掃碼關注量子位
結合樹狀采樣與角色化獎勵機制
PromptCoT框架全面升級
精度無損
已經開始期待下一次的機器人運動會了
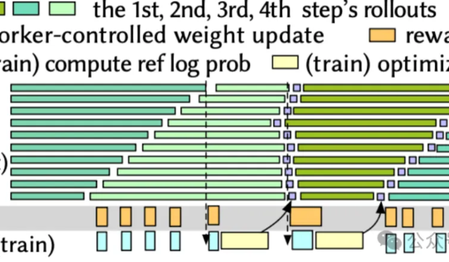
速度提升3.5倍,顯存降至1/4
強化學習+任意一張牌,往往就是王炸。
Plus用戶每月40次使用額度
POLAR:與絕對偏好解耦的策略判別學習
一種用在高級推理模型上Scaling RL的后訓練方法
數學強,不代表啥都好
展現了通往更高級通用智能的清晰路徑
讓教師模型“教學”而不是“解決”
將強化學習深度融入LLM預訓練階段
模仿人類思維方式,只能帶來短期的性能提升
無需標注、拋棄復雜獎勵設計
AIME 2024準確率提升159%
將強化學習訓練擴展到醫學、化學、法律、心理學、經濟學等多學科
基于動態強化學習
準確率提升31%
大模型數學推理任務面臨”三重門”困局。
量子位 QbitAI 版權所有©北京極客伙伴科技有限公司 京ICP備17005886號-1