
三位數(shù)學(xué)家改寫經(jīng)典牛頓法!300年前算法一夜更新,收斂速度更快函數(shù)范圍更廣
耶魯華人數(shù)學(xué)家參與
300年經(jīng)典牛頓法,迎來重磅升級(jí)!
三位普林斯頓數(shù)學(xué)家找到更快更強(qiáng)的解法,其中還有一位是華人。
牛頓法是啥?學(xué)過高數(shù)的同學(xué)想必并不陌生,它通過不斷求導(dǎo)來尋找復(fù)雜函數(shù)f(x)接近零點(diǎn)的最優(yōu)解。
就是這么一個(gè)非常簡(jiǎn)單的「近似求解」算法,因?yàn)槭諗克俣确浅?欤瑫r(shí)至今日它仍被廣泛應(yīng)用在計(jì)算機(jī)視覺、物流、金融甚至純數(shù)學(xué)問題等各個(gè)領(lǐng)域,比如開發(fā)能夠區(qū)分交通信號(hào)燈和停車標(biāo)志的自動(dòng)駕駛汽車。
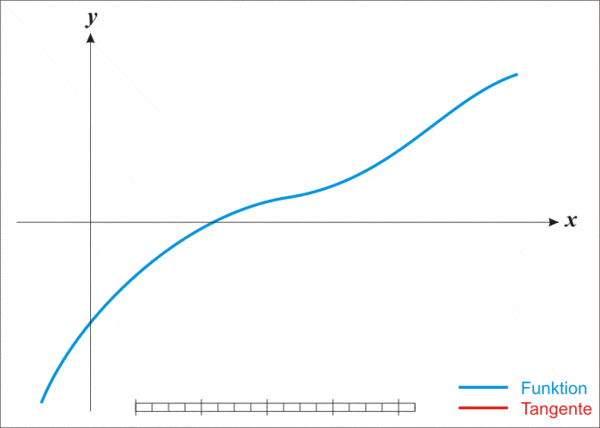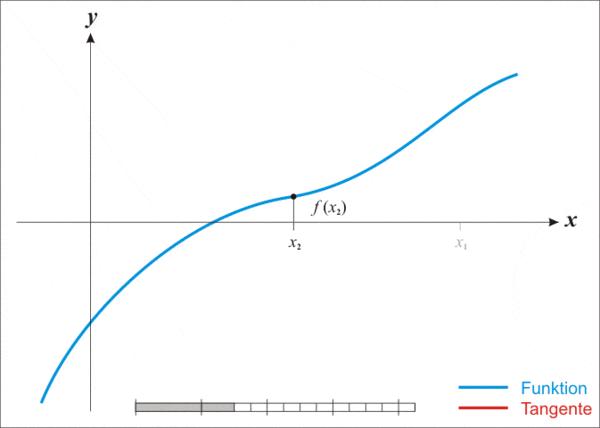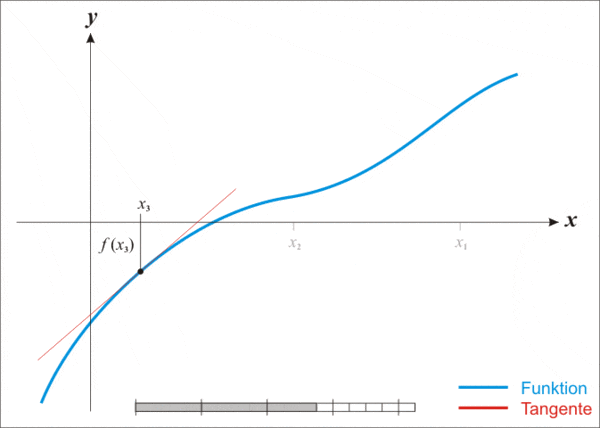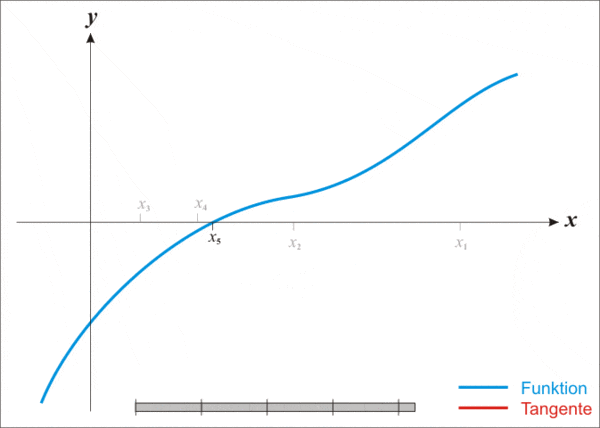
但即便這么強(qiáng)大,牛頓法也存在一個(gè)缺點(diǎn),那就是不適用于所有函數(shù)。
于是乎,過去幾個(gè)世紀(jì)諸多數(shù)學(xué)家前赴后繼企圖在此基礎(chǔ)之上進(jìn)行優(yōu)化。現(xiàn)在這三位數(shù)學(xué)家成功將可適用的函數(shù)范圍一擴(kuò)再擴(kuò)。
比如像這個(gè)復(fù)雜的二元函數(shù)。

