shí)拍視頻做數(shù)據(jù)增強(qiáng)
路線二:端到端的3D直接生成

△“端到端3D場景合成”技術(shù)路線,生境科技繪制

主要方法
圖神經(jīng)網(wǎng)絡(luò)(GNNs)
圖神經(jīng)網(wǎng)絡(luò)(GNNs)已成為3D室內(nèi)場景生成的重要工具,能有效建模場景中物體及其空間關(guān)系。
MIT團(tuán)隊(duì)2024年提出的超圖模型通過圖結(jié)構(gòu)表征房間關(guān)系,提升空間利用效率。HAISOR(2024)結(jié)合圖卷積網(wǎng)絡(luò)和強(qiáng)化學(xué)習(xí),優(yōu)化家具布局。
PlanIT(2019)通過符號關(guān)系圖和自回歸模型生成兼具邏輯性與功能性的布局。
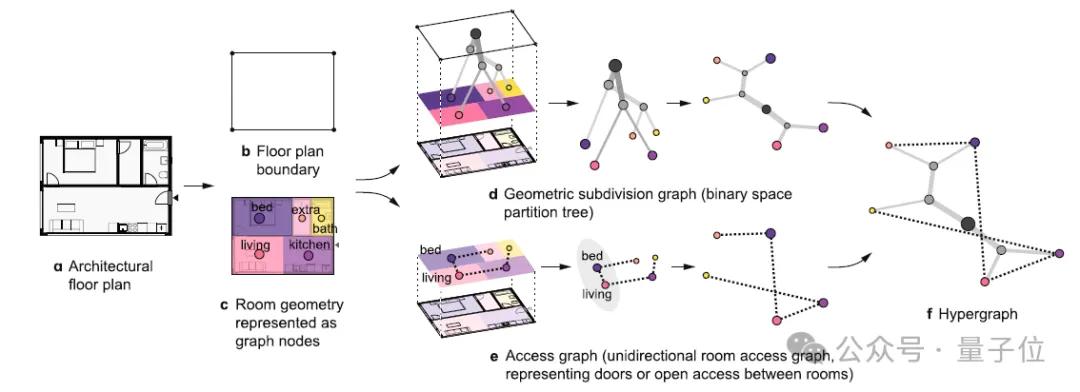
△A hypergraph model shows the carbon reduction potential of effective space use in housing, MIT, 2024

△Haisor: Human-aware Indoor Scene Optimization via Deep Reinforcement Learning, 中科院 2024
自回歸 Transformer
自回歸 Transformer?模型在3D場景合成中表現(xiàn)出色,特別適用于處理物體集合的無序性和文本驅(qū)動生成任務(wù)。
ATISS(2021)利用自回歸模型預(yù)測每個(gè)物體的位置、類別和姿態(tài),基于房間平面圖生成多樣且合理的布局。
InstructScene(2024)結(jié)合語義圖先驗(yàn)和圖 Transformer,將語言指令轉(zhuǎn)化為結(jié)構(gòu)圖,提升了文本驅(qū)動生成的可控性和準(zhǔn)確性。

△ATISS: Autoregressive Transformers for Indoor Scene Synthesis, NVIDIA Toronto AI Lab, 2021

△https://research.nvidia.com/labs/toronto-ai/ATISS/
擴(kuò)散模型 Diffusion
在3D場景合成中展現(xiàn)出強(qiáng)大潛力,通過去噪過程逐步優(yōu)化布局。
LEGO-NET(2023)通過迭代優(yōu)化生成符合人類偏好的合理布局,而?DiffuScene(2023)利用去噪擴(kuò)散模型生成物理合理且視覺真實(shí)的完整場景,支持文本或局部場景控制。

△DiffuScene: Denoising Diffusion Models for Generative Indoor Scene Synthesis, 24 Mar 2023
程序化生成 (PCG)
程序化生成,則通過預(yù)定義規(guī)則合成3D場景,具備較高的可控性和可解釋性。
Infinigen Indoors(2024)和?ProcTHOR(2022)分別通過隨機(jī)化生成室內(nèi)環(huán)境和自動生成可交互住宅環(huán)境,突出了場景結(jié)構(gòu)和風(fēng)格的精確控制。

△ProcTHOR: Large-Scale Embodied AI Using Procedural Generation, NeurIPS 2022
其他方法,如LLM
此外,大語言模型(LLM)也開始在此領(lǐng)域展現(xiàn)潛力。
SceneCraft(2025)提出通過圖像循環(huán)引導(dǎo)生成室內(nèi)3D場景,而?FlairGPT(2025)設(shè)計(jì)了一個(gè)結(jié)構(gòu)化的戶型布局agent系統(tǒng),分解設(shè)計(jì)任務(wù)進(jìn)行推理。
SceneTeller(2024)則直接通過文本描述生成3D物體位置,展示了強(qiáng)大的語言到空間映射能力。

