
Scaling Law不總是適用!尤其在文本分類任務(wù)中,vivo AI Lab提出數(shù)據(jù)質(zhì)量提升解決方法
用近一半數(shù)據(jù),有效提升訓(xùn)練集的訓(xùn)練效率
vivo AI Lab 投稿
量子位 | 公眾號(hào) QbitAI
Scaling Law不僅在放緩,而且不一定總是適用!
尤其在文本分類任務(wù)中,擴(kuò)大訓(xùn)練集的數(shù)據(jù)量可能會(huì)帶來(lái)更嚴(yán)重的數(shù)據(jù)沖突和數(shù)據(jù)冗余。
要是類別界限不夠清晰,數(shù)據(jù)沖突現(xiàn)象就更明顯了。
而文本分類又在情感分析、識(shí)別用戶意圖等任務(wù)中極為重要,繼而對(duì)AI Agent的性能也有很大影響。
最近,vivo AI Lab研究團(tuán)隊(duì)提出了一種數(shù)據(jù)質(zhì)量提升(DQE)的方法,成功提升了LLM在文本分類任務(wù)中的準(zhǔn)確性和效率。

實(shí)驗(yàn)中,DQE方法以更少的數(shù)據(jù)獲得更高的準(zhǔn)確率,并且只用了近一半的數(shù)據(jù)量,就能有效提升訓(xùn)練集的訓(xùn)練效率。
作者還對(duì)全量數(shù)據(jù)微調(diào)的模型和DQE選擇的數(shù)據(jù)微調(diào)的模型在測(cè)試集上的結(jié)果進(jìn)行了顯著性分析。
結(jié)果發(fā)現(xiàn)DQE選擇的數(shù)據(jù)在大多數(shù)測(cè)試集上都比全量數(shù)據(jù)表現(xiàn)出顯著的性能提升。
目前,此項(xiàng)成果已被自然語(yǔ)言處理頂會(huì)COLING 2025主會(huì)接收。
數(shù)據(jù)質(zhì)量提升方法長(zhǎng)啥樣?
在自然語(yǔ)言處理中,文本分類是一項(xiàng)十分重要的任務(wù),比如情感分析、意圖識(shí)別等,尤其現(xiàn)在企業(yè)都在推出各自的AI Agent,其中最重要的環(huán)節(jié)之一,就是識(shí)別用戶的意圖。
不同于傳統(tǒng)的BERT模型,基于自回歸的大語(yǔ)言模型的輸出往往是不可控的,而分類任務(wù)對(duì)輸出的格式要求較高。
通過(guò)在提示詞中加入few-shot可以有效地改善這一現(xiàn)象,但是基于提示詞的方法帶來(lái)的提升往往有限。指令微調(diào)可以有效地改善模型的性能。
在文本分類任務(wù)中,缺乏一種有效的手段來(lái)獲取高質(zhì)量的數(shù)據(jù)集。OpenAI提出了縮放定律(Scaling Law),認(rèn)為大語(yǔ)言模型的最終性能主要取決于三個(gè)因素的縮放:計(jì)算能力、模型參數(shù)和訓(xùn)練數(shù)據(jù)量。
然而這一定律并不總是適用,尤其在文本分類任務(wù)中,擴(kuò)大訓(xùn)練集的數(shù)據(jù)量會(huì)可能會(huì)帶來(lái)更加嚴(yán)重的數(shù)據(jù)沖突現(xiàn)象和數(shù)據(jù)冗余問題。尤其類別的界限不夠清晰的時(shí)候,數(shù)據(jù)沖突的現(xiàn)象更加明顯。
下面是vivo AI Lab團(tuán)隊(duì)提出的數(shù)據(jù)質(zhì)量提升(DQE)方法的具體方法設(shè)計(jì)。
