
何愷明新作:給擴散模型加正則化,無需預訓練無需數據增強,超簡單實現性能提升
可以即插即用
魚羊 發自 凹非寺
量子位 | 公眾號 QbitAI
擴散模型風頭正盛,何愷明最新論文也與此相關。
研究的是如何把擴散模型和表征學習聯系起來——
給擴散模型加上“整理收納”功能,使其內部特征更加有序,從而生成效果更加自然逼真的圖片。

具體來說,論文提出了Dispersive Loss——一種即插即用的正則化方法。
核心思想是,在模型輸出的標準回歸損失(如去噪)外,引入一個目標函數,用于對模型的中間表示進行正則化。
這有點類似于對比學習中的排斥效應。但相較于對比學習,其獨特的優勢在于:
- 無需正樣本對,避免了對比學習中的復雜性;
- 具有高度通用性,可以直接應用于現有擴散模型,不需要修改模型結構;
- 計算開銷低,幾乎不增加額外的計算成本;
- 與原始損失兼容,不干擾擴散模型原有的回歸訓練目標,易于在現有框架中集成。
讓中間表示在隱藏空間中分散
一起來看論文細節。
何愷明和合作者Runqian Wang的出發點有三:
- 擴散模型的局限性
擴散模型在生成復雜數據分布方面表現出色,但其訓練通常依賴于基于回歸的目標函數,缺乏對中間表示的明確正則化。
- 表征學習的啟發
表征學習(特別是對比學習)通過鼓勵相似樣本靠近、不同樣本分散,能有效學習通用表示。
對比學習在分類、檢測等任務中已經取得成功,但在生成任務中的潛力尚未被充分探索。
- 現有方法的不足
REPA(表征對齊)等現有方法嘗試通過對齊生成模型的中間表示和預訓練表示來改進生成效果,但存在依賴外部數據、額外模型參數和預訓練過程的問題,代價高昂且復雜。
他們開始考慮,如何借鑒對比自監督學習,鼓勵生成模型的中間表示在隱藏空間中分散,從而提高模型的泛化能力和生成質量。

基于這樣的核心思想,他們設計了Dispersive Loss:通過正則化模型的中間表示,增大中間表示的分散性,使其在隱藏空間中分布得更加均勻。
與對比學習的不同之處在于,在對比學習中,正樣本對需要通過數據增強等方法手動定義,并通過損失函數將正樣本對拉近、負樣本對分開。
Dispersive Loss則不需要定義正樣本對,僅通過鼓勵負樣本對之間的分散性來實現正則化。
對于一批輸入樣本

,Dispersive Loss的目標函數可以表示為:

其中,

是單個樣本的標準擴散損失,
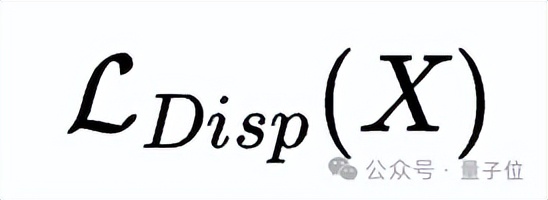
為分散損失項,即正則化項,λ為正則化強度,用于平衡擴散損失和分散損失的權重。
可以看到,Dispersive Loss的實現非常簡潔,不需要額外的樣本對或復雜操作,可以直接作用于模型的中間層表示。
并且不僅支持單層應用,也支持多層疊加——理論上可以在多個中間層同時應用Dispersive Loss,進一步增強不同層級特征的分散性。
實驗結果
作者在ImageNet上,使用DiT和SiT作為基線模型,對不同規模的模型進行了廣泛測試。
結果顯示,Dispersive Loss在所有模型和設置中均提高了生成質量。比如,在SiT-B/2模型上,FID從36.49降到了32.45。

與REPA方法相比,Dispersive Loss不依賴預訓練模型或外部數據,生成質量則并不遜色。
在SiT-XL/2 模型上,Dispersive Loss的FID為1.97,而REPA的FID為1.80。

另外,無論是多步擴散模型還是單步生成模型,都能基于Dispersive Loss得到明顯改進。
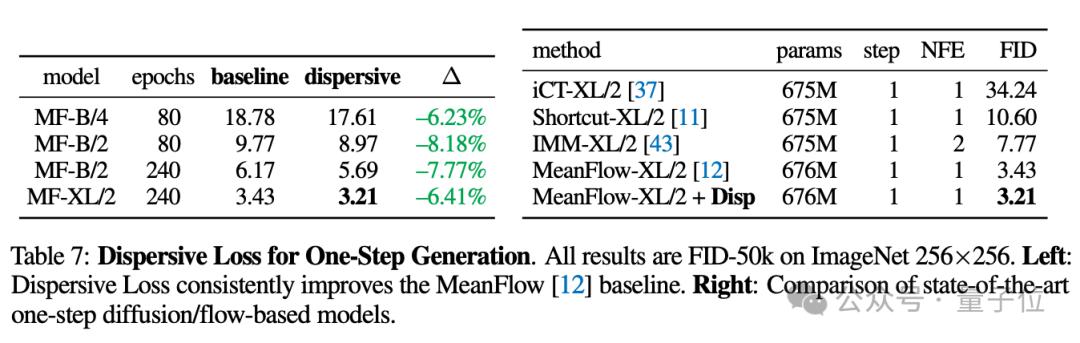
作者認為,不僅是在圖像生成任務上,Dispersive Loss在圖像識別等其他任務上也具有潛力。
論文地址:
https://arxiv.org/abs/2506.09027v1
— 完 —
- 蘋果芯片主管也要跑路!庫克被曝出現健康問題2025-12-07
- 世界模型和具身大腦最新突破:90%生成數據,VLA性能暴漲300%|開源2025-12-02
- 谷歌新架構突破Transformer超長上下文瓶頸!Hinton靈魂拷問:后悔Open嗎?2025-12-05
- 90后華人副教授突破30年數學猜想!結論與生成式AI直接相關2025-11-26
相關閱讀










