
國(guó)產(chǎn)大模型高考出分了:裸分683,選清華還是北大?
高考全科目評(píng)測(cè)來(lái)了
金磊 發(fā)自 凹非寺
量子位 | 公眾號(hào) QbitAI
這兩天啊,各地高考的成績(jī)終于是陸續(xù)公布了。
現(xiàn)在,也是時(shí)候揭曉全球第一梯隊(duì)的大模型們的“高考成績(jī)”了——
我們先來(lái)看下整體的情況(該測(cè)試由字節(jié)跳動(dòng)Seed團(tuán)隊(duì)官方發(fā)布):

按照傳統(tǒng)文理分科計(jì)分方式,Gemini的理科總成績(jī)655分,在所有選手里排名第一。豆包的文科總成績(jī)683分,排名第一,理科總成績(jī)是648分,排名第二。
再來(lái)看下各個(gè)細(xì)分科目的成績(jī)情況:

除了數(shù)學(xué)、化學(xué)和生物之外,豆包的成績(jī)依舊是名列前茅,6個(gè)科目均是第一。
不過其它AI選手的表現(xiàn)也是比較不錯(cuò),可以說(shuō)是達(dá)到了優(yōu)秀學(xué)生的水準(zhǔn)。
比較遺憾的選手就要屬O3,因?yàn)樗?strong>語(yǔ)文寫作上跑了題,因此語(yǔ)文成績(jī)僅95分,拉低了整體的分?jǐn)?shù)。
若是從填報(bào)志愿角度來(lái)看,因?yàn)檫@套測(cè)試采用的是山東省的試卷,根據(jù)過往經(jīng)驗(yàn)判斷,3門自選科目的賦分相比原始分會(huì)有一定程度的提高,尤其是在化學(xué)、物理等難度較大的科目上。本次除化學(xué)成績(jī)相對(duì)稍低外,豆包的其余科目組合的賦分成績(jī)最高能超過690分,有望沖刺清華、北大。
(賦分規(guī)則:將考生選考科目的原始成績(jī)按照一定比例劃分等級(jí),然后將等級(jí)轉(zhuǎn)換為等級(jí)分計(jì)入高考總分)
好,那現(xiàn)在的豆包面臨的抉擇是:上清華還是上北大?

