
規格拉滿!Llama和Sora作者都來刷臉的中國AI春晚,還開源了一大堆大模型成果
大模型發展是時候參考前沿研究機構的動向和理解了
魚羊 明敏 發自 凹非寺
量子位 | 公眾號 QbitAI
本周國內最受關注的AI盛事,今日啟幕。
活動規格之高,沒有哪個關心AI技術發展的人能不為之吸引——
Sora團隊負責人Aditya Ramesh與DiT作者謝賽寧同臺交流,李開復與張亞勤爐邊對話,Llama2/3作者Thomas Scialom,王小川、楊植麟等最受關注AI創業者……也都現場亮相。

一年一度,中國“AI春晚”智源大會如約而至,依然AI大佬密度拉滿,依然干貨成果滿滿當當。
從學術向的“語言智能與視覺智能融合創造世界模擬器”,到產業向的“大模型價格戰有何影響”,活動開啟第一個上午,頂級AI學者、專家們的觀點交鋒已經讓線上線下觀眾直呼過癮。

不僅如此,主辦方智源研究院,還拋出了一籮筐重磅新進展,開源開放的那種:
- 萬億稠密模型TeleFLM核心技術、訓練細節、52B版本;
- 原生多模態大模型Emu 3最新成果,以及輕量級圖文多模態模型Bunny的參數、訓練代碼、訓練數據;
- 千萬級高質量指令微調數據集InfinityInstruct;
- ……
大模型趨勢以來,創業公司大廠的動向吸引了諸多關注。
但更回歸技術本身,當下大模型發展還需要關注哪些方面?是時候參考研究機構的動向和理解了。
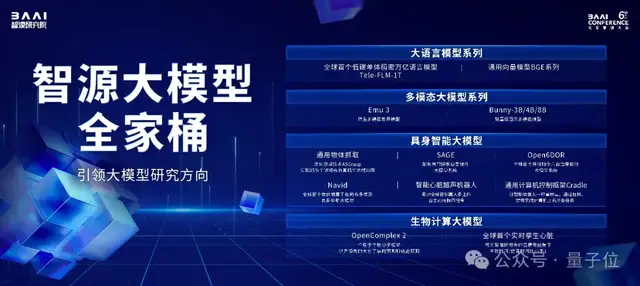
智源大模型“全家桶”發布
智源研究院帶來的最新發布主要有大模型進展以及底層算力基座。
智源大模型“全家桶”由4部分組成:
- 智源語言大模型
- 智源多模態大模型
- 智源具身大模型
- 智源生物計算大模型
首先在大語言模型方面,智源表示不會重復造輪子,最新發布的成果主要面向產業界正面臨的共同難點,比如算力缺乏問題。
智源與中國電信人工智能研究院(TeleAI)聯合研發了基于生長技術訓練的全球首個低碳單體稠密萬億語言模型。

盡管模型參數規模達到萬億級別,但訓練實際只用了112臺A800,這相當于業界普通訓練方案9%的算力資源。
通過優越超參預測技術,訓練全過程零調整、零重試。
目前Tele-FLM 1TB版本還在訓練中,中間版Tele-FLM 52B已開源。
評估結果顯示,在中文方面,Tele-FLM的BPB曲線優于Llama3-70B。英文方面,其BPB評測接近Llama3-70B,優于Llama2-70B。
之后,團隊將開源1TB版本,以及訓練技術細節以及loss曲線。以期為開源社區提供一個優秀的稠密萬億模型的初始參數版本,避免萬億參數模型早期難以收斂等問題。
同時,智源對基于該基座模型訓練出的對話模型Tele-FLM-Chat(52B)進行評測。
AlignBench評測顯示,它已達到GPT-4中文語言能力的96%,總體能力可達GPT-4的80%。現在已在ModelScope上可體驗。

