人形AI捉迷藏驚煞網友:飛檐走壁純靠自學,表情豐富還會合作,姚班學霸吳翼參與
網友:OpenAI是一家動畫公司吧
魚羊 安妮 發自 凹非寺
量子位 出品 | 公眾號 QbitAI
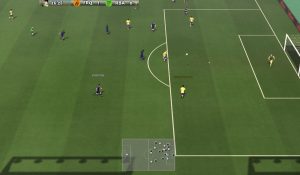
藍色小人努力隱藏,而紅色小人在復雜的地形中苦苦尋找,這場不是你死就是我活的對抗,不是CG動畫,而是:
OpenAI的智能體真的在玩捉迷藏。
這是一項正經的研究,目的在于讓AI自己學會合作和對抗。而事先連游戲規則都不給,全靠AI自己去探索。
由于展示效果看起來優秀得一塌糊涂,網友甚至開始懷疑OpenAI的身份了。
有推特網友表示:
實際上,OpenAI是一家動畫公司。
還有網友表示驚嘆:
哦買嘎,這制作質量、背景環境、甚至智能體的面部表情等都很可愛。這到底是篇科學論文,還是迪士尼里的未來世界主題公園里開辟了一處AI新景點?
這項已經開源的大型AI捉迷藏博弈研究中,場景炫酷,每一個智能體都有自己的想法:
團隊之間相互協作,與外部進行聯合對抗……
這些智能體是不是都有生命了?
AI怎么玩捉迷藏游戲?
在這個捉迷藏游戲中,小紅人是“鬼”,自帶小雷達,能滿場瘋狂追擊。
△紅鬼還能推開箱子
而小藍人的任務很簡單,就是跑。
比起自帶傳感器的鬼們,他們的技能是利用箱子這樣的物體制造障礙,還能將之鎖定。
起初,AI們完全不知道自己能做什么,只是出于“本能”逃跑、追逐。
但在2500萬次游戲之后,小藍人學會了通過移動箱子,建造庇護所,來保護自己不被發現。
魔高一尺道高一丈。又經過了7500萬場比賽,紅鬼們會利用坡道闖進庇護所了!
又吃了1000萬次虧之后,小藍人們再建庇護所,知道把坡道也順走了。
更厲害的是,AI們不只會單兵作戰,還學會了團隊協作。
看看小藍人這個協作水平,那真是行云流水,無縫銜接,還很講究策略:
什么,你覺得地形太簡單?在將近5億次訓練之后,AI們解鎖了更復雜的版本:
這群AI,可真是太秀了。
捉迷藏の奧義
再強調一次,以上不是CG,不是CG,不是CG。
這是來自OpenAI的一項新研究。通過多智能體競爭,和捉迷藏這樣一個簡單的目標,以及標準的強化學習算法,研究人員們發現,在沒有事先學習規則的情況下,AI們自己創造了一個自我監督的自動課程(autocurricula)。
這其中,既包含多輪不同的緊急策略,也包括復雜的工具使用和團隊協調。
所謂課程(curricula),可以被視為一系列挑戰。而自動課程(autocurricula)就是指,每個挑戰都是由系統本身產生的。(這一概念由DeepMind提出,論文地址見文末)
△AI們在訓練過程中發現了多達六種獨特的策略
并且,環境變復雜,AI們的表現反而更加強大。與其他自我監督的強化學習方法相比,這群AI的行為更像人類。
OpenAI稱之為無目標探索。
AI們事先并沒有學過捉迷藏的游戲規則,而是憑借對游戲世界的理解自由發展。
為了實現這一點,研究人員利用了以實體為中心的觀察(observation),并采用注意力機制來捕獲對象層信息。
在設定的環境中,每個智能體都根據自身的觀察和隱藏內存狀態獨立行動。
每個物體都會被嵌入,并通過一個有遮擋的剩余自注意塊(residual self attention block),在這其中,注意力集中在物體上,而不是隨著時間改變。
那些就在智能體面前,但并不在其視線之內的物體則會被屏蔽掉,這樣智能體就捕捉不到它們的信息了。
智能體的策略是通過左右互搏(self-play)和近端策略優化訓練出來的。在優化期間,智能體可以在其值函數中使用有關被遮擋物體和其他智能體的特權信息。
此外,大規模訓練效果顯著。增加批量大小可以大大加快收斂速度,并且不會對樣本效率產生太大的影響。
這樣訓練出來的AI,到底魯棒不魯棒呢?