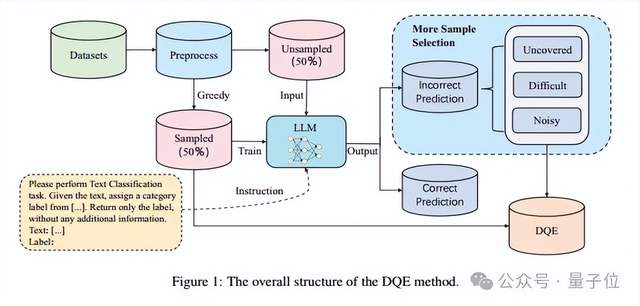
首先,作者對(duì)訓(xùn)練集進(jìn)行了初步的數(shù)據(jù)清洗工作,包含處理具有缺失值的數(shù)據(jù)、query和標(biāo)簽重復(fù)的數(shù)據(jù)以及標(biāo)簽不一致數(shù)據(jù)(同一條query對(duì)應(yīng)多個(gè)不同的標(biāo)簽)。
然后,使用文本嵌入模型,將文本轉(zhuǎn)換為語(yǔ)義向量。再通過(guò)貪婪采樣的方法,隨機(jī)初始化一條數(shù)據(jù)作為初始向量,然后每次選擇距離向量中心最遠(yuǎn)的數(shù)據(jù)加入到新的集合中,以提升數(shù)據(jù)的多樣性。
接著,更新這個(gè)集合的向量中心,不斷的重復(fù)這個(gè)過(guò)程,直到收集了50%的數(shù)據(jù)作為sampled,剩下未被選中的50%的數(shù)據(jù)集作為unsampled,然后使用sampled數(shù)據(jù)集微調(diào)大語(yǔ)言模型預(yù)測(cè)unsampled。
通過(guò)結(jié)合向量檢索的方式,將unsampled中預(yù)測(cè)結(jié)果錯(cuò)誤的數(shù)據(jù)分為Uncovered、Difficult和Noisy三種類型。
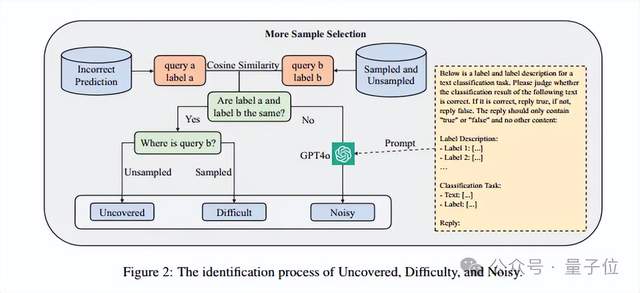
下面是三種類型的數(shù)據(jù)的識(shí)別原理:
Uncovered:主要指sampled中未覆蓋的數(shù)據(jù),如果預(yù)測(cè)錯(cuò)誤的數(shù)據(jù)與最相似的數(shù)據(jù)具有相同的標(biāo)簽,并且最相似的數(shù)據(jù)位于unsampled中,則認(rèn)為該數(shù)據(jù)相關(guān)的特征可能沒有參與sampled模型的微調(diào),從而導(dǎo)致unsampled中的該條預(yù)測(cè)結(jié)果錯(cuò)誤。
Difficult:主要指sampled中難以學(xué)會(huì)的困難樣本,如果預(yù)測(cè)錯(cuò)誤的數(shù)據(jù)與最相似的數(shù)據(jù)具有相同的標(biāo)簽,并且最相似的數(shù)據(jù)位于sampled,則認(rèn)為該數(shù)據(jù)相關(guān)的特征已經(jīng)在sampled中參與過(guò)模型的微調(diào),預(yù)測(cè)錯(cuò)誤可能是因?yàn)檫@條數(shù)據(jù)很難學(xué)會(huì)。
Noisy:主要是標(biāo)簽不一致導(dǎo)致的噪聲數(shù)據(jù),如果預(yù)測(cè)錯(cuò)誤的數(shù)據(jù)與最相似的數(shù)據(jù)具有不同的標(biāo)簽。則懷疑這兩條數(shù)據(jù)是噪聲數(shù)據(jù)。大多數(shù)文本分類任務(wù)的數(shù)據(jù)集都是共同手工標(biāo)注或者模型標(biāo)注獲得,都可能存在一定的主觀性,尤其在類別界限不清晰的時(shí)候,標(biāo)注錯(cuò)誤的現(xiàn)象無(wú)法避免。這種情況下,作者通過(guò)提示詞,使用GPT-4o進(jìn)一步輔助判斷。
效果如何?
