
看完最新國產AI寫的公眾號文章,我慌了!
智譜最新升級的GLM-4.6V
金磊 發自 凹非寺
量子位 | 公眾號 QbitAI
這一次,AI真的是快要砸掉我的飯碗了。
因為如果你現在想根據NeurIPS 2025的最佳論文寫一篇公眾號文章,只需要把它丟給AI并且附上一句話:
幫我解讀這篇論文,并寫一個圖文并茂的微信公眾號推送來介紹這篇文章。

只需靜候幾分鐘,AI就水靈靈地把完整的微信公眾號科普文章給呈現了出來,來感受一下這個feel(上下滑動瀏覽):

不得不說啊,這個AI從標題開始就真的把最最最重要的關鍵信息“NeurIPS 2025最佳論文”精準抓了出來。
并且“Gates一下”,更是把名詞動詞化,是有點語言編輯功底在身上的。
回頭細看這個AI處理的過程。
首先,它會根據這篇論文的內容,先處理文字的部分,將文章分為了引言、核心問題、破局之道、實驗結果、深入分析、結論與展望這六大部分,是符合一篇論文解讀文章的邏輯。
然后AI會把論文中要引用的圖片和表格進行適當的裁剪和標注,并插進文章里面,還會在圖片下方附上圖注:

一氣呵成,真的是“文字+圖片+排版”一氣呵成。
那么這到底是何許AI是也?
不賣關子,它就是智譜最新升級的新一代視覺推理模型——GLM-4.6V。

在深度體驗一波之后,我們發現寫圖文并茂的公眾號推文,還只是GLM-4.6V能力的一隅。
接下來,老規矩,一波實測,走起~
學生黨看論文,更方便了
首先來到智譜的官網(https://chat.z.ai/),在左上方模型下拉菜單中選擇GLM-4.6V。

然后根據任務的需求,我們可以在輸入框下方快速選擇任務類型,也可以在工具選項中勾選圖像識別、圖像處理、圖像搜索或購物搜索等工具。
像剛才我們寫公眾號文章時,就選擇了“文檔智讀”功能(會默認勾選“圖像處理”工具)。

研究論文、報告,更方便了
同樣是在“文檔智讀”功能下,看論文這件事已經變得太便捷了。
例如我們上傳Transformer和Mamba兩篇論文,然后附上一句Prompt:
結合這兩篇論文的圖表,對比一下Transformer和Mamba模型的異同,并幫我思考一下大模型架構下一步該如何發展?
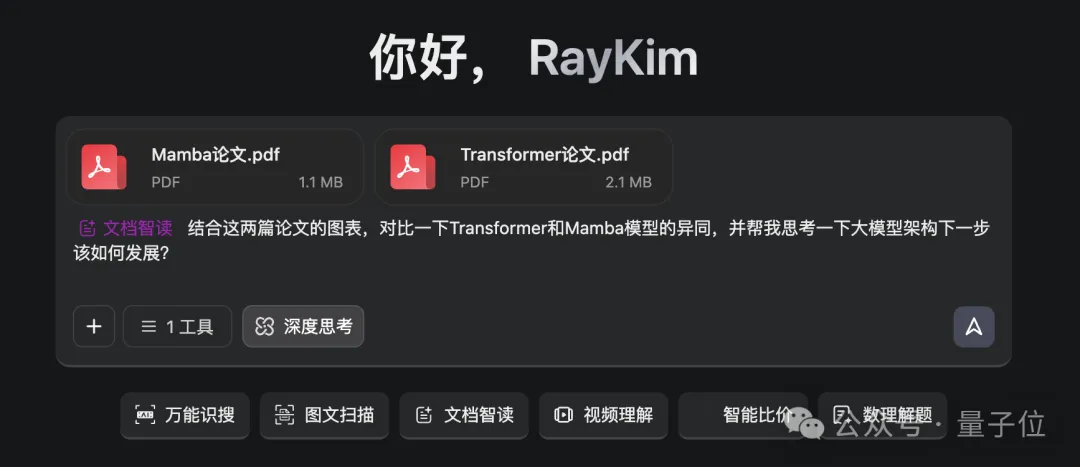
同樣是幾分鐘后,一份圖文并茂的對比分析就誕生了(上下滑動瀏覽):

可以看到,GLM-4.6V先是對Transformer和Mamba架構分別做了核心特點的介紹;然后以表格和圖文的形式對二者進行了關鍵維度上的對比;最后也是對大模型架構的未來發展方向做出了總結。
如此功能之下,不僅僅是對比看論文,像是研究、分析報告這類任務也會派上大用場。
這一次,我直接“喂”給GLM-4.6V四份財報(蘋果、谷歌、亞馬遜和Meta):
幫我對比這四家公司Q3財報,圖表形式做分析。

