
HLE首次突破60分!Eigen-1基于DeepSeek V3.1領(lǐng)先GPT-5
三大支柱撐起60分突破
在HLE(“人類最后考試”)的專家校驗子集上,首次有系統(tǒng)突破60分大關(guān)!
就在最近,由耶魯大學(xué)唐相儒、王昱婕,上海交通大學(xué)徐望瀚,UCLA萬冠呈,牛津大學(xué)尹榛菲,Eigen AI金帝、王瀚銳等團隊聯(lián)合開發(fā)的Eigen-1多智能體系統(tǒng)實現(xiàn)了歷史性突破——
在HLE Bio/Chem Gold測試集上,Pass@1準(zhǔn)確率達到48.3%,Pass@5準(zhǔn)確率更是飆升至61.74%,首次跨越60分大關(guān)。這一成績遠超谷歌Gemini 2.5 Pro(26.9%)、OpenAI GPT-5(22.82%)和Grok 4(30.2%)。
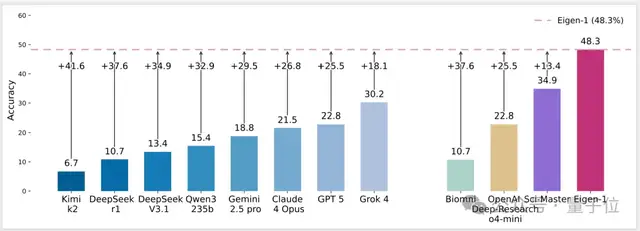
最令人振奮的是,這一成就并非依賴閉源超大模型,而是完全基于開源的DeepSeek V3.1搭建。
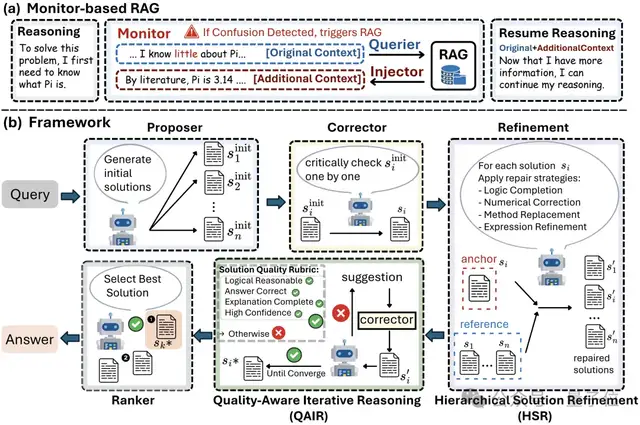
在這個開源底座上,研究團隊通過疊加Monitor-based RAG(隱式知識增強)、HSR(分層解法修復(fù))、QAIR(質(zhì)量感知迭代推理)三大創(chuàng)新機制,實現(xiàn)了質(zhì)的飛躍。
下面詳細展開——
技術(shù)創(chuàng)新:三大支柱撐起60分突破
當(dāng)AI開始挑戰(zhàn)人類知識的終極邊界,一場前所未有的較量正在上演。
當(dāng)大模型在MMLU、GPQA等傳統(tǒng)基準(zhǔn)上紛紛“卷到90分”時,這些測試逐漸失去了區(qū)分力。為了追蹤AI在科學(xué)推理前沿的真實進展,Center for AI Safety與Scale AI聯(lián)合推出了“人類最后的考試”(Humanity’s Last Exam,HLE)——
涵蓋數(shù)學(xué)、自然科學(xué)、工程學(xué)、人文社科等百余領(lǐng)域共3000道博士級難題,被視為AI知識推理的終極試煉。
而HLE Bio/Chem Gold則是HLE的黃金標(biāo)準(zhǔn)子集,包含149道經(jīng)過領(lǐng)域?qū)<胰斯徍撕图m正的題目。
相比原始HLE數(shù)據(jù)集,這個子集排除了可能存在歧義或錯誤答案的問題,確保了標(biāo)簽的準(zhǔn)確性和可靠性,因此成為評估AI科學(xué)推理能力最可信的基準(zhǔn)。
正是在HLE Bio/Chem Gold子集上,Eigen-1系統(tǒng)首次跨越60分大關(guān),而這背后離不開其三大創(chuàng)新機制。
1. Monitor-based RAG:告別“工具稅”的隱式檢索增強
傳統(tǒng)的檢索增強生成(RAG)系統(tǒng)就像一個頻繁暫停的視頻播放器——每次需要外部知識時,都必須中斷推理流程、構(gòu)建查詢、處理結(jié)果,再重新整合上下文。