作者基于多機(jī)多卡的L40s服務(wù)器上通過(guò)swift框架進(jìn)行了全參數(shù)微調(diào),選擇開源的Qwen2.5-7B-Instruct模型作為本次實(shí)驗(yàn)的基礎(chǔ)模型。
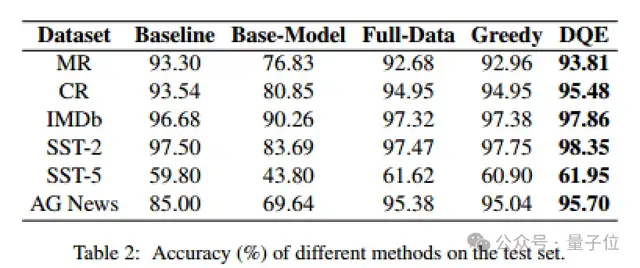
作者與PaperWithCode中收錄的最好的結(jié)果以及全量數(shù)據(jù)微調(diào)的方法進(jìn)行了對(duì)比,作者分別在MR、CR、IMDb、SST-2、SST-5、AG News數(shù)據(jù)集中進(jìn)行了對(duì)比實(shí)驗(yàn)。
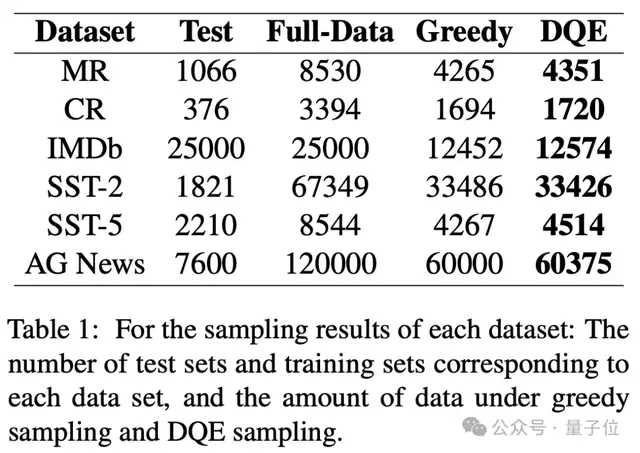
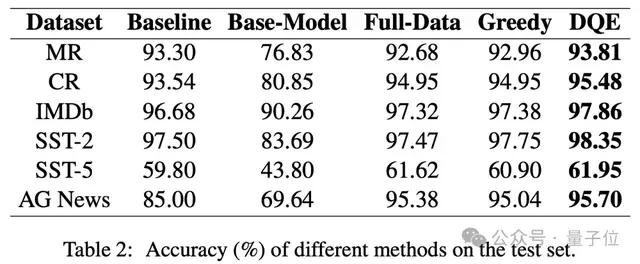
從實(shí)驗(yàn)結(jié)果可以看出,DQE方法以更少的數(shù)據(jù)獲得更高的準(zhǔn)確率,并且只用了近乎一半的數(shù)據(jù)量,可以有效地提升訓(xùn)練集的訓(xùn)練效率。
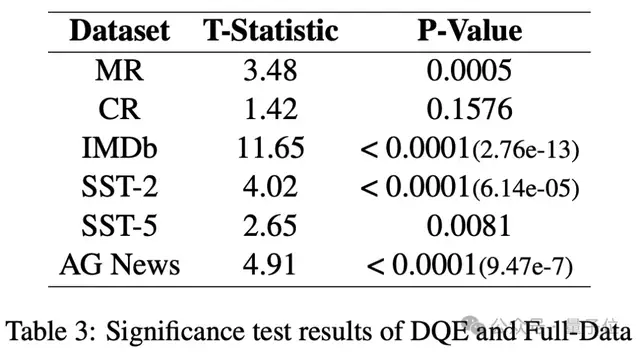
同時(shí),作者頁(yè)進(jìn)一步對(duì)全量數(shù)據(jù)微調(diào)的模型和DQE選擇的數(shù)據(jù)微調(diào)的模型在測(cè)試集上的結(jié)果進(jìn)行了顯著性分析。將預(yù)測(cè)結(jié)果正確的數(shù)據(jù)賦值為1,將預(yù)測(cè)結(jié)果錯(cuò)誤的數(shù)據(jù)賦值為0,通過(guò)t檢驗(yàn)來(lái)評(píng)估模型之間性能差異的統(tǒng)計(jì)顯著性。
從表中可以發(fā)現(xiàn)DQE選擇的數(shù)據(jù)在大多數(shù)測(cè)試集上都比全量數(shù)據(jù)表現(xiàn)出顯著的性能提升。
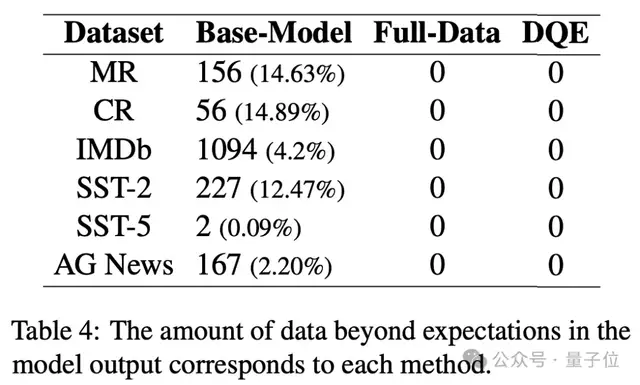
與傳統(tǒng)的BERT模型不同的是,生成式的模型往往是不可控的,作者進(jìn)一步分析了指令跟隨結(jié)果。
結(jié)果表明,不管是全量數(shù)據(jù)微調(diào)還是DQE方法微調(diào),都可以有效地提升大語(yǔ)言模型的指令跟隨能力,按照預(yù)期的結(jié)果和格式輸出。
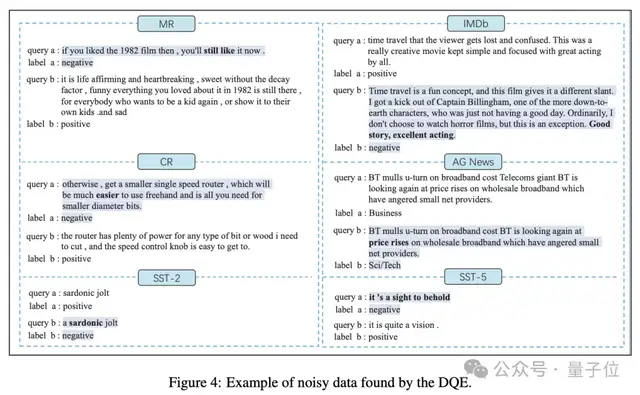