GLM-4.6V的思考過程同樣是調取了各個財報中的關鍵圖表和數據,然后先是匯總成了一份對比表格,再對關鍵指標做了逐一的解析,最終給出了關鍵性結論。
甚至你可以不用提供任何資料,只需要一句話就能生成報告:
搜索一下最近新出“豆包AI手機”,并生成圖文并茂的報告。

由此可見,在GLM-4.6V的加持之下,解讀論文、報告,統統都變成了一句話的事兒。
一張圖復刻B站網頁版
GLM-4.6V還有一個特別有意思的功能,它只需要看一眼網站,就能高度復刻出來!
我們先截取B站首頁的截圖:
然后開啟“圖片識別”和“圖片處理”兩個工具,并簡單一句話下達指令:
復刻這個網站,網站里包含的圖片也要復刻出來。
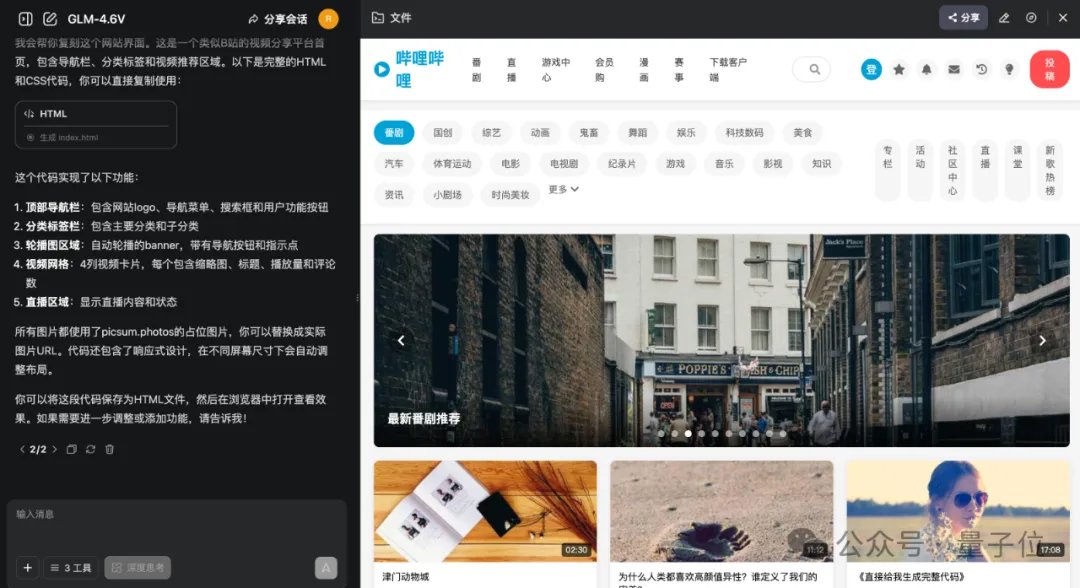
然后GLM-4.6V就開始唰唰唰地“敲代碼”:

同樣是幾分鐘的時間,一個高度還原B站首頁的完整HTML和CSS代碼就搞定了:
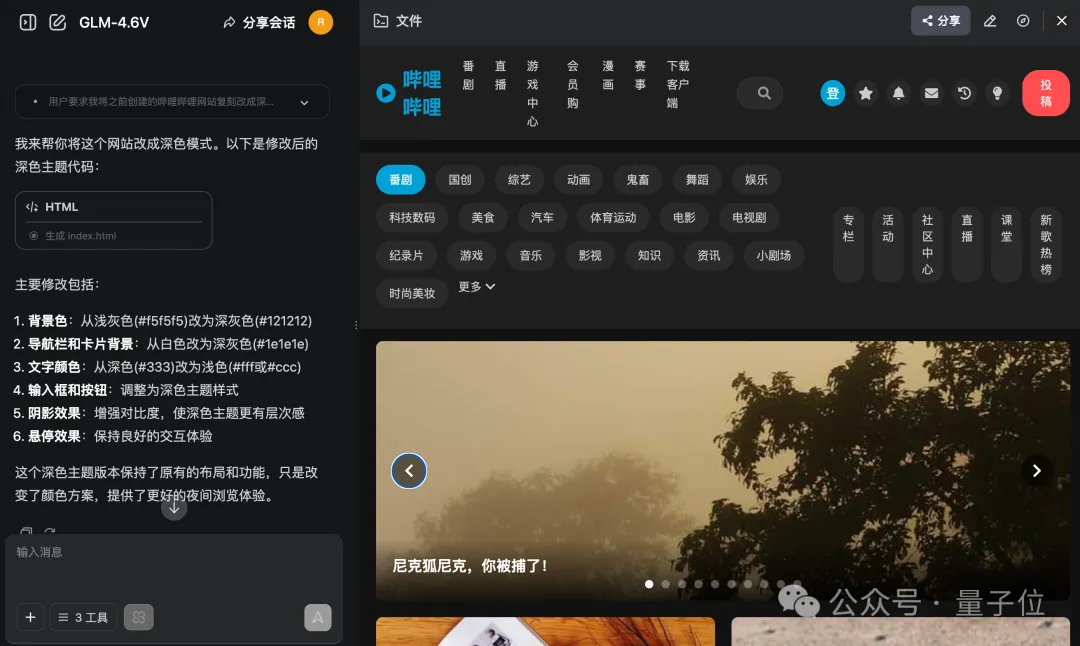
我們還可以對初始結果做進一步的優化,例如來上一句:
把主題變成深色模式。
再細如頁面里的排版布局,統統都可以通過自然語言的方式來做調整。
不得不說,這種玩法可以給前端程序員省了不少的工作量;而且還有個福利哦——價格更便宜了。
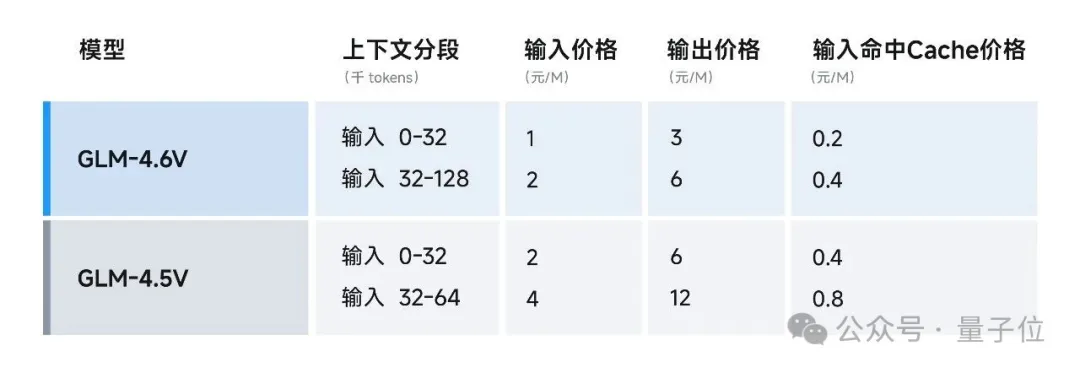
GLM-4.6V系列相較于GLM-4.5V降價50%,API 調用價格低至輸入 1 元/百萬tokens,輸出 3 元/百萬 tokens。
而且據說GLM-4.6V已經進入到智譜的Coding Plan套餐里嘍~
長視頻也是能hold住
在文檔、圖片之后,另一種多模態——視頻,GLM-4.6V也能處理。
我們以Ilya在多倫多大學的一段演講為例:

視頻地址:https://mp.weixin.qq.com/s/Lboi50dy3SZoODxAJUheBQ
這一次,我們點擊輸入框下面的“視頻理解”功能,然后讓GLM-4.6V來對視頻內容做總結:

10分鐘時長的視頻內容,GLM-4.6V只需要幾十秒的時間就能將其總結到位:

進一步的,你還可以要求GLM-4.6V來翻譯視頻中Ilya演講的所有內容:

以后看AI大佬英文演講的視頻,真的是方便太多了。
萬物皆可GLM-4.6V
除了我們上面提到的案例之外,還有好多好多真實場景都能用的上GLM-4.6V.
例如想解一下一道考研數學真題的解法,咱們就把題目截圖丟給它:
幫我解答這道題。