△一句話“生成一個(gè)雙人臥室”SceneTeller: Language-to-3D Scene Generation,30 Jul 2024
核心問題和挑戰(zhàn)
盡管端到端方法在理論上具備效率與表達(dá)力的雙重優(yōu)勢,但生成質(zhì)量普遍較低,缺乏常識,甚至不及“視頻合成”路線。
“視頻合成+3D重建”路線依賴于真實(shí)或擬真視頻,天然具備常識與空間邏輯。
而端到端3D生成則從零開始,缺乏類似大模型中的“世界經(jīng)驗(yàn)”,如果不引入專業(yè)知識作為前置輸入,AI很難生成合理有效的空間結(jié)果。
AI合成空間常見問題有:
現(xiàn)實(shí)合理性不足:易出現(xiàn)物體重疊、通道阻塞等邏輯錯(cuò)誤;
控制精度不足:難以對特定布局需求或使用偏好做出精準(zhǔn)響應(yīng);

△基于GNN,端到端合成3D數(shù)據(jù)的SOTA效果Conditional room layout generation based on graph neural networks, SMI 2024
程序化生成的方式雖然通過設(shè)置大量顯示規(guī)則的方式避免了邏輯硬傷,但是又會導(dǎo)致系統(tǒng)魯棒性低,“缺乏設(shè)計(jì)彈性”,面對復(fù)雜戶型適應(yīng)性差,布局松散雜亂,難以還原真實(shí)空間的設(shè)計(jì)品質(zhì)與實(shí)用性。

△Infinigen程序化合成數(shù)據(jù)集質(zhì)量,英偉達(dá)Isaac Sim官方文檔
模態(tài)解決方案
端到端3D合成難以落地的根本原因在于:室內(nèi)設(shè)計(jì)中蘊(yùn)含大量隱性行業(yè)知識,尚未被系統(tǒng)化表達(dá)并embedding到AI的數(shù)學(xué)空間中進(jìn)行隱式學(xué)習(xí)。
在高密度室內(nèi)空間中,場景建模不僅要“生成出東西”,還要“生成得合理”,這對模型的結(jié)構(gòu)認(rèn)知能力提出了更高要求。
Sengine SimHub 是近年提出的一套室內(nèi)空間生成引擎——通過“模態(tài)編碼”將設(shè)計(jì)知識融入生成過程。
目標(biāo)是實(shí)現(xiàn)從戶型圖、功能需求,到最終三維場景數(shù)據(jù)的自動轉(zhuǎn)譯。
與傳統(tǒng)的圖像合成方法不同,它更像是“把建筑師的經(jīng)驗(yàn)裝進(jìn)了一個(gè)生成器”——在生成房間結(jié)構(gòu)的同時(shí),考慮到了空間功能、動線流暢性、家具擺放邏輯等實(shí)際設(shè)計(jì)因素。
這個(gè)系統(tǒng)的核心,是一種被稱為“空間模態(tài)編碼”的方法。
簡單來說,它把空間設(shè)計(jì)中的顯性規(guī)則(比如“餐桌要靠近廚房”)轉(zhuǎn)化為可以被模型學(xué)習(xí)的數(shù)學(xué)結(jié)構(gòu),再通過強(qiáng)化學(xué)習(xí)策略,讓模型在面對不同戶型或使用場景時(shí),能夠做出相對合理的結(jié)構(gòu)判斷。
系統(tǒng)還內(nèi)嵌了一套訓(xùn)練流程,涵蓋空間編碼、物體搭配、數(shù)據(jù)優(yōu)化等步驟,從而提升生成過程的穩(wěn)定性與適應(yīng)能力。
這不僅有助于模擬訓(xùn)練中的精度控制,也使得生成數(shù)據(jù)更加貼近真實(shí)空間的邏輯與語義。

△戶型圖 + 功能需求 + 設(shè)計(jì)規(guī)范 → 結(jié)構(gòu)化3D空間數(shù)據(jù)
雖然這種模態(tài)化生成方式仍處于發(fā)展初期,但它提供了一種新的思路:不是單純依賴圖像或文本驅(qū)動的生成模型,而是嘗試在設(shè)計(jì)邏輯與空間數(shù)據(jù)之間建立更緊密的聯(lián)系。
在未來具身智能場景中,類似的系統(tǒng)或許將成為機(jī)器人訓(xùn)練與空間認(rèn)知建模的重要組成部分。