對(duì)于分類任務(wù)來(lái)講,當(dāng)數(shù)據(jù)量足夠大時(shí),很難避免標(biāo)簽噪聲現(xiàn)象。即便是被各大頂級(jí)學(xué)術(shù)期刊和會(huì)議廣泛使用的數(shù)據(jù)集,也無(wú)法避免標(biāo)簽噪聲現(xiàn)象。
作者分析了一部分通過(guò)實(shí)驗(yàn)找出的噪聲數(shù)據(jù),并且給出了開源數(shù)據(jù)集中的標(biāo)簽噪聲的示例。
值得注意的是,在數(shù)據(jù)采樣過(guò)程中,本研究使用貪心算法將數(shù)據(jù)集劃分為sampled和unsampled。此外,作者根據(jù)文本相似度將unsampled分類為uncovered、difficult和noisy數(shù)據(jù)。
接下來(lái),分析sampled中的這三種類型:
由于該數(shù)據(jù)將用于最終的訓(xùn)練集,因此它不包含uncovered。
關(guān)于difficult,將來(lái)自u(píng)nsampled中識(shí)別為difficult的樣本會(huì)加入到最終的訓(xùn)練集,這uncovered中的difficult和sampled是成對(duì)存在的,從而部分減輕了采樣數(shù)據(jù)中的difficult問題。
對(duì)于noisy數(shù)據(jù),使用DQE可以在sampled和unsampled之間識(shí)別出大多數(shù)成對(duì)的噪聲實(shí)例。
由于使用sampled貪婪采樣策略,在sampled內(nèi)遇到成對(duì)的相似噪聲數(shù)據(jù)的概率會(huì)相對(duì)較低。從理論上解釋了本方案的有效性。
論文地址:https://arxiv.org/abs/2412.06575
相關(guān)閱讀


開源Llama版o1來(lái)了,3B小模型反超80B,逆向工程復(fù)現(xiàn)OpenAI新Scaling Law
1B小模型數(shù)學(xué)超過(guò)CS博士生平均分

99.99%準(zhǔn)確率!AI數(shù)據(jù)訓(xùn)練工具No.1來(lái)自中國(guó)
讓AI行業(yè)真正實(shí)現(xiàn)數(shù)據(jù)驅(qū)動(dòng)

Ilya宣判后GPT-5被曝屢訓(xùn)屢敗,一次訓(xùn)數(shù)月,數(shù)據(jù)要人工從頭構(gòu)建
OpenAI已經(jīng)在調(diào)整戰(zhàn)略了

Scaling Law不是唯一視角!清華劉知遠(yuǎn)團(tuán)隊(duì)提出大模型“密度定律”:模型能力密度100天翻番
結(jié)合摩爾定律,可揭示端側(cè)智能巨大潛力