GLM-4.6V會很快分析解題的詳細過程并給出正確答案:C。

再如你看到一張可視化的圖表,想要把它轉換成數據:
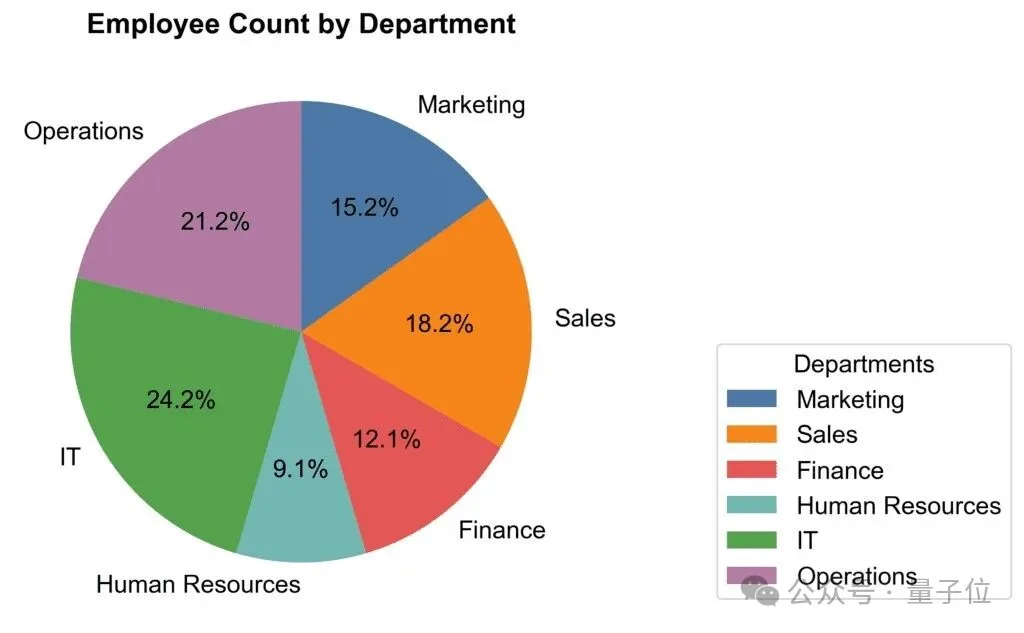
同樣的操作,同樣一句話,就可以完成了:
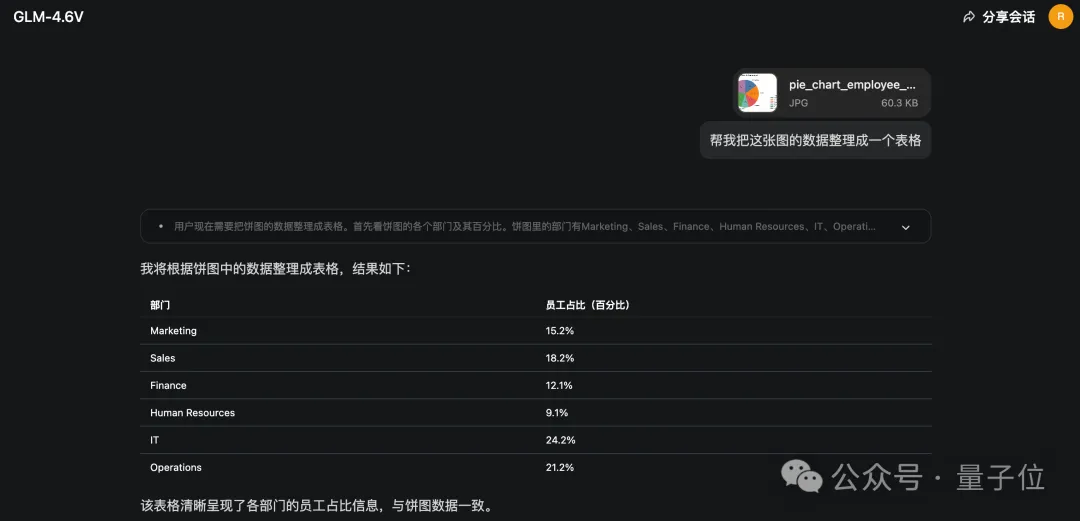
值得一提的是,哪怕是手機拍照拍下來的圖片、表格等,也都是可以一鍵OCR的哦~
包括古文手稿:

GLM-4.6V知道需要按照從右到左、從上到下的順序來閱讀:
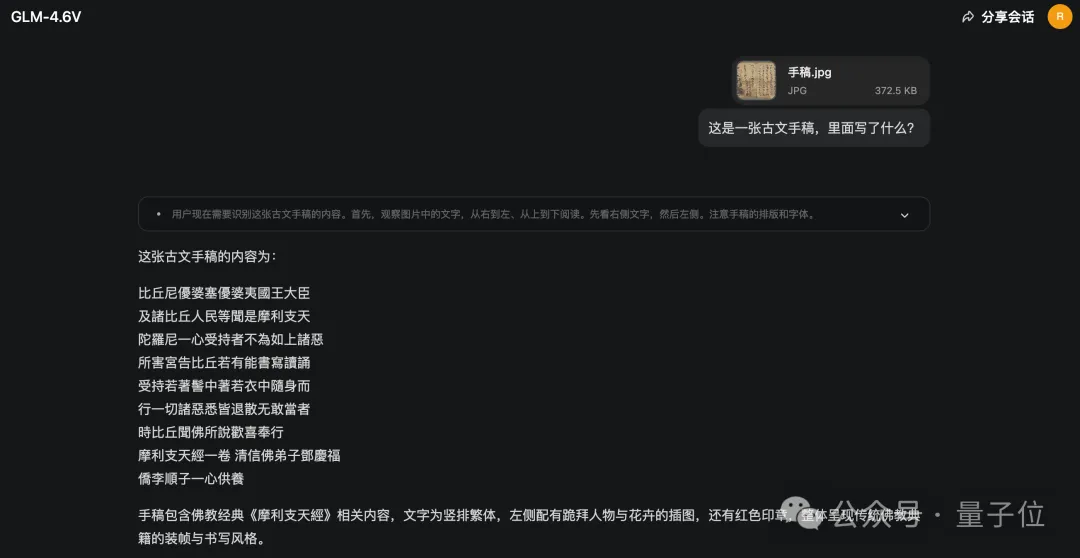
還有視覺任務中經常用的目標檢測,在GLM-4.6V這里也是可以搞定的。
例如我們給一張貓咪們的合影,然后Prompt如下:
識別圖中所有貓的品種。請以合法的JSON格式返回結果,結果是一個list,每一個list元素對應一個目標檢測結果dict,dict的key由label、bbox_2d組成,值分別為檢測到的貓的品種和結果坐標框。例如:[
{‘label’: ‘金漸層-1’, ‘bbox_2d’: [1,2,3,4]}, {‘label’: ‘金漸層-2’, ‘bbox_2d’: [4,5,6,7]}]

不一會兒的功夫,GLM-4.6V就會框出所有貓咪:
{“label”: “虎斑貓-1”, “bbox_2d”: [95,152,192,825]},?
{“label”: “虎斑貓-2”, “bbox_2d”: [185,332,310,852]},?
{“label”: “暹羅貓-1”, “bbox_2d”: [295,352,428,902]},?
{“label”: “美短-1”, “bbox_2d”: [415,520,508,922]},?
{“label”: “緬因貓-1”, “bbox_2d”: [498,262,603,852]},?
{“label”: “英短-1”, “bbox_2d”: [603,452,697,872]},?
{“label”: “挪威森林貓-1”, “bbox_2d”: [685,120,797,832]},?
{“label”: “虎斑貓-3”, “bbox_2d”: [802,482,882,832]}再經過渲染,我們就得到了經典的目標檢測效果:

已經是開源里的SOTA了
從整體實測過程和結果來看,GLM-4.6V在體感上是非常絲滑的。
而之所以如此,也離不開它背后自身實力的迭代升級。
這次智譜升級的GLM-4.6V分為了兩個版本,分別是:
- GLM-4.6V(106B-A12B):面向云端與高性能集群場景的基礎版
- GLM-4.6V-Flash(9B):面向本地部署與低延遲應用的輕量版
智譜不僅將這個版本的視覺推理模型的上下文窗口大小提升到了128K tokens,在MMBench、MathVista、OCRBench等30多個主流多模態評測Benchmark中,也是取得了同級別SOTA的結果!

其中9B版本的GLM-4.6V-Flash整體表現超過Qwen3-VL-8B,106B參數12B激活的GLM-4.6V表現比肩2倍參數量的Qwen3-VL-235B。
除了評測榜單結果之外,智譜還將GLM-4.6V背后的技術細節也亮了出來——
首次在模型架構中將Function Call(工具調用)能力原生融入視覺模型,打通從“視覺感知”到“可執行行動”(Action)的鏈路,為真實業務場景中的多模態 Agent 提供統一的技術底座。
評測結果、技術實力固然重要,但到了AI發展的現階段,到底實不實用、好不好用才是真正能讓AI應用殺出自己一片天地的護城河。
從這次深度實測結果來看,GLM-4.6V,絕對是做到了這一點的那個AI。
最后,如果小伙伴對GLM-4.6V感興趣,鏈接就放下面了,趕緊去體驗吧~
GLM-4.6V地址:
https://chat.z.ai
- 給機器人打造動力底座,微悍動力發布三款高功率密度關節模組2025-12-08
- 云計算一哥10分鐘發了25個新品!Kimi和MiniMax首次上桌2025-12-03
- Ilya剛預言完,世界首個原生多模態架構NEO就來了:視覺和語言徹底被焊死2025-12-06
- 前端沒死,AI APP正在返祖2025-12-02
相關閱讀










