非Transformer架構(gòu)落地之王,帶著離線智能和原生記憶能力在上海WAIC浮出水面
生來(lái)就適配設(shè)備,邊用邊學(xué)邊記憶
衡宇 昕祎 發(fā)自 凹非寺
量子位 | 公眾號(hào) QbitAI
剛剛,就在WAIC現(xiàn)場(chǎng)的一個(gè)展臺(tái),我親眼看到一只機(jī)器狗,在完全離線斷網(wǎng)的情況下,學(xué)會(huì)了一個(gè)新動(dòng)作。
是一位中年男性觀眾現(xiàn)場(chǎng)教的。讓它先轉(zhuǎn)個(gè)圈,再立起來(lái)做了個(gè)經(jīng)典的小狗拜拜。
教完過后沒兩分鐘,狗子自己就原模原樣復(fù)現(xiàn)出來(lái)了——
沒有預(yù)定程序,沒人遙控操縱,狗子全程離線。
一扭頭,這展臺(tái)還擺著幾只靈巧手,一會(huì)兒在愉快地玩黃金礦工,一會(huì)兒又玩推箱子推得正起勁。
聽展臺(tái)工作人員說(shuō),玩兒得這么溜的靈巧手,也是純離線,全靠它本地部署模型的視覺能力,看得懂畫面,也玩得轉(zhuǎn)策略。
其實(shí)靈巧手、機(jī)器狗、機(jī)器人等是本屆WAIC不少展位吸引目光的招牌產(chǎn)品。
之所以想和大家分享剛剛的所見所聞,一方面是因?yàn)樵谡妗るx線的狀態(tài)下,這倆端側(cè)設(shè)備表現(xiàn)得實(shí)在是不錯(cuò);另一方面,是因?yàn)椴渴鹪谒鼈兩砩系哪P停欠荰ransformer架構(gòu)的大模型。
展臺(tái)負(fù)責(zé)介紹的小姐妹告訴我們,背后是設(shè)備原生智能:能離線跑、會(huì)多模態(tài),還能邊用邊學(xué)。
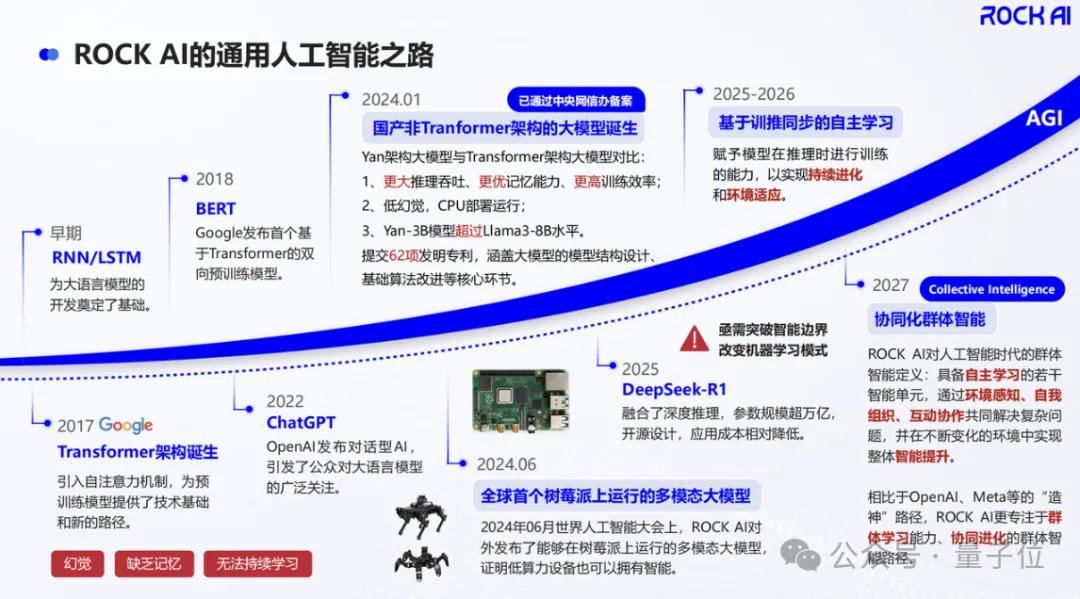
這套體系的幕后推手,是一家成立剛滿兩年的公司——RockAI。
早在ChatGPT名動(dòng)全球之前的2022年初,這家公司就開始全心押注非Transformer架構(gòu)大模型,從最底層重構(gòu)AI模型的運(yùn)行邏輯。
今年WAIC期間,RockAI創(chuàng)始人劉凡平公開表示:
目前AI的發(fā)展需要推翻兩座大山,一個(gè)是反向傳播,一個(gè)是Transformer。
當(dāng)大模型具備“原生記憶”能力
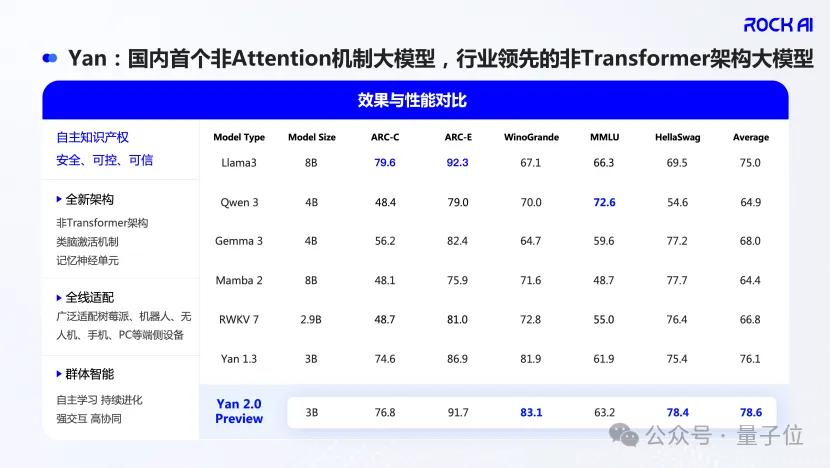
在RockAI展臺(tái)上自學(xué)新動(dòng)作的機(jī)器狗、會(huì)玩游戲的靈巧手,都運(yùn)行著RockAI最新推出的Yan 2.0 Preview大模型。