算力之外,大模型應用落地的另一大挑戰是幻覺問題。
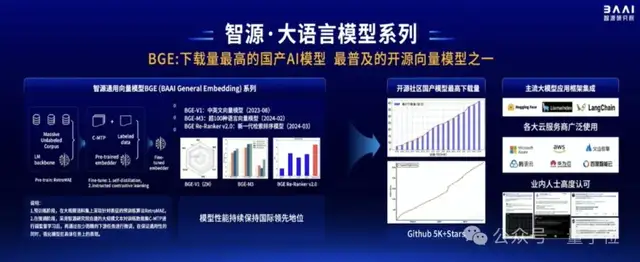
在這方面,智源帶來了通用向量模型BGE(BAAI General Embedding)。
該系列模型如今已是全球范圍內下載量最高的國產AI模型,也是最普及的開源向量模型之一。
它基于無監督預訓練和多階段對比學習,構建了多語言關聯文本數據集C-MTP。
從去年8月發布至今,BGE模型得到了全球主流應用大模型框架的集成,包括Hugging Face、LlamaIndex等。如Azure、AWS、火山引擎、騰訊云、華為云、百度智能云等主流云廠商,也都集成了BGE模型,對外提供商用。
其次,智源聚焦多模態領域,帶來了最新進展——Emu3。
去年7月,智源研究院發布生成式多模態模型Emu,12月迭代至Emu2。
最新發布的Emu3采用自回歸技術路徑,將圖像、視頻、文字共同訓練,統一實現了圖像、視頻、文字的輸入和輸出,并且具備更多模態可擴展性。
它具備圖像生成能力、視頻生成能力:

并且可以理解圖像和視頻內容:

目前,Emu3還在持續訓練中,在經過安全評估后會逐步開源。Emu1和Emu2已經開源。
另外在多模態方面,智源還帶來了一個輕量級圖文模型:Bunny-3B/4B/8B。
該模型采用靈活架構,可基于不同視覺編碼器,如EVA-CLIP、SigLIP;也能基于不同的語言基座模型,比如Phi、StableLM等。
Bunny的模型、數據、代碼將全部開源。

第三,面向具身智能的終局,智源還帶來了一個端到端具身導航大模型,并已在人形機器人上應用。
NaVid是世界首個端到端基于視頻的多模態具身大模型,它實現了“輸入視頻和語言,輸出動作”。它無需離線建圖,是純視覺、純Sim2Real方案,能在虛擬世界中訓練,在現實世界中直接泛化。

另外智源也關注了具身智能幾個關鍵點。
比如通用抓取模型ASGrasp。通過在仿真系統內構建千萬量級場景以及超過10億抓取數據,實現了抓取技術顯著提升,在工業級真機上能夠實現超過95%的抓取成功率,打破世界紀錄,該成果已被ICRA 2024接收。

SAGE模型是一個操作系統大模型,基于三維視覺小模型和圖文大模型,它能讓機器人在操作失敗后進行思考,就像人一樣,然后重新規劃動作,進而完成任務。該模型也被ICRA 2024接收。
Open6DOR則是全球首個開放指令六自由度取放大模型系統,它能讓機器人既關注物體的位置,也考慮物體的姿態,從而讓抓取更有效。
基于如上成果,智源的具身智能已經可以理解人類的指令并進行對話、執行任務,比如在聽到人類說“我渴了/我餓了”之后,它會遞上可樂或橘子。

在實際落地方面,智源還與清華大學301研究院帶來了全球首創智能心臟超聲機器人。
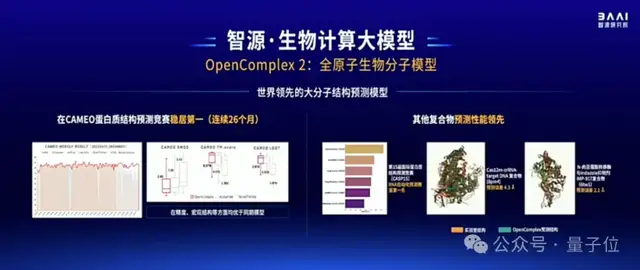
最后,在生物計算方面,智源發布了OpenComplex2全原子生物分子模型。
這是一個decoder-only模型,它基于生成式AI,能在原子層面對RNA、DNA等小分子的結構和相互關系進行預測,精度可達超算水平。
在CAMEO蛋白質結構預測競賽中,OpenComplex已經連續26個月穩居第一,在精度和宏觀結構等方面均優于同期模型(如AlphaFold2)。同時也能對RNA、DNA、蛋白質復合物進行預測。
在與超算結果的對比中顯示,OpenComplex已經初步具備通路預測能力。
以上便是智源在過去一年中在大模型領域方面的進展。
帶來這些進展其實都離不開底層算力基座的支持。
去年,智源發布了FlagOpen1.0。這是一個面向異構芯片、支持多種框架的大模型全棧開源技術基座。
今年FlagOpen升級至2.0版本。在1.0的基礎上,進一步完善了模型、數據、算法、評測、系統五大版圖布局,旨在打造大模型時代的Linux。

