
OpenAI喜提姚班學霸姚順雨:思維樹作者,普林斯頓博士,還是個Rapper
“是時候將研究愿景轉變?yōu)楝F(xiàn)實了”
金磊 西風 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
清華姚班學霸姚順雨,官宣加入了OpenAI。

而就是這么一則簡短的消息,卻引來了圈內眾人的圍觀和祝福,來感受一下這個feel:

其中不乏像OpenAI前沿研究主管、美國IOI教練Mark Chen,以及AI領域的教授、投資人等等。
那么這位姚順雨,到底為何能夠引來如此關注?
從他過往的履歷來看,我們可以提煉出這樣幾個關鍵詞:
- 清華姚班
- 姚班聯(lián)席會主席
- 清華大學學生說唱社聯(lián)合創(chuàng)始人
- 普林斯頓計算機博士

△姚順雨,圖源:個人主頁
但除了較為亮點的履歷之外,真正讓姚順雨步入公眾的視野,還是因為他的多項科研成果:
- 思維樹(Tree of Thoughts):讓LLM反復思考,大幅提高推理能力。
- SWE-bench:一個大模型能力評估數(shù)據(jù)集。
- SWE-agent:一個開源AI程序員。
毫不夸張的說,幾乎每項研究都在圈里產(chǎn)生了不小的漣漪;并且非常明顯的一點是,它們都是深深圍繞著大模型而展開。

這或許也正應了姚順雨此次官宣里的一句話:
是時候將研究愿景轉變?yōu)楝F(xiàn)實了。
至于這個“研究愿景”,我們繼續(xù)深入了解一下。
研究關鍵詞:Language Agents
如果縱觀姚順雨的主頁,尤其是論文研究部分,就不難發(fā)現(xiàn)有一個出鏡頻率極高的詞組——Language Agents。

包括在他X主頁中的簡介,第一句話上來也是Language Agents:

而這,也正是他博士畢業(yè)論文的題目:Language Agents: From Next-Token Prediction to Digital Automation。

Language Agents,即語言智能體,是姚順雨提出來了一種新的智能體類別。
和傳統(tǒng)智能體不同的是,這種方法是將語言模型用于智能體的推理和行動,主打一個讓它們實現(xiàn)數(shù)字自動化(Digital Automation)。
至于具體的實現(xiàn)方法,則有三個關鍵技術(均有獨立的論文),它們分別是:
- ReAct:一種將推理和行動相結合的方法,通過語言模型生成推理軌跡和行動,來解決各種語言推理和決策任務。
- 思維樹:一種基于樹搜索的方法,通過生成和評估多個思維路徑來解決復雜問題,提高語言模型的推理能力。
- CoALA:一個概念框架,用于組織和設計語言代理,包括內存、行動空間和決策制定等方面。

以ReAct為例,研究是將語言模型的動作空間擴充為動作集和語言空間的并集。
語言空間中的動作(即思維或推理軌跡)不影響外部環(huán)境,但能通過對當前上下文的推理來更新上下文,可以支持未來的推理或行動。
例如在下圖展示的對話中,采用ReAct的方法,可以引導智能體把“產(chǎn)生想法→采取行動→觀察結果”這個過程進行循環(huán)。
如此一來,便可以結合推理的軌跡和操作,允許模型進行動態(tài)的推理,讓智能體的決策和最終結果變得更優(yōu)。

若是把ReAct的方法歸結為讓智能體“reason to act”,那么下一個方法,即思維樹,則重在讓智能體“reason to plan”。

思維樹是把問題表示為在樹結構上的搜索,每個節(jié)點是一個狀態(tài),代表部分解決方案,分支對應于修改狀態(tài)的操作。
它主要涉及四個問題:
- 思維分解:將復雜問題分解為一系列中間步驟,每個步驟都可以看作是樹的一個節(jié)點。
- 思維生成:利用語言模型生成每個節(jié)點的潛在思維,這些思維是解決問題的中間步驟或策略。
- 狀態(tài)評估:通過語言模型對每個節(jié)點的狀態(tài)進行評估,判斷其在解決問題中的進展和潛力。
- 搜索算法:采用不同的搜索算法(如廣度優(yōu)先搜索 BFS 或深度優(yōu)先搜索 DFS)來探索思維樹,找到最優(yōu)的解決方案。
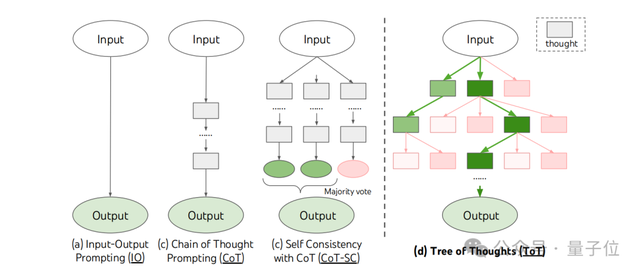
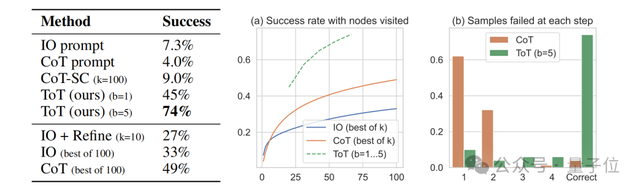
將思維樹應用到“24點”游戲中,與此前的思維鏈(CoT)相比,準確率有了明顯提高。
至于Language Agents中的最后一個關鍵技術,即CoALA,則是一種用于組織和設計語言智能體的概念框架。