研究團隊將這種開銷形象地稱為“工具稅”(Tool Tax)——每次工具調(diào)用都會打斷思考流程,導(dǎo)致上下文丟失。
傳統(tǒng)RAG系統(tǒng)的“工具稅”問題在下圖的人口遺傳學(xué)案例中展現(xiàn)得淋漓盡致。左側(cè)顯示模型過度自信地使用錯誤公式,右側(cè)則展示了即使通過顯式RAG獲得正確公式,推理流程的中斷導(dǎo)致模型無法將知識重新整合到原始問題中。

Eigen-1的Monitor-based RAG徹底改變了這一范式:
- 隱式監(jiān)控:Monitor持續(xù)監(jiān)測推理流中的不確定性,像一位細心的助手,在后臺默默關(guān)注著每一個可能需要幫助的時刻。掃描推理軌跡以便在不確定時觸發(fā)RAG。
- 精準(zhǔn)查詢:Querier在檢測到不確定性時,精準(zhǔn)提取最小關(guān)鍵詞集合,避免搜索空間的不必要擴展。
- 無縫注入:Injector則將檢索到的知識無縫融入推理流,就像在對話中自然地補充背景信息,而不是生硬地插入引用。
實驗數(shù)據(jù)顯示,與顯式RAG相比,Monitor-based RAG將token消耗減少53.5%,將工作流迭代次數(shù)減少43.7%,同時保持了更高的準(zhǔn)確率。
見下圖單倍型計數(shù)案例,Monitor檢測到重組約束的不確定性,Querier生成針對性查詢,Injector注入兩個關(guān)鍵事實,使模型能夠排除無效案例并得出正確的30個單倍型答案。

2. Hierarchical Solution Refinement (HSR):從“民主投票”到“層級精煉”
除了隱式知識增強,Eigen-1還革新了多智能體的協(xié)作模式。
傳統(tǒng)的多智能體系統(tǒng)采用“民主投票”機制,所有候選方案被平等對待,容易“稀釋”最優(yōu)解。
而Eigen-1引入的分層解決方案精煉(HSR)打破了這種假設(shè)。HSR采用“錨點—修復(fù)”結(jié)構(gòu):一個候選作為 anchor,其余作為參考依次修正,形成層次化協(xié)作。
在HSR框架下,每個候選解決方案輪流充當(dāng)“錨點”,其他方案則作為“參考”提供針對性修正。這種設(shè)計讓強方案能夠吸收弱方案的有價值見解,而不是簡單地進行平均。
具體包括四種修復(fù)維度:邏輯補全(填補缺失的推理步驟)、數(shù)值修正(糾正計算錯誤)、方法替換(用更優(yōu)策略替代較弱方法)、表達優(yōu)化(提升清晰度而不改變實質(zhì))。
這種設(shè)計讓優(yōu)質(zhì)方案能吸收其他方案的有價值見解,而非簡單平均。
下圖通過一個圖像識別任務(wù)生動展示了HSR的工作原理。
面對昆蟲識別和花朵計數(shù)的復(fù)合任務(wù),錨點解決方案最初選擇了ResNet(選項C),但存在部署時間計算錯誤。通過引入其他解決方案作為參考,系統(tǒng)進行了四類針對性修正。

3. Quality-Aware Iterative Reasoning (QAIR):質(zhì)量驅(qū)動的迭代優(yōu)化
