
還需要“注意力層”嗎?一堆“前饋層”在ImageNet上表現得出奇得好
牛津博士和谷歌同時發現
水木番 發自 凹非寺
量子位 報道 | 公眾號 QbitAI
谷歌昨天提出的MLP-Mixer,可謂是小火了一把。
簡單來說,就是不需要卷積模塊、注意力機制,就可以達到與CNN、Transformer相媲美的圖像分類性能。
但看到新聞的牛津大學博士Luke Melas-Kyriazi,卻沮喪了好一會:
因為大約一個月前,他就發現了可以用前饋層替換注意力層,并已經獲得了很好的效果。

也就是說,他的方法和MLP-Mixer差不多……
所以當他看到報紙時,他甚至一度曾考慮報廢自己的成果。

但他最終還是把成果發在了arXiv上,全文包括了4頁的報告和代碼。
讓我們來看看他的成果。
研究原理
視覺transformer在圖像分類和其他視覺任務上的強大性能,通常歸因于其multi-head 注意力層的設計。
但是,目前尚不清楚引起這種強勁表現的程度。
而在這份簡短的報告中,他亮出了核心觀念:
注意力層是必要的嗎?
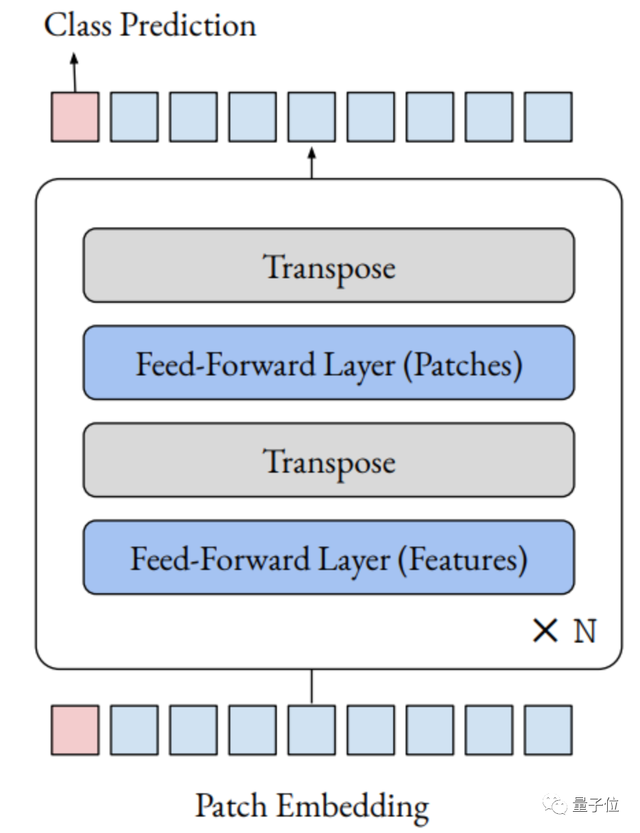
具體來說,他將視覺transformer中的注意力層,替換為應用于patch dimension的前饋層。
最終產生的體系結構,只是一系列以交替的方式應用于patch和特征dimension的前饋層。
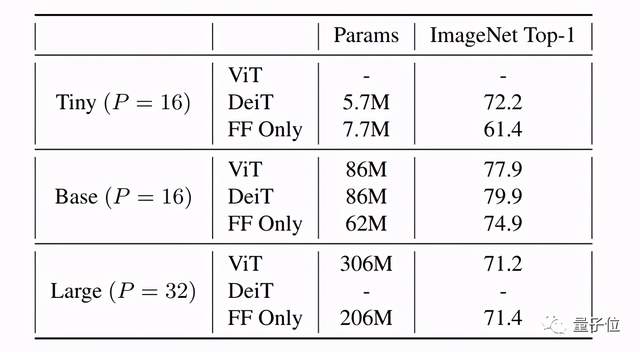
在ImageNet上進行的實驗中,此架構的性能出奇地好:
基于ViT / DeiT的模型,可達到74.9%的top-1精度,而ViT和DeiT分別為77.9%和79.9%。
他的結果表明,無需注意力層,視覺transformer的其他方面,例如patch embedding,可能是其性能強大的主要原因。
他也希望這些結果能幫助大家,花更多的時間,來理解為什么目前的模型能像現在這樣有效。
MLP-Mixer的原理
再回頭看看谷歌的MLP-Mixer。
MLP-Mixer是一種僅基于多層感知機(MLP)的體系結構。
MLP-Mixer包含兩種類型的層:一種具有獨立應用于圖像patches的MLP(即“混合”每個位置特征),另一種具有跨patches應用的MLP(即“混合”空間信息)。
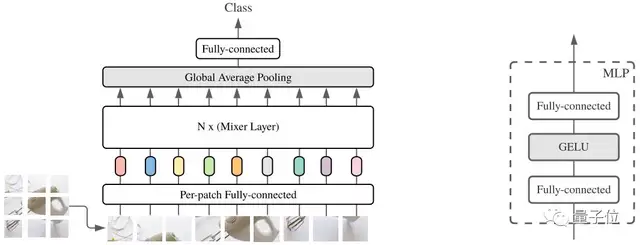
MLP-Mixer用Mixer的MLP來替代ViT的transformer,減少了特征提取的自由度,并且巧妙的可以交替進行patch間信息交流和patch內信息交流。
從結果上來看,純MLP貌似也是可行的,而且省去了transformer復雜的結構,變的更加簡潔。
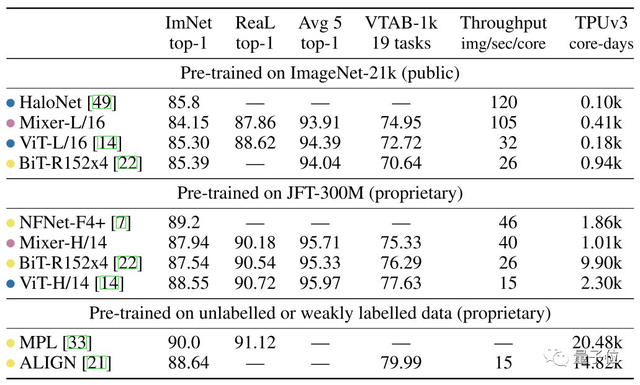
你品,你細品!
怎么樣,是不是很像?