從下面的結構圖來看,它大致分為信息存儲、行動空間和決策制定三大模塊。
信息存儲是指語言智能體將信息存儲在多個內存模塊中,包括短期工作記憶和長期記憶(如語義記憶、情景記憶和程序記憶)。
這些內存模塊用于存儲不同類型的信息,如感知輸入、知識、經(jīng)驗等,并在智能體的決策過程中發(fā)揮作用。
除此之外,CoALA 將智能體的行動空間分為外部行動和內部行動;外部行動涉及與外部環(huán)境的交互,如控制機器人、與人類交流或在數(shù)字環(huán)境中執(zhí)行操作。
內部行動則與智能體的內部狀態(tài)和記憶交互,包括推理、檢索和學習等操作。
最終,語言智能體會通過決策制定過程選擇要執(zhí)行的行動;而這個過程也是會根據(jù)各種因素、反饋,從中找出最優(yōu)解。

除此之外,還有像開源AI程序員的工作SWE-agent等,也在圈里廣泛傳播。
但我們從姚順雨眾多的科研課題中,除了Language Agents之外,還能看到他所追求的另一個關鍵詞——計算的思維。
而這一點,其實在他念本科的時候便已經(jīng)有所透露。
在即將奔赴普林斯頓大學攻讀計算機博士學位前,作為2015級學長,姚順雨曾在清華2019年各類型自主選拔復試的開營儀式上向復試考生分享了本人在清華的學習成長經(jīng)歷。
相關內容記錄在他自己寫的名為“你在清華姚班學到了什么?姚順雨:足以改變世界”的文章中。
當時他從理論和實踐兩方面重點分享了計算的思維,并透露覺得四年下來,最大的收獲就是計算的思維:
從理論上我們現(xiàn)在看到很多不可能做到的事情。所謂理論指導實踐,我覺得更多的是說,我們得從一個高度理解一個系統(tǒng)的能力極限和事情難易,然后再選擇能做的、有意義的事情去做。
和陽光開朗大男孩tag鎖死,姚順雨還分享了因清華南方浸潤計劃項目,前往阿根廷的經(jīng)歷:
我遇到了一群阿根廷的孩子……英語并不是世界通用的,阿根廷人說西班牙語。我曾經(jīng)試圖學西班牙語,但是我放棄了,因為我學計算機,我拿出了谷歌翻譯。我跟他們說北京的故宮和長城……

△來源:清華招生 公眾號
在他看來,這個時代,計算能和任何學科相結合,而世界很大,在清華可以做你想做的事。
說完姚順雨,姚班還有哪些人在搞大模型?
爆火的大模型,姚班還有誰在搞?
不得不提的有馬騰宇和陳丹琦。


倆人當年是同班同學,清華姚班2008級校友,并且之后都拿了具有“諾獎風向標”之稱的斯隆獎。
馬騰宇博士就讀于普林斯頓大學,導師是理論計算機科學家、兩屆哥德爾獎得主Sanjeev Arora教授。
博士畢業(yè)后,MIT、哈佛、斯坦福等頂尖高校都給了他助理教授的Offer,馬騰宇最終選擇了斯坦福。
去年年底,馬騰宇還正式宣布大模型創(chuàng)業(yè)了——創(chuàng)立Voyage AI,透露將帶隊打造目前最好的嵌入模型,還會提供專注于某個領域或企業(yè)的定制化模型。
斯坦福人工智能實驗室主任Christopher Manning、AI領域著名華人學者李飛飛等三名教授擔任Voyage AI的學術顧問。

陳丹琦這邊,清華姚班完成本科學業(yè)后,2018年又在斯坦福大學拿下博士學位,主攻NLP,最終成為普林斯頓大學計算機科學系助理教授、普林斯頓語言與智能項目副主任,共同領導普林斯頓NLP小組。
其個人主頁顯示,“這些天主要被開發(fā)大模型吸引”,正在研究主題包括:
- 檢索如何在下一代模型中發(fā)揮重要作用,提高真實性、適應性、可解釋性和可信度。
- 大模型的低成本訓練和部署,改進訓練方法、數(shù)據(jù)管理、模型壓縮和下游任務適應優(yōu)化。
- 還對真正增進對當前大模型功能和局限性理解的工作感興趣,無論在經(jīng)驗上還是理論上。