質(zhì)量感知迭代推理(QAIR)能根據(jù)解答質(zhì)量自適應(yīng)地調(diào)整迭代深度:高質(zhì)量解答可提前收斂,低質(zhì)量解答則觸發(fā)更多探索,從而在效率與準(zhǔn)確率之間取得平衡。
該機制為每個方案評估三個維度:邏輯性、答案正確性、解釋完整性。只有未達標(biāo)的方案才會進入下一輪修正,避免在低質(zhì)量候選上浪費計算資源。
全面碾壓:不止于HLE
Eigen-1的優(yōu)勢不限于HLE:
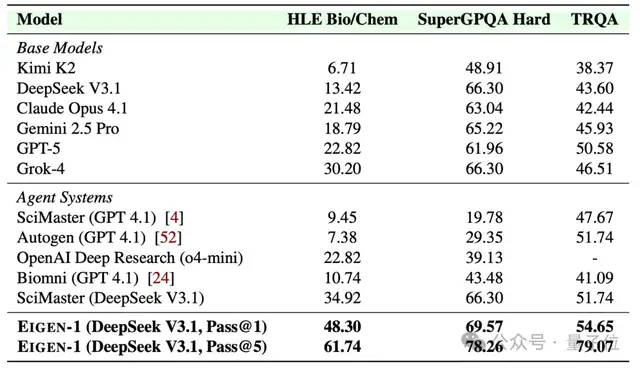
1、HLE Bio/Chem Gold(149題)
- Pass@1: 48.30%(領(lǐng)先SciMaster 13.4個百分點)
- Pass@5:?61.74%(首破60%)
2、SuperGPQA生物學(xué)(Hard版)
- Pass@1: 69.57%
- Pass@5: 78.26%
3、TRQA文獻理解
- Pass@1: 54.65%
- Pass@5: 79.07%
深層洞察:成功背后的規(guī)律
錯誤模式分析
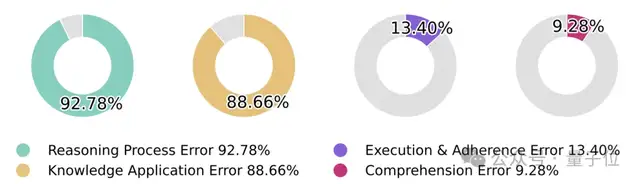
Figure 7的餅圖揭示了一個關(guān)鍵洞察:92.78%的錯誤涉及推理過程問題,88.66%涉及知識應(yīng)用問題,且兩者存在大量重疊。
這表明科學(xué)推理的核心挑戰(zhàn)不在于單純的知識檢索或邏輯推理,而在于如何將知識與推理無縫整合。
相比之下,執(zhí)行遵循錯誤(13.40%)和理解錯誤(9.28%)占比較小,說明模型在指令理解和執(zhí)行層面已經(jīng)相對成熟。
組件貢獻的精確量化
團隊通過增量構(gòu)建和消融實驗精確量化了每個組件的貢獻。
基線系統(tǒng)在沒有任何外部知識的情況下只能達到25.3%的準(zhǔn)確率,消耗483.6K tokens。加入顯式RAG后,準(zhǔn)確率提升到41.4%,但代價是工作流步驟從43.4激增到94.8,這正是“工具稅”的直觀體現(xiàn)。
當(dāng)引入Monitor組件后,雖然準(zhǔn)確率略降至34.5%,但token消耗驟降至218.4K,工作流步驟也降至51.3。
隨著Querier和Injector的加入,準(zhǔn)確率恢復(fù)到40.3%。HSR的引入將準(zhǔn)確率提升至43.7%,最后QAIR將完整系統(tǒng)的準(zhǔn)確率推至48.3%,同時保持了高效的資源利用(218.9K tokens,53.4步驟)。
消融實驗從另一個角度驗證了各組件的必要性。移除Monitor導(dǎo)致token消耗激增至461.3K,工作流步驟增至95.3,顯示了隱式增強的巨大價值。
移除HSR或QAIR分別導(dǎo)致準(zhǔn)確率降至44.8%和43.7%,證明了層級精煉和質(zhì)量感知迭代的重要作用。

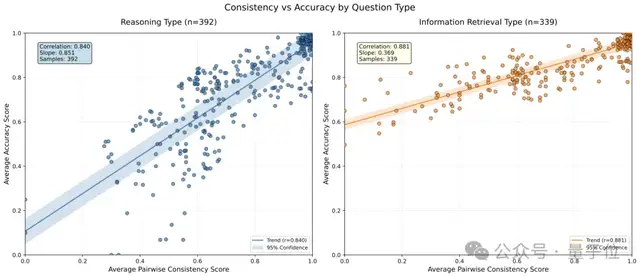
多樣性與共識的微妙平衡
