沒有大招的火山引擎,拿下70%大模型玩家
席卷全球的大模型競逐戰,沒有人會主動放棄陣地
魚羊 發自 凹非寺
量子位 | 公眾號 QbitAI
有沒有在開發大模型?在學習。
什么時候發布大模型?沒計劃。
當被問起自研大模型,字節跳動副總裁楊震原口風甚嚴。但席卷全球的這場大模型競逐戰,沒有人會主動放棄陣地。
最新線索,在上海露出端倪。
火山引擎對外的最新技術、產品發布動作中,我們發現:煉大模型的基礎設施,不僅已經在字節內部運轉,還到了能夠對外輸出“技術秘籍”的階段。
直觀的數字,更能說明情況:
抖音2022年最火特效「AI繪畫」,就是在火山引擎機器學習平臺上訓練而成。在訓練場景下,基于Stable Diffusion的模型,訓練時間從128張A100訓練25天,縮短到了15天,訓練性能提升40%。
在推理場景下,基于Stable Diffusion的模型,端到端推理速度是PyTorch的3.47倍,運行時對GPU顯存占用量降低60%。

而就在全球最大云廠商AWS宣布,加入大模型競賽,并且定位是“中立平臺”,會接入Anthoropic、StabilityAI等模型廠商的大模型之際,量子位也獲悉:
火山引擎,也在以類似路徑探索大模型的落地,做法是用“機器學習平臺+算力”為大模型企業提供AI基礎設施。火山引擎總裁譚待透露,國內幾十家做大模型的企業,七成已經在火山引擎云上。
大模型企業為什么會選擇火山引擎?我們和火山引擎機器學習總監吳迪聊了聊。
大模型趨勢,寫在云計算的最新技術里
在AI方面,此番火山引擎重點提到了兩個平臺:機器學習平臺和推薦平臺。
機器學習平臺
其中,機器學習平臺涉及當下科技圈最熱的兩個話題——龐大算力的調度問題,以及AI開發的效率問題。
先來看算力調度。
說到大模型時代,OpenAI首席執行官Sam Altman曾發表觀點稱,“新版摩爾定律很快就要到來,宇宙中的智能每18個月翻一倍”。
而這背后,模型訓練開發所需要的算力規模,可想而知。

但用算力,實際上并不是一個純堆硬件的事情。舉個例子,如果機器學習框架跟底層的硬件是各自獨立的一套,那在訓練AI模型時,由于通信延遲、吞吐量等問題,訓練效率就無法最大化。
簡單來說,就是很多算力會在這個過程中被浪費掉。
解決方法,是軟硬一體。
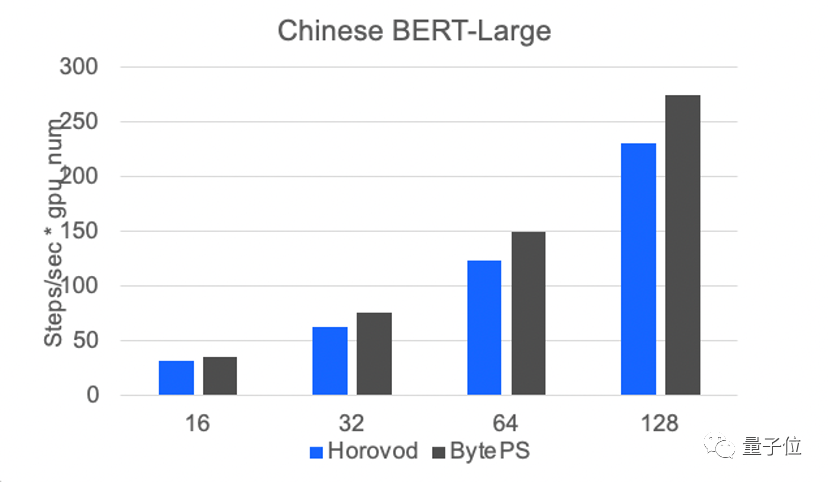
吳迪介紹,火山引擎的自研DPU,將算力層和平臺層統一起來進行了整體優化。比如,將通信優化的算法直接寫到網卡硬件中,以降低延遲、削減擁塞。
測試數據顯示,火山引擎的通信框架BytePS,在模型規模越大時,收益會越高。
而在AI開發效率方面,火山引擎推出了Lego算子優化。
具體而言,這一框架可以根據模型子圖的結構,采用火山引擎自研高性能算子,實現更高的加速比。
前文提到的抖音特效訓練效率的提升,就得益于此:
在推理場景下,使用Lego算子優化,可以將基于Stable Diffusion模型的端到端推理速度提升至66.14 it/s,是PyTorch推理速度的3.47倍,運行時GPU顯存占用量降低60%。
在訓練場景下,在128張A100上跑15天,模型即可訓練完成,比當時最好的開源版本快40%。