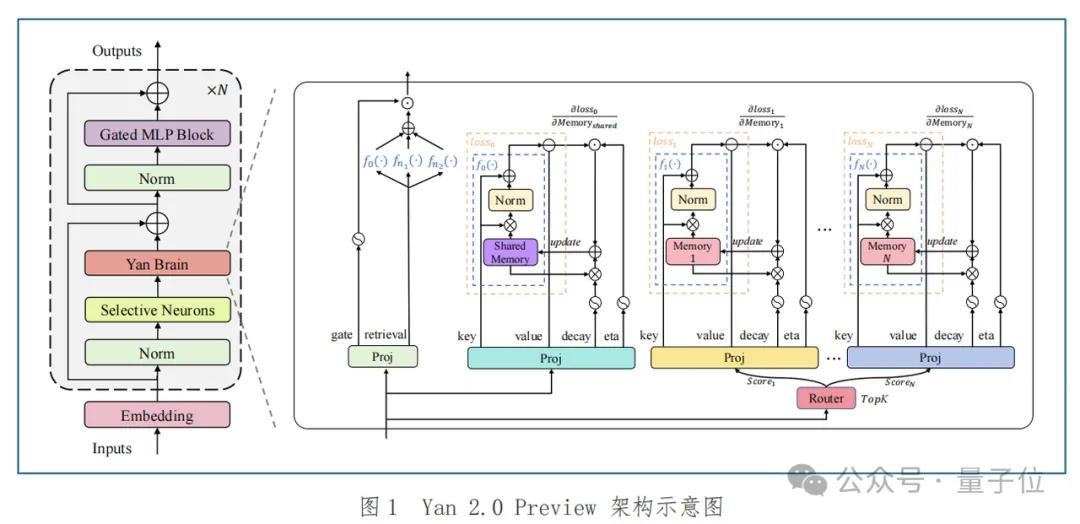
這個(gè)版本,相比初代Yan 1.0的語(yǔ)言能力、Yan 1.3的多模態(tài)理解能力,最大的突破在于它開始具備“記憶”了——引入了原生記憶模塊。
這里的“記憶”,不是對(duì)某個(gè)長(zhǎng)度上下文的窗口限制,而是Yan 2.0 Preview具備了邊用邊學(xué)、可持續(xù)進(jìn)化的能力。
現(xiàn)在大家用大模型,都會(huì)遇到這樣一種情況:提的問題超出了Chatbot的訓(xùn)練數(shù)據(jù)覆蓋范圍,得到一句“很抱歉,我的知識(shí)截至于2024年x月,無(wú)法提供相關(guān)信息”,要么就是得到一頓瞎編的結(jié)果,令人頭禿。
這是傳統(tǒng)大模型“先訓(xùn)練→再部署→使用過程不能更新”導(dǎo)致的。
所以,現(xiàn)在聯(lián)網(wǎng)搜索功能幾乎成了Chatbot們的標(biāo)配。
但相比于原生記憶,聯(lián)網(wǎng)搜索、外掛記憶庫(kù)、拓展長(zhǎng)上下文等解決方案其實(shí)沒有解決根本問題。
在這個(gè)問題上,Yan 2.0 Preview引入了一種訓(xùn)推同步的新機(jī)制。
訓(xùn)推同步意味著模型不再是一個(gè)凍結(jié)的產(chǎn)品,而是一個(gè)持續(xù)進(jìn)化的智能體。每一次與環(huán)境的交互,每一個(gè)新的任務(wù)場(chǎng)景,都能成為模型自主學(xué)習(xí)、進(jìn)化的養(yǎng)分。
要展開說(shuō)這種持續(xù)學(xué)習(xí)能力的實(shí)現(xiàn),就不得不提到RockAI對(duì)Yan 2.0 Preview的記憶模塊設(shè)計(jì)。
其前向過程可分為記憶更新與記憶檢索兩個(gè)階段。
首先來(lái)看記憶更新階段。
這一階段,模型會(huì)判斷哪些舊知識(shí)可以被遺忘,然后再?gòu)漠?dāng)前任務(wù)中提取出有價(jià)值的信息,寫入記憶模塊。
這個(gè)過程不靠外掛、不靠緩存,而是由一個(gè)專門的神經(jīng)網(wǎng)絡(luò)來(lái)模擬記憶行為來(lái)實(shí)現(xiàn)動(dòng)態(tài)擦除與增量寫入,以此實(shí)現(xiàn)在保留重要?dú)v史信息的同時(shí),靈活整合新知識(shí)。
其次是記憶檢索階段。
Yan 2.0 Preview設(shè)計(jì)了記憶稀疏機(jī)制,模型會(huì)從多個(gè)記憶槽中選出Top-K激活記憶,與長(zhǎng)期共享記憶融合,生成新的輸出。