陳丹琦團隊的大模型工作,量子位也有持續(xù)關注。
比如,提出的大模型降本大法——數(shù)據(jù)選擇算法LESS, 只篩選出與任務最相關5%數(shù)據(jù)來進行指令微調,效果比用整個數(shù)據(jù)集還要好。
而指令微調正是讓基礎模型成為類ChatGPT助手模型的關鍵一步。
提出爆火的“羊駝剪毛”大法——LLM-Shearing大模型剪枝法,只用3%的計算量、5%的成本取得SOTA,統(tǒng)治了1B-3B規(guī)模的開源大模型。
除了這兩位,業(yè)界、學術界姚班校友在搞大模型的還有很多。
之前火爆全網(wǎng)的大模型原生應用《完蛋!我被大模型包圍了》及其續(xù)作《我把大模型玩壞了》,就是由姚班學霸帶隊開發(fā)的。
游戲作者范浩強,曠視6號員工。當年以IOI金牌、保送清華姚班、高二實習等傳奇事跡被譽為天才少年。如今他已是曠視科技研究總經(jīng)理,谷歌學術h-index 32的行業(yè)大佬。

馬斯克xAI首個研究成果——Tensor Programs VI,共同一作中也有姚班校友的身影。

Tensor Programs VI是xAI創(chuàng)始成員、丘成桐弟子楊格(Greg Yang)之前Tensor Programs系列工作的延續(xù),論文重點探討了“如何訓練無限深度網(wǎng)絡”。
據(jù)說Tensor Programs相關成果,在GPT-4中已有應用。為解讀論文,楊格本人當時還專門在X上進行了一場直播分享。
共同一作Dingli Yu,本科畢業(yè)于清華姚班,目前Dingli Yu也快要在普林斯頓計算機科學系博士畢業(yè)了。

還有很多很多…………
說回這次姚順雨被挖到OpenAI,OpenAI這邊的招聘動作還在繼續(xù)。
OpenAI工程師Karina Nguyen發(fā)布最新招聘帖:
OpenAI模型行為團隊招人啦!這是一個集設計工程與訓練后研究于一體的夢想職位,也是世界上最稀有的工作??
我們使用諸如RLHF/RLAIF等對齊方法定義模型核心行為,以體現(xiàn)基本價值觀并提升AGI的創(chuàng)造性智能。通過這些成果,我們與產(chǎn)品+模型設計及工程團隊共同開創(chuàng)AI界面和交互新模式,這將影響數(shù)百萬用戶……

有意思的是,Karina Nguyen其實之前是Anthropic AI(Claude團隊)研究員,去年五月還和思維鏈“開山論文”一作、OpenAI的Jason Wei一同在X(原Twitter)上進行提示詞決斗。

沒想到Karina Nguyen這么快就跳槽到了OpenAI……
順便提一嘴,就在昨天有消息爆料,谷歌DeepMind研究員Thibault Sottiaux也被挖到了OpenAI。
要知道,Thibault Sottiaux在Gemini初代和Gemini 1.5等論文中都是核心貢獻者。

由此可見大模型賽道目前火爆程度,各家搶賽道的搶賽道,搶人的搶人。
One More Thing
跟姚順雨同年從清華畢業(yè)的,還有2位姚順yu!
清華大學官方在2019年三位姚順yu畢業(yè)時,發(fā)了一條微博,還曬了三人的合照。
除了現(xiàn)已加入OpenAI的姚順雨,還有一個姚順雨是來自人文學院日語專業(yè)的一位女生。
另一位姚順yu是姚順宇,來自物理系,他是2018年本科生特獎得主,本科期間就以第一作者在物理頂刊PRL(Physical Review Letters)上發(fā)表論文兩篇、PRB(Physical Review B)一篇。

參考鏈接:
[1]https://x.com/ShunyuYao12/status/1818807946756997624
[2]https://ysymyth.github.io
[3]https://x.com/karinanguyen_/status/1819082842238079371
[4]https://weibo.com/1676317545/HCR7yuXAl?refer_flag=1001030103_
- 云計算一哥10分鐘發(fā)了25個新品!Kimi和MiniMax首次上桌2025-12-03
- Ilya剛預言完,世界首個原生多模態(tài)架構NEO就來了:視覺和語言徹底被焊死2025-12-06
- 前端沒死,AI APP正在返祖2025-12-02
- 華為新架構砍了Transformer大動脈!任意模型推理能力原地飆升2025-12-06
相關閱讀



OpenAI公開未來路線圖!具體到28年3月AI研究員將完全自主,奧特曼承認“關于GPT-4o我們搞砸了”
“在2028年3月實現(xiàn)完全自主的AI研究員”


OpenAI開300萬+年薪招「超級AI研究員」,投入20%總算力成立新部門,目標4年內「控制奧創(chuàng)」
OpenAI:控制奧創(chuàng)需要先開發(fā)賈維斯