大模型參加高考,分?jǐn)?shù)怎么判?
在看完成績(jī)之后,或許很多小伙伴都有疑惑,這個(gè)評(píng)測(cè)成績(jī)到底是怎么來(lái)的。
別急,我們這就對(duì)評(píng)測(cè)標(biāo)準(zhǔn)逐條解析。
首先在卷子的選擇上,由于目前網(wǎng)絡(luò)流出的高考真題都是非官方的,而山東是少數(shù)傳出全套考卷的高考大省;因此主科(即語(yǔ)文、數(shù)學(xué)、英語(yǔ))采用的是今年的全國(guó)一卷,副科采用的則是山東卷,滿分共計(jì)750分。
其次在評(píng)測(cè)方式上,都是通過API測(cè)試,不會(huì)聯(lián)網(wǎng)查詢,評(píng)分過程也是參考高考判卷方式,就是為了檢驗(yàn)?zāi)P妥陨淼姆夯芰Γ?/p>
- 選擇題、填空題
- 采用機(jī)評(píng)(自動(dòng)評(píng)估)加人工質(zhì)檢的方式;
- 開放題
- 實(shí)行雙評(píng)制,由兩位具有聯(lián)考閱卷經(jīng)驗(yàn)的重點(diǎn)高中教師匿名評(píng)閱,并設(shè)置多輪質(zhì)檢環(huán)節(jié)。
在給模型打分的時(shí)候,采用的是 “3門主科(語(yǔ)文數(shù)學(xué)英語(yǔ))+3門綜合科(理綜或文綜)” 的總分計(jì)算方式,給五個(gè)模型排了個(gè)名次。
值得一提的是,整個(gè)評(píng)測(cè)過程中,模型們并沒有用任何提示詞優(yōu)化技巧來(lái)提高模型的表現(xiàn),例如要求某個(gè)模型回答得更詳細(xì)一些,或者刻意說(shuō)明是高考等等。
最后,就是在這樣一個(gè)公平公正的環(huán)境之下,從剛才我們展示的結(jié)果來(lái)看,Gemini、豆包相對(duì)其他AI來(lái)說(shuō)取得了較優(yōu)的成績(jī)。
細(xì)分科目表現(xiàn)分析
了解完評(píng)測(cè)標(biāo)準(zhǔn)之后,我們繼續(xù)深入解讀一下AI選手們?cè)诟鱾€(gè)科目上的表現(xiàn)。
由于深度思考的大火,大模型們?cè)?strong>數(shù)學(xué)這樣強(qiáng)推理科目上的能力明顯要比去年好很多(此前大部分均不及格),基本上都能達(dá)到140分的成績(jī)。
不過在一道不算難的單選題(全國(guó)一卷第6題)上,國(guó)內(nèi)外的大模型們卻都栽了跟頭:
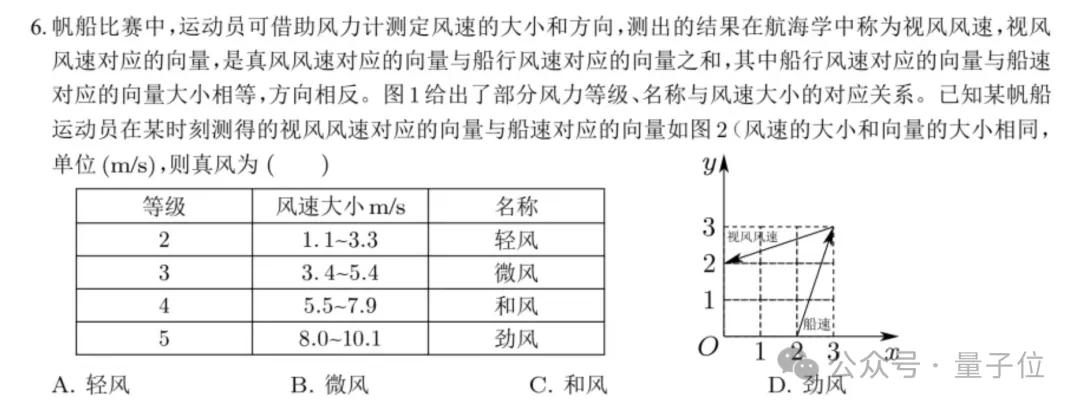
這道題大模型們給出的答案是這樣的:
豆包:C;Gemini:B;Claude:C;O3:C;DeepSeek:C。
但這道題的正解應(yīng)該是A,因此大模型們?cè)诖巳姼矝]。
之所如此,主要是因?yàn)轭}目里有方框、虛線、箭頭和漢字混在一起的圖,模型認(rèn)不準(zhǔn)圖像,說(shuō)明它們?cè)?“看圖說(shuō)話” 這塊還有進(jìn)步空間。
以及在更難的壓軸大題上,很多大模型也沒完全拿下,經(jīng)常漏寫證明過程,或者推導(dǎo)不嚴(yán)謹(jǐn)被扣分,說(shuō)明在細(xì)節(jié)上還需加強(qiáng)。
到做語(yǔ)文選擇題和閱讀題這兩個(gè)版塊,大模型們幾乎是 “學(xué)霸本霸”,得分率超高。
不過在作文寫作過程也暴露出了一些問題,例如寫作過于刻板、文字冰冷,文章字?jǐn)?shù)不達(dá)標(biāo)(不足800字或超過1200字)、立意不對(duì),形式上還經(jīng)常會(huì)出現(xiàn)慣用的小標(biāo)題。

在英語(yǔ)測(cè)試過程中,大模型們幾乎挑不出毛病,唯一扣分點(diǎn)是在寫作上,比如用詞不夠精準(zhǔn)、句式稍顯單調(diào),但整體已經(jīng)很接近完美。
對(duì)于理綜,遇到帶圖的題目大模型們還是會(huì)犯難,不過豆包和Gemini這倆模型在看圖像和理解圖的能力上會(huì)比其他模型強(qiáng)一些。
例如下面這道題中,正確答案應(yīng)當(dāng)是C,大模型們的作答是這樣的:
豆包:C;Gemini:C;Claude:D;O3:D;DeepSeek:D。