目前,火山引擎這一套機器學習平臺,已經部署到了MiniMax的文本、視覺、聲音三個模態大模型訓練和推理場景中。
MiniMax聯合創始人楊斌說,依托火山引擎機器學習平臺,MiniMax研發了超大規模的大模型訓練平臺,高效支撐著三個模態大模型每天千卡以上的常態化穩定訓練。在并行訓練上實現了99.9%以上的可用性。除了訓練以外,MiniMax也同步自研了超大規模的推理平臺,目前擁有近萬卡級別的GPU算力池,穩定支撐著每天上億次的大模型推理調用。
有穩健的大模型基礎設施,MiniMax從零開始自主完整地跑通了大模型與用戶交互的迭代閉環,實現從月至周級別的大模型迭代速度,和指數級的用戶交互增長。MiniMax和火山引擎一起為大模型訓練搭建了高性能計算集群,一起致力于提升大模型訓練的穩定性,保證了千卡訓練的任務穩定運行數周以上。
從今年開始,MiniMax又和火山引擎在網絡和存儲上進行了更深入的優化合作,實現更低的網絡延遲,將帶寬利用率提升了10%以上。
吳迪坦言,“軟硬一體、通信優化、算子優化都不是新概念,火山引擎機器學習平臺也沒有特別牛、特別超前的大招。我們靠的就是務實嚴謹地不斷把細節做扎實,把重要技術錘煉到位,這樣才能贏得客戶的信任。”
推薦平臺
機器學習平臺之外,這次在自家看家本領——推薦系統上,火山引擎對外拿出了推薦系統全套解決方案:從物料管理,到召回排序,再到效果分析、A/B測試和模型算法,都可以開箱即用。
而作為產業界近年來落地最為成功的AI應用之一,在推薦領域,深度學習模型越來越大、越做越深的趨勢,也早已顯現其中。
吳迪介紹,由于推薦是一個高度定制化的場景,每個人的興趣、畫像都有單獨的embedding,因此大規模稀疏模型很重要。
同時,由于真實世界在時刻變化,因此背后又存在一重實時訓練的挑戰。
這都對傳統的深度學習框架提出了很大的挑戰。
為此,火山引擎不僅將以上工程實現進行封裝,推出了基于TensorFlow的機器學習訓推一體框架Monolith,還拿出了針對智能推薦的高速GPU訓練和推理引擎——Monolith Pro。
值得關注的是,Monolith Pro覆蓋的場景包括:
- 針對關鍵場景的超大模型,使用高密度GPU進行超高速訓練;
- 覆蓋更多場景的模型,混合使用CPU+GPU高速訓練。
吳迪進一步解釋說,推薦模型需要做大做深,才能對眾多事物之間的關聯有更好的理解——這一點,如今已經在GPT引發的一系列現象上得到充分驗證。
因此在現在這個時間點,對于任何正在開展推薦廣告業務的公司而言,高價值的數據是一方面,另一方面,找到訓練更強、更大、更實時模型的方法,對整個系統進行智能化升級,已經到了一個關鍵期。

所以,Monolith Pro又具體能實現怎樣的效果?吳迪透露,基于Monolith Pro,抖音內部的某重要廣告場景,原本一次廣告訓練需要15個月樣本,訓練時間為60小時,現在只需要5小時就能完成。
工程師可以做到上午啟動訓練,下午就能開A/B測試了(笑)。
大模型改寫云計算規則
由ChatGPT而起,在海內外一波波大模型的發布中被推至高潮,一場新的技術變革已然勢不可擋。
云計算,作為一個早已深深與AI關聯的業務,站立橋頭,也最早面臨著規則被重新改寫的境況。
隨著大模型能解決越來越多下游任務,如何用大模型,又成為了新的問題:無論是訓練還是推理,大模型都需要很強的基礎設施支持。
云計算成為了最便捷的上車途徑。同時,云廠商們也勢必要面向大模型,重塑自身云產品的面貌。

吳迪認為,作為一項技術,未來大模型會是百花齊放的局面。豐富的需求會催生出若干成功的模型提供商,深入滿足千行百業的業務需求。
與此同時,大模型的應用也面臨若干基礎問題:
- 基礎大模型可能還需要用更多高質量數據,做進一步的增量學習和finetune,才能真正在產業中落地應用。整個流程需要更為敏捷和易用。
- 大模型將成為大數據時代的“中央處理器”,它能夠控制插件、接口,以及更豐富的下游模型。大模型需要這些“手”和“腳”,才能進入我們生活的方方面面。
- 隨著大模型應用的增多,數據安全和信任將成為產業關注的焦點。
- 推理效率。大模型的訓練成本高昂,但長期來看,全社會投入在大模型推理上的開銷將逐漸超過訓練成本。在微觀上,能以更低單位成本提供大模型相關服務的公司,將獲得競爭優勢。

但可以肯定的是,大模型改造各行各業的浪潮已至。
有人正面迎戰,有人從更底層的問題出發,嘗試破解新的問題和挑戰。
共同點是,大模型的潮頭來得迅猛激烈,但在第一線迎接風暴的,從來不是沒有準備之人。
現在,到了檢驗真正AI能力和積累的時刻。至少在與大模型相伴相生的云計算領域,精彩才剛剛開幕。
— 完 —
- 蘋果芯片主管也要跑路!庫克被曝出現健康問題2025-12-07
- 世界模型和具身大腦最新突破:90%生成數據,VLA性能暴漲300%|開源2025-12-02
- 谷歌新架構突破Transformer超長上下文瓶頸!Hinton靈魂拷問:后悔Open嗎?2025-12-05
- 90后華人副教授突破30年數學猜想!結論與生成式AI直接相關2025-11-26
相關閱讀