Luke Melas-Kyriazi自己說,這是與谷歌MLP-Mixer并行的研究,idea完全相同,不同之處在于使用了更多的計算。
網友:幾乎相同,但好過谷歌!
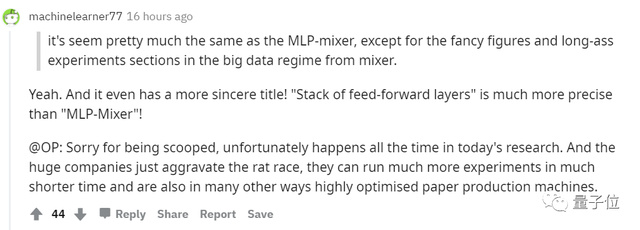
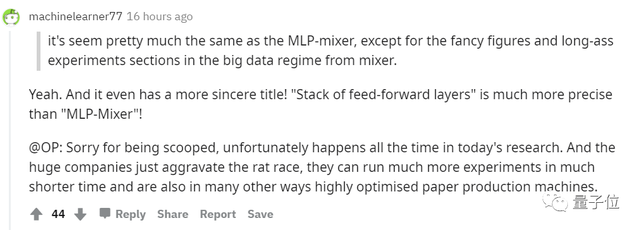
論文看起來與MLP-Mixer幾乎相同,除了Mixer的大數據方法中包含了花式的數據和長效的實驗。
他的“前饋層堆棧”比MLP-Mixer的還要精確得多!
而他也表示:
正是大公司的介入使競爭越來越激烈,他們可以在更短的時間內進行更多的實驗,就像高度優化的造紙機。
好吧,果然大神們的世界做課題的方向和速度都是一樣的“神”。

有興趣的親們記得去看這兩個研究的原文。
團隊介紹
Luke Melas-Kyriazi 哈佛大學數學系畢業生、現牛津大學博士。

目前,在牛津大學Andrea Vedaldi教授指導下,Luke攻讀方向為機器學習和計算機視覺,專注于半監督和多模式學習研究。
參考鏈接:
[1]https://www.reddit.com/r/MachineLearning/comments/n62qhn/r_do_you_even_need_attention_a_stack_of
[2]https://arxiv.org/abs/2105.02723
[3]https://www.reddit.com/r/MachineLearning/comments/n59kjo/r_mlpmixer_an_allmlp_architecture_for_vision/
[4]https://arxiv.org/abs/2105.01601
[5]https://zhuanlan.zhihu.com/p/369959580
[6]https://www.163.com/dy/article/G9AVMRPD0511DPVD.html
- 看完最新國產AI寫的公眾號文章,我慌了!2025-12-08
- 給機器人打造動力底座,微悍動力發布三款高功率密度關節模組2025-12-08
- 云計算一哥10分鐘發了25個新品!Kimi和MiniMax首次上桌2025-12-03
- Ilya剛預言完,世界首個原生多模態架構NEO就來了:視覺和語言徹底被焊死2025-12-06
相關閱讀