這使得模型不只是有記性,更能“帶著記性去推理”。
這些機(jī)制組合在一起,讓Yan 2.0 Preview完成了對(duì)記憶網(wǎng)絡(luò)有效性的初步驗(yàn)證,模型不再是靜態(tài)的大腦,而開始變成一個(gè)能生長(zhǎng)的智能體。
用RockAI的話來(lái)說(shuō),這是邁向基于訓(xùn)推同步的自主學(xué)習(xí)的一大步。
雖然完全實(shí)現(xiàn)基于訓(xùn)推同步的自主學(xué)習(xí)在現(xiàn)在看來(lái)還是不可能之事,但這背后其實(shí)有一個(gè)非常現(xiàn)實(shí)主義的出發(fā)點(diǎn)。
早在2022年,RockAI創(chuàng)業(yè)之初就徹底放棄了Transformer架構(gòu),走一條完全不同的AI底層路徑。
原因很簡(jiǎn)單——
RockAI專注為端側(cè)服務(wù),而Transformer架構(gòu)模型雖然在語(yǔ)言處理任務(wù)上表現(xiàn)出色,但它們消耗大量計(jì)算資源和內(nèi)存,推理也異常吃算力。
尤其是對(duì)于長(zhǎng)序列輸入,Transformer的自注意力機(jī)制存在二次復(fù)雜度的計(jì)算和內(nèi)存需求,在諸如端側(cè)部署等場(chǎng)景中是天然的bug。
對(duì)于手機(jī)、機(jī)器人、IoT設(shè)備這些典型端側(cè)環(huán)境,資源敏感是一種常態(tài),不是一種例外。
彼時(shí)的RockAI就做出判斷:
AI要成為真正的基礎(chǔ)設(shè)施,就必須與具體設(shè)備深度融合,只有當(dāng)AI能夠在每一個(gè)終端設(shè)備上高效運(yùn)行之時(shí),它才能真正滲透到人類生活的每一個(gè)角落。
在這樣的思路下,Yan架構(gòu)誕生了,并逐漸迭代出1.0、1.3版本,直到今天來(lái)到Y(jié)an 2.0 Preview版本。
需要強(qiáng)調(diào)的是,Yan 2.0 Preview不是一個(gè)完整的產(chǎn)品版本,它的意義更多是RockAI進(jìn)行的一次重要技術(shù)預(yù)演。
這次他們想驗(yàn)證的,不是模型能不能答題、會(huì)不會(huì)生成圖文,而是一個(gè)更本質(zhì)的問題:
AI模型,能不能像人一樣,邊用邊學(xué)、越用越聰明?
這個(gè)問題的重要性遠(yuǎn)超技術(shù)本身。