光說不練假把式,不如來一套智力測試練練手。
OpenAI的研究人員設計了一套涵蓋五個基準智力測試的考題,主要分為兩個領域:認知和記憶。
- 物體計數任務:測試智能體是否對物體具有持久的感知(即,能理解即使無法察覺,事物仍然存在這一點)。
- 鎖定和返回:測試智能體是否可以在執行新任務時記住其原始位置。
- 順序鎖定任務:4個箱子被按指定順序放置在3個沒有門的隨機房間中,但每個房間都有一個坡道。智能體必須在沒有進行過觀察的前提下,按照特定順序鎖定所有的箱子。
- 藍圖構建任務:智能體必須把房間中的箱子放到指定的四個目標位置。
- 避難所建設任務:智能體必須在圓筒周圍用箱子造一個避難所。
結果表明,在鎖定和返回,順序鎖定和藍圖構建這三個任務當中,在捉迷藏環境中預訓練過的AI,表現優于基線方法。但在對象技術和住房建設方面表現得要差一些。
△藍線為在捉迷藏環境中預訓練過的AI
不限于游戲場景
這項研究引發了大量網友圍觀,不到一天時間,推特已經超過2000贊。
一位軟件工程師感慨,這項研究直戳智能體對齊問題(Alignment Problem)的難點,即使是在捉迷藏這種簡答的任務中,AI可能也有讓人意想不到的行為。
HackerNews上網友表示,更酷的是這項研究此后可用于真實世界的機器人,讓他們學習去克服挑戰。
OpenAI自己也站出來直言,這項研究帶動了四個方向的研究。
一是證明了在智能體決策中,多智能體自動課程是導致很多不同和混合相轉移的原因之一。
二是驗證了,當模擬真實物理環境中引導智能體行為時,多智能體自動課程可訓練出類似人類的技能,比如借助工具達到目的。
三是,這項研究還提出了一個在開放環境中評價智能體的框架,以及一套有針對性的智能體智力測試。這對于之后的智能體研究有一定參考意義。
最后,這項研究還將環境與構建環境的代碼進行了開源,將鼓勵對基于物理環境的多智能體自動課程的進一步研究。
簡單的規則、多智能體競爭以及標準的大規模強化學習算法,原來可以激勵智能體在無監督方法下學習復雜的策略和技能。
而往前看看,研究的意義又不僅限于理論研究階段,或局限于游戲場景,而是會覆蓋到日常生活的方方面面。
外媒VentureBeat在報道時,引用了DeepMind哈薩比斯對游戲AI的看法:
游戲AI是通往通用AI的墊腳石。我們研究這些游戲的真正原因是,它是研發算法的一個非常方便的試驗場。
我們正在開發一種算法,可以將其轉化到現實世界中來,用于解決真正具有挑戰性的問題,并幫助這些領域的專家。
無論是DeepMind還是OpenAI,在用游戲的方式訓練出可以在真實場景里應用的技術,又何嘗不是創造了一個小小世界呢。
姚班畢業生參與
這篇論文出自OpenAI的Bowen Baker、Ingmar Kanitscheider、Todor Markov、Yi Wu、Glenn Powell、Bob McGrew和Google Brain的Igor Mordatch之手。
一作Bowen Baker本科與碩士都畢業于電氣工程與計算科學專業,自2017年12月開始就職于OpenAI,擔任研究科學家一職,主要針對多智能體領域進行研究。
作者團隊中還有一位年少有為的中國研究人員吳翼(Yi Wu),他是2010級清華大學姚班畢業生,又一華人圖靈獎得主姚期智教授的桃李門生。
作為“半國英才聚清華,而清華一半英才在姚班”的姚班一員,吳翼在本科期間就打卡了微軟、Facebook、今日頭條等互聯網大廠,實習經驗豐富。
2014年到2019年,吳翼奔赴加州大學伯克利分校,攻讀人工智能專業,主要研究方向為將深度強化學習、自然語言處理和概率編程。
吳翼已經在各類AI頂會上發表論文十多篇,IJCAI 16、AAAI 17、EMNLP 17、ICML 18、NIPS 18等會議都有他的研究出現,今年,吳翼還參與了兩篇AAAI 19 Oral論文的研究。
吳翼還在各項競賽中嶄露頭角,還是ACM/ICPC北美冠軍、世界總決賽銀牌,IOI2010銀牌得主。
清華大學交叉信息研究院網站和吳翼個人簡歷顯示,吳翼將于明年入職,這位28歲年少有為的學霸,將擔任清華大學交叉信息科學研究院的助理教授。
姚班出身,回歸姚班,不僅是收獲季節,也是一段薪火相傳的一段佳話。
吳翼個人履歷:
https://jxwuyi.weebly.com/contest-and-interest.html
傳送門
博客:
https://openai.com/blog/emergent-tool-use/
代碼:
https://github.com/openai/multi-agent-emergence-environments
HackerNews:
https://news.ycombinator.com/item?id=20996771
VentureBeat報道:
https://venturebeat.com/2019/09/17/openai-and-deepmind-teach-ai-to-work-as-a-team-by-playing-hide-and-seek/
論文Autocurricula and the Emergence of Innovation from Social Interaction: A Manifesto for Multi-Agent Intelligence Research:
https://arxiv.org/pdf/1903.00742.pdf
— 完 —
- 蘋果芯片主管也要跑路!庫克被曝出現健康問題2025-12-07
- 世界模型和具身大腦最新突破:90%生成數據,VLA性能暴漲300%|開源2025-12-02
- 谷歌新架構突破Transformer超長上下文瓶頸!Hinton靈魂拷問:后悔Open嗎?2025-12-05
- 90后華人副教授突破30年數學猜想!結論與生成式AI直接相關2025-11-26
相關閱讀