同時,智源也構建了為大模型而生、支持異構芯片的算力集群“操作系統”FlagOS。

它包括異構算力智能調度管理平臺九鼎、支持多元AI異構算力的并行訓推框架FlagScale、支持多種AI芯片架構的高性能算子庫FlagAttention和FlagGems,集群診斷工具FlagDiagnose和AI芯片評測工具FlagPerf。
可向上支撐大模型訓練推理評測等,向下管理底層異構算力、高速網絡、分布式存儲等。
目前,FlagOS已支持了超過50個團隊的大模型研發,支持8種芯片,管理超過4600個AI加速卡,穩定運行20個月,SLA超過99.5%。
此外,智源研究院還推出了開源Triton算子庫、首個千萬級高質量開源指令微調數據集InfinityInstruct、全球最大開源中英文多行業數據集IndustryCorpus等等新進展。
可見在過去一年中,智源研究院的腳步走得非常快、且布局廣泛。
而值得關注的是,在發布新進展同時,智源研究院這一國內頂級AI研究機構,此次也明確地公布了對未來技術趨勢的判斷。
面向更前沿技術問題
與大模型領域的工業界玩家不同,智源研究院是一家非營利研究機構,相較于短期應用,更聚焦AI的前沿研究。
在與智源研究院院長王仲遠的交流中,他對此解釋說:
企業已經在做的事,智源不會做,而是聚焦于更前沿的技術問題。

總結起來,智源對技術路線發展的判斷很明確:
在基礎模型層面上,是要解決大語言模型發展過程中面臨的核心痛點。
比如算力問題。
2023年9月,智源研究院就聯合中科院計算所、南洋理工大學、電子科技大學、哈爾濱工業大學等研究團隊,提出了一種“生長策略”(growth strategy)。
簡單來說,基于生長策略,模型的參數量在訓練過程中并不是固定的,而是可以隨著訓練進行,從較小的參數規模擴展到更大的參數規模。
這次發布的稠密萬億參數語言模型Tele-FLM,就是通過生長技術來訓練的。王仲遠透露,訓練這一模型只用了112臺A800,也就是不到1000張卡。
又比如多模態問題。
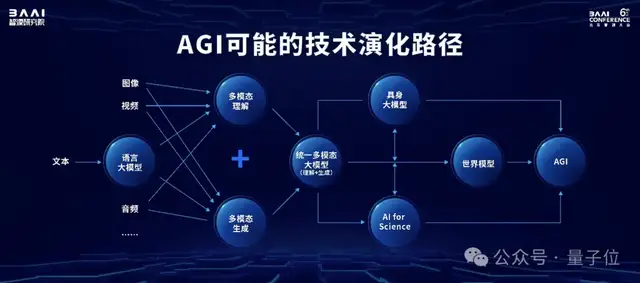
盡管多模態已經成為當下大模型發展的主流方向,但在現階段,很多多模態大模型其實是單一跨模態模型,無法同時實現視頻、圖片的生成和理解。
智源的Emu項目,旨在最終實現原生多模態世界模型。
從訓練數據的角度,從一開始,文字、圖像、視頻數據就被放在一起聯合訓練;從技術路線的角度,智源也選擇了難度更高的自回歸路線而非Sora帶火的DiT路線。
我們認為,像OpenAI,未來也可能會將ChatGPT和Sora做進一步的融合。
從技術判斷上,我們想要瞄準真正的多模態大模型,因此選擇了自回歸這樣一個我們認為終極的技術路線。
而在更具體的應用層面上,重點關注具身智能和生物計算, 也并非是單純追熱點。
王仲遠甚至主動降了一波預期:
大家要客觀理性地來看待技術的發展周期,具身智能未來幾年內也可能進入低谷。但我們堅信智能體會從數字世界進入到物理世界。
有此布局的核心原因還是要做“原始的創新”、“集中資源關注核心技術的突破”,智源研究院認為,數字世界的智能體進入物理世界,主要有兩條路線:
一是在宏觀世界賦能硬件,也就是具身智能。
二是進入微觀世界,也就是用大模型對生命分子進行研究。
這兩條技術路線“會跟世界模型相互促進,并且最終實現AGI”。
值得關注的是,在更面向未來的技術路線選擇之外,智源研究院在最新發布中,再次強調了開源開放。
比如Tele-FLM的核心技術“生長策略”,其技術細節此前就已完全公開。此番發布的多模態圖文模型Bunny,同樣是基座模型、模型參數、訓練代碼、訓練數據全部開源。Tele-FLM的萬億參數版本和Emu 3也計劃在安全評估之后對外開源。
事實上,無論是高舉高打的技術布局思路,還是一以貫之的技術共享模式,都是智源研究院創立之始就刻寫在基因里的。
2018年,智源研究院作為人工智能領域的新型研發機構正式成立,其使命可以概括為:
- 推動5大源頭創新,包括基礎理論、學術思想、頂尖人才、企業創新和發展政策。
- 改變人工智能下一個10年,包括人才到生態,成果到系統。
- 創造30年后依然有價值的代表作:判斷人工智能發展大方向,創造經得起時間檢驗的代表作。
2020年,智源“悟道”項目立項。2021年3月,悟道1.0發布,智源研究院正式使用“大模型”這個說法,此后被業界廣泛采納。
而悟道系列開源大模型,也成為過去一年中國產大模型快速發展的技術基石之一。一方面,悟道的7個開源模型成果涵蓋文本類、圖文類、蛋白質類等多個領域,在發布時連續創下“中國首個+世界最大”記錄。另一方面,悟道系列也為中國大模型產業培養了一大批大模型人才,不少現如今在產業界擔當主力的大模型研究者,都是“智源系”出身。
可以說,智源研究院是最早系統布局大模型研究的國內科研機構之一,是中國大模型研究的啟蒙先行者。
大會現場,幾位國內AI大咖也對此有頗多感慨。
楊植麟提到,智源研究院至少是在亞洲地區最早投入、而且真的投入去做大模型的機構。
這是非常難得、非常領先的一個想法。
王小川覺得,智源在中國大模型產業中有著非常好的定位。
智源既有技術高度,又有智庫的角色。這兩方面有獨有的意義,在生態里能夠幫助我們更加快速健康的發展。
李大海則提到,在大模型領域的快速發展過程中,有一些事可能商業公司沒有動力、沒有資源去做。從創企角度出發,非常期待在智源的撮合跟帶領下,搭建一個更好的平臺,把需要做好的事情一起協作好。
張鵬表示,非常非常希望跟智源長期在學術研究、落地應用合作,甚至包括公共政策相關方面繼續保持合作,也祝愿智源大會越辦越好。
也正是這樣的技術領導力和技術影響力,使得智源研究院成為國內最具國際號召力的研究機構之一。一年一度的智源大會,已然成為國內國際頂尖AI學者交流的重要平臺。
2019年首屆智源大會起,每年都不乏圖靈獎得主、明星項目大咖、行業關鍵人物現身這場“AI春晚”。深度學習三巨頭、貝葉斯網絡提出者Judea Pearl、RISC-V掌門人David Patterson……都曾先后參與其中,帶來精彩觀點的碰撞。
今年,是智源大會舉辦的第6年,現場依舊爆滿,足見其在AI從業者和相關專業學生中的影響力。