△Sengine SimHub 家具排布自適應(yīng)算法,2025
總結(jié)
在自動駕駛已經(jīng)實(shí)現(xiàn)高保真數(shù)據(jù)閉環(huán)的當(dāng)下,具身智能領(lǐng)域依然面臨“數(shù)據(jù)荒”的現(xiàn)實(shí)。
尤其是那些發(fā)生在室內(nèi)空間的任務(wù)——從端茶遞水到復(fù)雜協(xié)作——對結(jié)構(gòu)化、語義化、交互可控的三維場景數(shù)據(jù)有著極高要求。
然而,現(xiàn)實(shí)世界的數(shù)據(jù)難采、成本高,遠(yuǎn)遠(yuǎn)跟不上算法發(fā)展的速度。

△Duality AI(美國)數(shù)字孿生仿真平臺“Falcon”
于是,一場關(guān)于“如何創(chuàng)造虛擬世界”的路線之爭悄然展開。一邊是基于視頻合成再做三維重建的路徑,技術(shù)成熟,邏輯直觀,卻始終繞不開模態(tài)轉(zhuǎn)換帶來的信息損耗和控制力瓶頸;另一邊,是直接生成結(jié)構(gòu)化三維場景的端到端方法,理論上更高效也更自由,但在實(shí)際落地時(shí)往往顯得“太理想”。
回望這兩條路徑,我們看到的不只是技術(shù)分歧,更是一場關(guān)于“空間理解方式”的深層對話。
是靠視覺還原現(xiàn)實(shí),還是試圖從設(shè)計(jì)邏輯出發(fā)重構(gòu)空間?是先采集、再理解,還是邊生成、邊控制?但有一點(diǎn)可以肯定:如果我們希望機(jī)器人真正“理解”空間、適應(yīng)人類環(huán)境,就不能只依賴數(shù)據(jù)的堆砌。
我們需要的是一種能嵌入規(guī)則、吸納偏好、支持交互的空間數(shù)據(jù)生成體系。
為解決這一困境,本文提出了一種基于模態(tài)編碼的新技術(shù)思路:不僅生成空間,更生成“可被理解與使用”的空間。
將空間方案視為一種行業(yè)模態(tài)進(jìn)行建模與優(yōu)化。
構(gòu)建深度強(qiáng)化學(xué)習(xí)框架,通過性能評估函數(shù)(PEF)指導(dǎo)AI持續(xù)進(jìn)化。
模態(tài)編碼、強(qiáng)化學(xué)習(xí)、結(jié)構(gòu)感知——這些技術(shù)并非終點(diǎn),而是通向更具靈活性和適應(yīng)力智能系統(tǒng)的鑰匙。
下一步,可能不是再多采一點(diǎn)數(shù)據(jù),而是換一種思路去創(chuàng)造“有用的數(shù)據(jù)”。
生境科技劉紫東認(rèn)為,具身智能的未來,也許就藏在我們?nèi)绾味x空間、理解空間的方式之中。

△Click the image to view the sheet.“端到端生成3D空間”代表性研究,生境科技整理
眼下,機(jī)器人流行視頻中高難度動作(空翻、跳舞、格斗等)主要依靠遙控/預(yù)設(shè)編程完成的。
機(jī)器人逐漸完善了自身運(yùn)動控制能力,然而對外環(huán)境感知、推理能力有待完善。
數(shù)據(jù)是AI時(shí)代的石油。
合成數(shù)據(jù)不只是“虛擬的替代品”,更可能是具身智能邁向通用能力的關(guān)鍵推動力。
- 云計(jì)算一哥10分鐘發(fā)了25個(gè)新品!Kimi和MiniMax首次上桌2025-12-03
- Ilya剛預(yù)言完,世界首個(gè)原生多模態(tài)架構(gòu)NEO就來了:視覺和語言徹底被焊死2025-12-06
- 前端沒死,AI APP正在返祖2025-12-02
- 華為新架構(gòu)砍了Transformer大動脈!任意模型推理能力原地飆升2025-12-06
相關(guān)閱讀

北大具身智能成果入選CVPR'24:只需一張圖一個(gè)指令,就能讓大模型玩轉(zhuǎn)機(jī)械臂
與谷歌RT2相比,更側(cè)重以物體為中心


讓機(jī)器人在“想象”中學(xué)習(xí)世界的模型來了!PI聯(lián)創(chuàng)課題組&清華陳建宇團(tuán)隊(duì)聯(lián)合出品
零真機(jī)、長時(shí)穩(wěn)定、厘米級控制
約-e1724904797529.png)
今日直播|與清北教授一起聊聊:具身智能的數(shù)據(jù)難題如何破局?
8月29日20:00,一起聊聊具身智能的數(shù)據(jù)難題如何破局~