如果答案是肯定的,我們對(duì)AI的理解就該改一改,它不再是工具,而是能主動(dòng)成長(zhǎng)的智能伙伴。
基于訓(xùn)推同步的自主學(xué)習(xí)機(jī)制,將有效信息隱式地存儲(chǔ)到多層神經(jīng)網(wǎng)絡(luò)的權(quán)重中,這比顯性的上下文工程更加優(yōu)雅,也更接近人類大腦的工作原理。
所以,展臺(tái)上玩游戲的靈巧手和自主學(xué)習(xí)的機(jī)器狗,不能當(dāng)個(gè)逛展的樂子看,更深層次的,這能被視作是一種可能性的預(yù)告,AI或許能進(jìn)入一個(gè)全新的進(jìn)化階段。
“離線智能”讓模型直接在設(shè)備上出生和成長(zhǎng)
最終通向AGI的路徑還在探索中,但方向是確定的:算法更簡(jiǎn)單、算力依賴更低、數(shù)據(jù)需求更少。
RockAI表示,要讓AI真正進(jìn)入這樣的進(jìn)化階段,光靠外部功能拼裝是不夠,必須從底層架構(gòu)動(dòng)刀,解決那些阻礙AI落地生長(zhǎng)的系統(tǒng)性問題。
“Transformer架構(gòu)的模型,從一開始就注定不適合在端側(cè)設(shè)備上跑。”RockAI的CTO楊華如是說(shuō)。
是不是有那么一絲絲“暴論”的味道?(doge)
但其實(shí)這句話絕不是沒有道理的歪理邪說(shuō)——
ChatGPT一鳴驚人后,Transformer架構(gòu)的模型席卷行業(yè),越攀越高,在國(guó)內(nèi)外無(wú)數(shù)次被證明有效。
但眾所周知,受限于Transformer架構(gòu)本身的底層計(jì)算設(shè)計(jì),在不少場(chǎng)景下,它會(huì)顯得比較笨拙。
譬如在推理模型風(fēng)頭正盛的現(xiàn)在,Transformer模型一旦進(jìn)入推理階段,模型的復(fù)雜度就會(huì)伴隨輸入序列長(zhǎng)度瘋狂增長(zhǎng)。每多處理一個(gè)token,就要額外計(jì)算整段上下文的注意力關(guān)系。
換句話說(shuō),就算你把大模型壓得再小,只要它還是Transformer架構(gòu),上下文長(zhǎng)度變長(zhǎng)、任務(wù)復(fù)雜度提升,推理速度就會(huì)明顯受限,功耗也直線向上狂飆。
如此一來(lái),在手機(jī)、機(jī)器人、IoT終端這類算力有限的設(shè)備,Transformer架構(gòu)模型就不占優(yōu)勢(shì)了。