最后在文綜方面,大模型的地域差別就顯現(xiàn)得比較明顯,國(guó)外的大模型做政治、歷史題時(shí),經(jīng)常搞不懂題目在考啥,對(duì)中國(guó)的知識(shí)點(diǎn)不太 “感冒”。
而對(duì)于地理題,最頭疼的便是分析統(tǒng)計(jì)圖和地形圖,得從圖里精準(zhǔn)提取信息再分析。
以上就是對(duì)于本次評(píng)測(cè)的全面分析了。
除了今年國(guó)內(nèi)的高考之外,這幾位“參賽選手”還參加了印度理工學(xué)院的第二階段入學(xué)考試——JEE Advanced。
這場(chǎng)考試每年有數(shù)百萬(wàn)人參與第一階段考試,其中前25萬(wàn)考生可晉級(jí)第二階段。它分為兩場(chǎng),每場(chǎng)時(shí)長(zhǎng)3小時(shí),同時(shí)對(duì)數(shù)學(xué)、物理、化學(xué)三科進(jìn)行考察。
題目以圖片形式呈現(xiàn),重點(diǎn)考查模型的多模態(tài)處理能力與推理泛化能力。所有題目均為客觀題,每道題進(jìn)行5次采樣,并嚴(yán)格按照J(rèn)EE考試規(guī)則評(píng)分——答對(duì)得分、答錯(cuò)扣分,不涉及格式評(píng)分標(biāo)準(zhǔn)。
與全印度人類考生成績(jī)對(duì)比顯示,第一名得分332分,第十名得分317分。
值得注意的是,豆包與Gemini已具備進(jìn)入全印度前10的實(shí)力:Gemini在物理和化學(xué)科目中表現(xiàn)突出,而豆包在數(shù)學(xué)科目5次采樣中實(shí)現(xiàn)全對(duì)。