作者通過散點圖和回歸分析揭示了一個違反直覺但極具啟發(fā)性的發(fā)現(xiàn)。
在信息檢索任務(wù)(339個樣本)中,解決方案之間的一致性與準(zhǔn)確率呈現(xiàn)較弱的正相關(guān)(斜率0.369),意味著不同的檢索路徑和視角能帶來互補信息,多樣性是有益的。
而在推理任務(wù)(392個樣本)中,情況完全相反——一致性與準(zhǔn)確率呈現(xiàn)強正相關(guān)(斜率0.851),表明當(dāng)多個推理路徑得出相同結(jié)論時,這個結(jié)論很可能是正確的。
因此,檢索型任務(wù)應(yīng)鼓勵解法多樣性與并行路線;純推理型任務(wù)應(yīng)傾向早期共識與收斂。
這一發(fā)現(xiàn)為未來智能體系統(tǒng)的任務(wù)自適應(yīng)設(shè)計提供了重要指導(dǎo)。
工具稅的精確量化
最后,作者通過對比準(zhǔn)確率提升與token減少的關(guān)系,直觀展示了隱式增強相對于顯式RAG的巨大優(yōu)勢。
傳統(tǒng)的基線+RAG方案雖然能提升準(zhǔn)確率,但以巨大的計算開銷為代價,在圖中表現(xiàn)為向右上方延伸(準(zhǔn)確率提升但token增加)。
而Eigen-1則位于左上象限,在大幅提升準(zhǔn)確率的同時減少了53.5%的token消耗,工作流迭代次數(shù)也從94.8步降至53.4步,減少了43.7%。這種“既要又要”的成果,正是架構(gòu)創(chuàng)新的價值所在。

意義:科學(xué)AI的新范式
Eigen-1首次突破60分的意義遠超一個基準(zhǔn)測試:Eigen-1更預(yù)示著AI輔助科學(xué)研究的新范式。
當(dāng)AI能夠真正理解和推理人類知識前沿的復(fù)雜問題時,它將成為科學(xué)家的強大助手,加速從基礎(chǔ)研究到應(yīng)用轉(zhuǎn)化的全過程。
研究團隊表示,未來將繼續(xù)優(yōu)化架構(gòu)設(shè)計,探索向其他科學(xué)領(lǐng)域的擴展,并研究如何將這些技術(shù)整合到更廣泛的科學(xué)工作流中。隨著更多研究者加入這一開源生態(tài),我們有理由期待科學(xué)AI將迎來更快速的發(fā)展。
正如團隊所言:“HLE可能是我們需要對模型進行的一次重要的考試,但它遠非AI的最后一個基準(zhǔn)。”當(dāng)開源社區(qū)攜手推進,人類與AI協(xié)作探索未知的新時代正在加速到來。
論文鏈接:https://arxiv.org/pdf/2509.21193v1
項目地址:https://github.com/tangxiangru/Eigen-1
- 馬斯克猛猛帶貨太空數(shù)據(jù)中心!“能耗比地球香太多”2025-12-15
- 10億美元OpenAI股權(quán)兌換迪士尼版權(quán)!米老鼠救Sora來了2025-12-12
- 跳過“逐字生成”!螞蟻集團趙俊博:擴散模型讓我們能直接修改Token | MEET20262025-12-12
- 梁文鋒,Nature全球年度十大科學(xué)人物!2025-12-09