針對(duì)這個(gè)窘境,目前業(yè)內(nèi)的主要做法,要不是端云協(xié)同,要不就是給云端模型“瘦身”,盡可能壓縮壓縮再壓縮,再擠進(jìn)端側(cè)設(shè)備里。
總而言之,現(xiàn)行主流方法的本質(zhì),仍然是在用云端的思路,來(lái)服務(wù)端側(cè)的現(xiàn)實(shí)。
但RockAI不一樣。
這家公司的辦法不是讓模型適配設(shè)備,而是讓模型直接在設(shè)備上出生和成長(zhǎng)。
前面提到的Yan架構(gòu),就專為端側(cè)而生,RockAI表示, 它的目標(biāo)是讓模型變成設(shè)備的一部分——RockAI稱之為“離線智能”。
所謂離線智能,不是簡(jiǎn)單的“斷網(wǎng)運(yùn)行”,而是模型在本地就能完成理解、推理、甚至學(xué)習(xí)的全流程閉環(huán)系統(tǒng)。
其核心特征有三:
- 全程本地運(yùn)行:推理過程不依賴云端算力,模型部署在設(shè)備上,離線狀態(tài)可用。
- 多模態(tài)理解:能處理語(yǔ)音、圖像、視頻等復(fù)雜輸入,具備較強(qiáng)的本地感知與交互能力。目前,Yan 2.0 Preview能在樹莓派上以5 tokens/s的速度多模態(tài)問答。
- 邊用邊學(xué)的可成長(zhǎng)性:具備訓(xùn)推同步能力,用戶交互中的新信息可被寫入本地模型記憶,實(shí)現(xiàn)逐步成長(zhǎng)。
這么一剖析,就能發(fā)現(xiàn)離線智能的與眾不同之處——
傳統(tǒng)AI是聯(lián)網(wǎng)找大腦,端云協(xié)同是遇到不會(huì)的去問云端,離線智能是只靠自己本身具備的腦子邊理解邊學(xué)習(xí)邊應(yīng)對(duì)。
RockAI表示,端側(cè)大模型不應(yīng)是縮水版的云端大模型。
端側(cè)大模型應(yīng)該是一種創(chuàng)新架構(gòu)的模型,能夠在終端設(shè)備上進(jìn)行本地私有化部署。
其核心能力在于基于多模態(tài)感知實(shí)現(xiàn)自主學(xué)習(xí)與記憶,以提供個(gè)性化服務(wù)并保障數(shù)據(jù)隱私與運(yùn)行安全。說(shuō)到底,RockAI把它視為未來(lái)各類終端設(shè)備真正的大腦。
“記憶”對(duì)未來(lái)終端設(shè)備來(lái)說(shuō)十分重要,是它們真正理解你、陪伴你的關(guān)鍵所在。
具備記憶能力的大模型,能持續(xù)學(xué)習(xí)用戶的習(xí)慣、環(huán)境和情緒,在保護(hù)隱私的前提下,提供更精準(zhǔn)的個(gè)性化服務(wù)。