怎么做到的?
相比去年一本線上下的水平,整體來(lái)看,大模型們?cè)诮衲旮呖碱}上的表現(xiàn)均有明顯的進(jìn)步。
那么它們到底是如何提升能力的?我們不妨以拿下單科第一最多的豆包為例來(lái)了解一下。
豆包大模型1.6系列,是字節(jié)跳動(dòng)Seed團(tuán)隊(duì)推出的兼具多模態(tài)能力與深度推理的新一代通用模型。
團(tuán)隊(duì)讓它能力提升的技術(shù)亮點(diǎn),我們可以歸結(jié)為三招。
第一招:多模態(tài)融合與256K長(zhǎng)上下文能力構(gòu)建
Seed1.6延續(xù)了Seed1.5在稀疏MoE(混合專家模型)領(lǐng)域的技術(shù)積累,采用23B激活參數(shù)與230B總參數(shù)規(guī)模進(jìn)行預(yù)訓(xùn)練。其預(yù)訓(xùn)練過程通過三個(gè)階段實(shí)現(xiàn)多模態(tài)能力融合與長(zhǎng)上下文支持:
- 第一階段:純文本預(yù)訓(xùn)練
以網(wǎng)頁(yè)、書籍、論文、代碼等數(shù)據(jù)為訓(xùn)練基礎(chǔ),通過規(guī)則與模型結(jié)合的數(shù)據(jù)清洗、過濾、去重及采樣策略,提升數(shù)據(jù)質(zhì)量與知識(shí)密度。 - 第二階段:多模態(tài)混合持續(xù)訓(xùn)練(MMCT)
進(jìn)一步強(qiáng)化文本數(shù)據(jù)的知識(shí)與推理密度,增加學(xué)科、代碼、推理類數(shù)據(jù)占比,同時(shí)引入視覺模態(tài)數(shù)據(jù),與高質(zhì)量文本混合訓(xùn)練。 - 第三階段:長(zhǎng)上下文持續(xù)訓(xùn)練(LongCT)
通過不同長(zhǎng)度的長(zhǎng)文數(shù)據(jù)逐步擴(kuò)展模型序列長(zhǎng)度,將最大支持長(zhǎng)度從32K提升至256K。
通過模型架構(gòu)、訓(xùn)練算法及Infra的持續(xù)優(yōu)化,Seed1.6 base模型在參數(shù)量規(guī)模接近的情況下,性能較Seed1.5 base實(shí)現(xiàn)顯著提升,為后續(xù)后訓(xùn)練工作奠定基礎(chǔ)。
這一招的發(fā)力,就對(duì)諸如高考語(yǔ)文閱讀理解、英語(yǔ)完形填空和理科綜合應(yīng)用題等的作答上起到了提高準(zhǔn)確率的作用,因?yàn)樗鼈兺婕伴L(zhǎng)文本且看重上下文理解。
第二招:多模態(tài)融合的深度思考能力
Seed1.6-Thinking 延續(xù)Seed1.5-Thinking的多階段RFT(強(qiáng)化反饋訓(xùn)練)與RL(強(qiáng)化學(xué)習(xí))迭代優(yōu)化方法,每輪RL以上一輪RFT為起點(diǎn),通過多維度獎(jiǎng)勵(lì)模型篩選最優(yōu)回答。相較于前代,其升級(jí)點(diǎn)包括:
- 拓展訓(xùn)練算力,擴(kuò)大高質(zhì)量數(shù)據(jù)規(guī)模(涵蓋 Math、Code、Puzzle 等領(lǐng)域);
- 提升復(fù)雜問題的思考長(zhǎng)度,深度融合VLM能力,賦予模型清晰的視覺理解能力;
- 引入parallel decoding技術(shù),無(wú)需額外訓(xùn)練即可擴(kuò)展模型能力 —— 例如在高難度測(cè)試集Beyond AIME中,推理成績(jī)提升8分,代碼任務(wù)表現(xiàn)也顯著優(yōu)化。
這種能力直接對(duì)應(yīng)高考中涉及圖表、公式的題目,如數(shù)學(xué)幾何證明、物理電路圖分析、地理等高線判讀等;可以快速定位關(guān)鍵參數(shù)并推導(dǎo)出解題路徑,避免因單一模態(tài)信息缺失導(dǎo)致的誤判。
第三招:AutoCoT解決過度思考問題
深度思考依賴Long CoT(長(zhǎng)思維鏈)增強(qiáng)推理能力,但易導(dǎo)致 “過度思考”—— 生成大量無(wú)效token,增加推理負(fù)擔(dān)。
為此,Seed1.6-AutoCoT提出 “動(dòng)態(tài)思考能力”,提供全思考、不思考、自適應(yīng)思考三種模式,并通過RL訓(xùn)練中引入新獎(jiǎng)勵(lì)函數(shù)(懲罰過度思考、獎(jiǎng)勵(lì)恰當(dāng)思考),實(shí)現(xiàn)CoT長(zhǎng)度的動(dòng)態(tài)壓縮。
在實(shí)際測(cè)試中:
- 中等難度任務(wù)(如 MMLU、MMLU pro)中,CoT 觸發(fā)率與任務(wù)難度正相關(guān)(MMLU 觸發(fā)率37%,MMLU pro觸發(fā)率70%);
- 復(fù)雜任務(wù)(如AIME)中,CoT觸發(fā)率達(dá)100%,效果與Seed1.6-FullCoT相當(dāng),驗(yàn)證了自適應(yīng)思考對(duì)Long CoT推理優(yōu)勢(shì)的保留。
以上就是豆包能夠在今年高考全科目評(píng)測(cè)中脫穎而出的原因了。
不過除此之外,還有一些影響因素值得說(shuō)道說(shuō)道。
正如我們剛才提到的,化學(xué)和生物的題目中讀圖題占比較大,但因非官方發(fā)布的圖片清晰度不足,會(huì)導(dǎo)致多數(shù)大模型的表現(xiàn)不佳;不過Gemini2.5-Pro-0605的多模態(tài)能力較突出,尤其在化學(xué)領(lǐng)域。
不過最近,字節(jié)Seed團(tuán)隊(duì)在使用了更清晰的高考真題圖片后,以圖文結(jié)合的方式重新測(cè)試了對(duì)圖片理解要求較高的生物和化學(xué)科目,結(jié)果顯示Seed1.6-Thinking的總分提升了近30分(理科總分達(dá)676)。

△圖文交織輸入示例
這說(shuō)明,全模態(tài)推理(結(jié)合文本與圖像)能顯著釋放模型潛力,是未來(lái)值得深入探索的方向。
那么你對(duì)于這次大模型們的battle結(jié)果有何看法?歡迎大家拿真題去實(shí)測(cè)后,在評(píng)論區(qū)留言你的感受~
評(píng)分明細(xì)詳情:
https://bytedance.sg.larkoffice.com/sheets/QgoFs7RBjhnrUXtCBsYl0Jg2gmg
相關(guān)閱讀

陶哲軒支持!AI奧林匹克數(shù)學(xué)獎(jiǎng)來(lái)了,獎(jiǎng)金500萬(wàn)美元,尋找能得IMO金牌的大模型
PK人類數(shù)學(xué)天才



AI對(duì)齊全面綜述!北大等從800+文獻(xiàn)中總結(jié)出四萬(wàn)字,多位知名學(xué)者掛帥
北大劍橋CMU等聯(lián)手

次10萬(wàn)token!GPT4最強(qiáng)對(duì)手史詩(shī)升級(jí),百頁(yè)資料一分鐘總結(jié)完畢
反向開卷GPT-4,還卷對(duì)了方向




