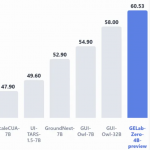
華為新架構(gòu)砍了Transformer大動脈!任意模型推理能力原地飆升
而且還不增加參數(shù)量
金磊 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
是時候給Transformer的大動脈動刀子了。
因為即便它享有當下AI世界基石的地位,但自身問題也是非常明顯:
一旦遇到復雜的數(shù)學題或者需要多步邏輯推理的時候,就開始一本正經(jīng)地胡說八道了……

問題究竟出在了哪里?
答案就藏在Transformer的核心機制里——Attention。
傳統(tǒng)Attention機制本質(zhì)上像是一種配對比較:每個詞只和另一個詞直接發(fā)生關(guān)系,生成一個注意力權(quán)重。
這種架構(gòu)雖然擅長捕捉長距離依賴,但在建模復雜、多跳、多點之間的邏輯關(guān)系時卻顯得力不從心了。
例如它能輕松理解“A認識B”,但如果要它理解“張三通過李四認識了王五”,即多跳、多點之間的復雜、間接關(guān)系,它的腦回路就顯得不夠深,推理能力的天花板瞬間觸頂。
現(xiàn)在,這個天花板,被華為諾亞方舟實驗室捅破了!
因為就在最近,團隊祭出了一種全新架構(gòu),叫做Nexus,即高階注意力機制(Higher-Order Attention Mechanism)。

它可以說是直接狙擊了Attention機制的核心痛點,使用更高階注意力,就能有效地建模多跳、多點之間的復雜關(guān)聯(lián)。
并且從實驗結(jié)果來看,效果也是有點驚艷在身上的。
只要換上Nexus這個新架構(gòu),模型在數(shù)學和科學等復雜推理任務(wù)上的能力,都能立馬實現(xiàn)大幅飆升,而且還是參數(shù)零增的那種。
妙哉,著實妙哉。
接下來,就讓我們一同來深入了解一下Nexus的精妙一刀。
高階注意力機制砍出的精妙一刀
要理解高階的意義,我們必須先回顧傳統(tǒng)自注意力機制的根本缺陷。
標準的自注意力機制本質(zhì)上是將輸入序列X分別通過三個線性變換WQ,WK,WV生成Query(Q)、Key(K)、Value(V),再通過softmax計算注意力權(quán)重:
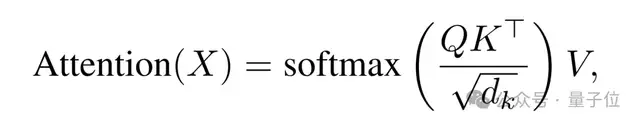
但這里就出現(xiàn)了一個關(guān)鍵的問題:Q和K都是靜態(tài)的、與上下文無關(guān)的線性投影。
也就是說,某個token的Query向量僅由它自己決定,無法感知其他token的存在;這導致注意力權(quán)重只能反映兩兩之間的直接關(guān)系。
精妙第一刀:Q和K的革新
華為諾亞方舟實驗室的第一個刀法,就精妙地砍在了這里:Nexus讓Q和K的生成過程本身也變成一個注意力操作。
換句話說,token在計算最終的Q和K之前,會先進行一次“預(yù)推理”;這個過程,其實就是一個嵌套的自注意力機制。
Token首先通過這個內(nèi)部循環(huán),從全局上下文中聚合信息,形成一個更加精煉、更具上下文感知能力的表示,然后再用這個表示去計算最終的Q和K。
這就好比,在你問我答(Q和K計算Attention)之前,每個token都先在內(nèi)部進行了深思熟慮,充分吸收了它在整個序列中的環(huán)境信息。
這樣生成的Q和K,自然就擺脫了線性投影的僵硬,具備了捕捉復雜關(guān)系的動態(tài)性。

精妙第二刀:巧用遞歸框架
Nexus架構(gòu)最精妙之處,還在于它的遞歸框架(Recursive Framework)。
這個內(nèi)部注意力循環(huán)可以被遞歸地來嵌套。
如果我們將一層Attention視為一階關(guān)系(A認識B),那么將Attention的輸出作為下一層Attention的輸入,就可以構(gòu)建二階關(guān)系(張三通過李四認識王五),乃至更高階的關(guān)系。
在Nexus中,這種遞歸嵌套被巧妙地集成在一個單層結(jié)構(gòu)中,形成了一個層次化的推理鏈。
論文進一步將上述過程遞歸化,定義第m階注意力為:

其中,m=1就是標準注意力;m=2表示Q和K由一次內(nèi)層注意力生成;m=3表示Q和K由二階注意力生成,相當于“注意力的注意力的注意力”。
這種結(jié)構(gòu)天然支持多跳推理鏈,就像人在解一道數(shù)學題時,先理解題干中的關(guān)鍵變量(第1層),再思考它們之間的公式關(guān)系(第2層),最后驗證整體邏輯是否自洽(第3層)。
精妙第三刀:不增參數(shù)
復雜架構(gòu)往往意味著更高的計算開銷和更多的參數(shù)量,但Nexus通過精巧的設(shè)計,完全規(guī)避了這些問題——權(quán)重共享策略。
具體來說,無論是內(nèi)層還是外層的注意力模塊,都復用同一組投影權(quán)重WQ,WK,WV。
這意味著,盡管計算路徑更復雜,但模型參數(shù)量和原始Transformer完全一致。
這種設(shè)計背后有一個關(guān)鍵假設(shè):無論處于遞歸的哪一層,將token投影為Query或Key的語義變換方式是相似的。
團隊通過實驗證明,這一假設(shè)是成立的。