人類一生都在邊記憶邊成長(zhǎng)。未來(lái)設(shè)備也將借助記憶形成自己的經(jīng)驗(yàn),從而一步步變得有溫度、有判斷力,實(shí)現(xiàn)智能陪伴。
從這個(gè)角度來(lái)看,RockAI的愿景就不止步于拓展模型能力邊界了,這家公司用Yan架構(gòu)大模型押注的還有讓“記憶”成為未來(lái)設(shè)備原生端側(cè)模型的基本素養(yǎng)。
國(guó)內(nèi)非Transformer架構(gòu)模型的落地之王
更重要的是,Yan架構(gòu)并不是一場(chǎng)紙上談兵的重構(gòu)實(shí)驗(yàn),它已經(jīng)在真實(shí)設(shè)備中長(zhǎng)出來(lái)了,也開始動(dòng)起來(lái)了。
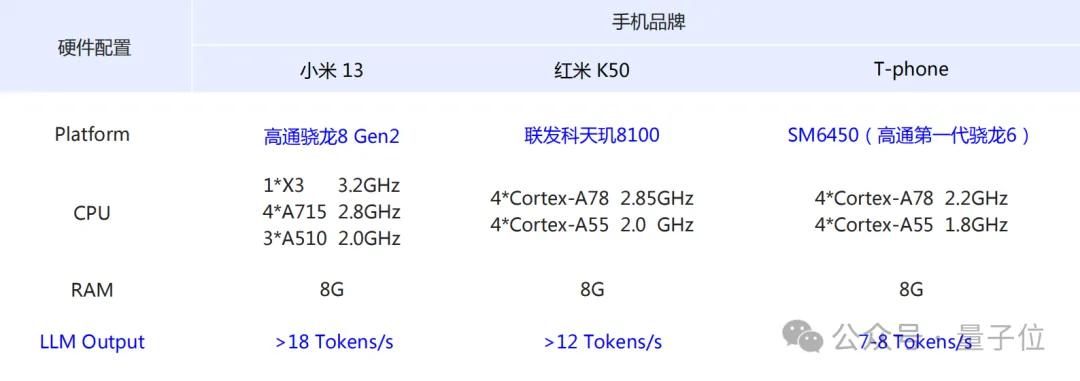
官方消息顯示,不用裁剪、無(wú)須量化,Yan架構(gòu)的系列大模型已經(jīng)跑通了樹莓派、驍龍6系列移動(dòng)芯片、AMD和Intel的PC處理器,甚至是機(jī)器人主控芯片。
而且不僅是技術(shù)上跑起來(lái),商業(yè)世界里也開始真正落地用起來(lái)了。
RockAI表示,與某出海品牌廠商合作的AI PC將在今年下半年正式量產(chǎn)上市,銷往海外。與此同時(shí),該公司與其他品牌合作開發(fā)的終端設(shè)備,也正陸續(xù)進(jìn)入部署節(jié)奏。
在全球范圍內(nèi),在行業(yè)里能真正做到完全非Transformer架構(gòu) + 真端側(cè)落地的公司,RockAI是極少數(shù)之一。
兩年多時(shí)間,他們用一條最不主流的路徑,走出了眼下完整的落地閉環(huán),成為國(guó)內(nèi)非Transformer架構(gòu)模型的落地之王。
但他們要走的路,并不止于讓離線智能商業(yè)落地。
我們了解到,RockAI推出的類腦激活機(jī)制、原生記憶能力、純離線部署,并不是分散的功能點(diǎn),而是通往一個(gè)更遠(yuǎn)方向的三根支柱。
這個(gè)方向就是群體智能(Collective Intelligence)。
在RockAI看來(lái),群體智能是邁向AGI的關(guān)鍵路徑之一。
人類社會(huì)中,個(gè)體具備專長(zhǎng),協(xié)作產(chǎn)生力量,故而RockAI希望智能設(shè)備也能這樣:模型和模型之間通過神經(jīng)元遷移或任務(wù)能力同步實(shí)現(xiàn)協(xié)作,構(gòu)建出一個(gè)有組織、有分工、有反饋的模型群落。