如果說,過去頂級的AI學術、交流活動都遠在大洋彼岸,現在,就在中國,就在北京,以智源大會為代表,我們也有了屬于自己的頂級AI盛會。
在探討多模態大模型、AGI的全體大會之外,今年的智源大會依然圍繞大家最關注的前沿技術問題,設置了大模型產業技術、Agent、具身智能、數據新基建等等分論壇和技術報告。
如果你感興趣,更多詳情,可以關注:
https://2024.baai.ac.cn/schedule
— 完 —
- 蘋果芯片主管也要跑路!庫克被曝出現健康問題2025-12-07
- 世界模型和具身大腦最新突破:90%生成數據,VLA性能暴漲300%|開源2025-12-02
- 谷歌新架構突破Transformer超長上下文瓶頸!Hinton靈魂拷問:后悔Open嗎?2025-12-05
- 90后華人副教授突破30年數學猜想!結論與生成式AI直接相關2025-11-26
相關閱讀





群星璀璨!2023智源大會6月9日正式啟航
2023智源大會現場,將會有圖靈獎得主Yann LeCun等領銜探討大模型發展現狀與未來趨勢;圖靈獎得主Joseph Sifakis,Midjourney創始人David Holz,中國工程院院士鄭南寧,智源研究院理事長張宏江,清華大學智能產業研究院(AIR)院長張亞勤,智源研究院院長黃鐵軍,智源首席科學家、清華大學教授朱軍等將進行一系列面向未來的特邀報告與尖峰對話。