在Pythia-70M的消融實驗中,使用權(quán)重共享的Nexus-QK-Shared版本,平均準確率仍比基線高出近1個百分點,而參數(shù)量毫無增加。
這就讓Nexus成為了一種極其高效的表達密度提升器——用相同的參數(shù),實現(xiàn)更強的推理能力。
只要換上Nexus,推理效果立竿見影
那么Nexus的效果到底如何?
論文在兩個維度做了驗證:從零訓練的小模型,以及對已有大模型的架構(gòu)改造。
小模型全面領(lǐng)先
研究團隊在 Pythia 系列(70M 到 1B)上從頭訓練 Nexus,并在六個標準推理數(shù)據(jù)集上評估:ARC-C、ARC-E、HellaSwag、LogiQA、PiQA和SciQ。
結(jié)果非常一致:Nexus 在所有規(guī)模上都優(yōu)于原始Transformer。
尤其在需要多步推理或科學常識的任務(wù)中提升顯著。例如:
- 在SciQ(科學問答)上,70M模型準確率從61.5%提升至68.5%,提升7個百分點;
- 在PiQA(物理常識推理)上,1B模型從62.5%提升至63.6%。
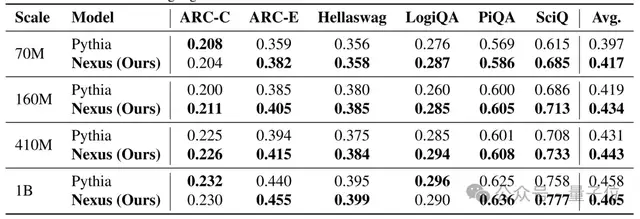
這說明Nexus特別擅長處理那些不能靠表面模式匹配解決的問題,是真的有在做推理。
大模型改裝即用
面對規(guī)模更大的模型,Nexus還體現(xiàn)出了即插即用的能力。
團隊將Qwen2.5的1.5B和7B版本的標準注意力層直接替換為Nexus結(jié)構(gòu),僅在SFT(監(jiān)督微調(diào))階段進行訓練,未改動預(yù)訓練權(quán)重。
結(jié)果表明,在三個高難度數(shù)學推理基準上(MATH-500、AIME24、GPQA-Diamond),Nexus 均帶來穩(wěn)定提升:
- Qwen2.5-1.5B在MATH-500上準確率從78.6% → 80.1%;
- Qwen2.5-7B在AIME24上從 45.2% → 47.5%。

尤其值得注意的是AIME24的提升,因為這類題目要求嚴格的多步邏輯推導,錯誤一步就全盤皆輸。Nexus 的改進說明,它確實在內(nèi)部構(gòu)建了更連貫的推理鏈。
從這一層面來看,Nexus不僅是一個新訓練范式,還是一套架構(gòu)升級套件。你不用重新訓練一個千億模型,只需在微調(diào)階段替換注意力層,就能解鎖更強的推理能力。
推理能力可內(nèi)生于架構(gòu)
雖然Nexus目前聚焦于語言模型,但其思想具有普適性。
高階關(guān)系建模在視覺、圖神經(jīng)網(wǎng)絡(luò)、多模態(tài)任務(wù)中同樣關(guān)鍵;例如,在視頻理解中,“A看到B打了C” 就是一個典型的三元關(guān)系,傳統(tǒng)Attention難以直接捕捉。
華為諾亞團隊表示,下一步將探索Nexus在視覺Transformer和多模態(tài)大模型中的應(yīng)用,并優(yōu)化其計算效率。
Transformer 的智商天花板,或許從來不在參數(shù)量,而在其注意力機制的表達能力。華為諾亞的 Nexus,用一種優(yōu)雅而高效的方式,為這一核心模塊注入了高階推理能力。
它不靠堆料,不靠提示工程,而是從架構(gòu)底層重構(gòu)了模型的思考方式。
因此,Nexus也提醒了我們:有時候,聰明的架構(gòu)比規(guī)模的大小更重要。
論文地址:
https://arxiv.org/abs/2512.03377
- 云計算一哥10分鐘發(fā)了25個新品!Kimi和MiniMax首次上桌2025-12-03
- Ilya剛預(yù)言完,世界首個原生多模態(tài)架構(gòu)NEO就來了:視覺和語言徹底被焊死2025-12-06
- 前端沒死,AI APP正在返祖2025-12-02
- 記憶張量 × 商湯大裝置:國產(chǎn) GPGPU 推理成本反超 A100!2025-12-04