換言之,RockAI構(gòu)想的AI未來(lái),不是一個(gè)巨無(wú)霸式的超級(jí)中心化模型,而是無(wú)數(shù)設(shè)備小腦互聯(lián)互通,共同進(jìn)化。
這種看似激進(jìn)的思路,其實(shí)也正在被越來(lái)越明顯的技術(shù)趨勢(shì)所呼應(yīng)。
隨著效率敏感型場(chǎng)景的需求上升,去年開始,Transformer架構(gòu)模型正被越來(lái)越多國(guó)內(nèi)外主流科技公司關(guān)注并采納。
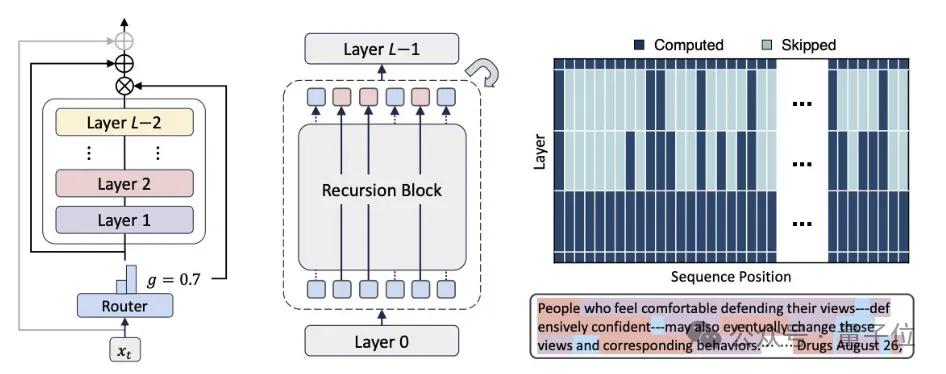
就連Transformer誕生地——谷歌,也在幾天前推出了全新底層架構(gòu)Mixture-of-Recursions(MoR),內(nèi)存減半,推理速度還翻倍,被不少網(wǎng)友戲稱為Transformer Killer。
可以看到,業(yè)界開始集體追問一個(gè)問題:Transformer架構(gòu),是不是走到了一個(gè)分岔點(diǎn)?
對(duì)于RockAI來(lái)說(shuō),這個(gè)問題的答案是肯定的。混合架構(gòu)的大量出現(xiàn),就是行業(yè)潛意識(shí)里對(duì)原有路線“不夠用了”的回應(yīng)。
Transformer仍在狂飆,但非Transformer們也在快速追趕。不同的是,前者在原軌道上提速,后者在開鑿一條新的鐵路。
這條路挺難的。
它要繞開一整個(gè)AI生態(tài)的技術(shù)慣性,要補(bǔ)完新架構(gòu)下的工具鏈、社區(qū)與認(rèn)知成本。
這條路也很孤獨(dú)。
當(dāng)前全球主流模型、硬件接口、訓(xùn)練范式,大多都以Transformer架構(gòu)為中心設(shè)計(jì)。
但正因如此,非Transformer架構(gòu)值得被認(rèn)真對(duì)待——在ChatGPT問世以前,GPT也在T5、BERT的光芒下顯得有些黯然。
所以RockAI相信,只要這條路解決了現(xiàn)實(shí)問題,它就有存在的意義。
如果我們把視線從“這周誰(shuí)開源了新版本和“下一個(gè)基準(zhǔn)測(cè)評(píng)的排行榜”抬起來(lái),以十年甚至三十年的長(zhǎng)遠(yuǎn)視角去看今天,或許,真正照亮這個(gè)端云混戰(zhàn)、架構(gòu)爭(zhēng)鳴的AI深夜的,未必是當(dāng)下最喧嘩的那束光。
也有可能是以后成了共識(shí)之后被標(biāo)記為起點(diǎn)的星星之火。