與傳統(tǒng)牛頓法相比,新方法展現(xiàn)出來的更連貫,覆蓋也很大。

一合著者表示,牛頓法在優(yōu)化中有1000種不同的應(yīng)用,而他們的算法有可能取代它。
來看看究竟是咋回事兒。
三位數(shù)學(xué)家改寫經(jīng)典牛頓法
牛頓法(Newton’s Method)誕生于17世紀(jì),由大名鼎鼎的英國(guó)數(shù)學(xué)家牛頓首次提出。
其核心思想是,通過不斷逼近函數(shù)的根或極小值點(diǎn),以尋找函數(shù)的最優(yōu)解。
通俗來說,這有點(diǎn)像在陌生環(huán)境里蒙眼尋找最低點(diǎn)。在行走過程中,我們唯一需要的信息在于兩點(diǎn):1)自己是否在上坡或者下坡,即斜率(函數(shù)的一階導(dǎo)數(shù));2)以及坡度是增加還是減少,即斜率本身的變化率(函數(shù)的二階導(dǎo)數(shù))。
利用上述信息,我們可以相對(duì)快速地得到一個(gè)近似值。
若將這一過程用數(shù)學(xué)方法來表示,則具體如下:
- Make a guess(做一個(gè)猜測(cè)):選擇一個(gè)接近你認(rèn)為可能是最小值的起始點(diǎn),作為尋找函數(shù)最小值的起點(diǎn);
- Model the curve(模擬曲線):在該點(diǎn)附近構(gòu)造一個(gè)拋物線,以近似原函數(shù)的形狀;
- Find the next point(找到下一個(gè)點(diǎn)):計(jì)算拋物線的最低點(diǎn),以此作為新的迭代點(diǎn);
- Repeat(重復(fù)):使用新的迭代點(diǎn)重復(fù)上述步驟,逐步逼近函數(shù)的最小值;
- Keep going(繼續(xù)進(jìn)行):持續(xù)迭代,直至找到函數(shù)的最小值。

牛頓證明了,只要不斷重復(fù)上述過程,最終就會(huì)逼近原始復(fù)雜函數(shù)的最小值。
而且和類似迭代方法(如梯度下降)相比,牛頓法雖然每次迭代的計(jì)算成本高于梯度下降,但在效率方面優(yōu)勢(shì)明顯。
簡(jiǎn)單來說,牛頓法收斂速度相比梯度下降法更快,即在更少的迭代次數(shù)內(nèi)找到最小值,因此也適用于多種情況。
不過牛頓當(dāng)時(shí)也提醒:
雖然這一方法在大多數(shù)情況下有效,但如果一開始從一個(gè)距離真實(shí)最小值太遠(yuǎn)的點(diǎn)開始,則可能越跑越偏。

而且更麻煩的是,牛頓法還存在一個(gè)顯著缺點(diǎn)——不適用于所有函數(shù)。
其核心策略是將一個(gè)復(fù)雜函數(shù)轉(zhuǎn)化為一個(gè)更簡(jiǎn)單的函數(shù),而一旦函數(shù)過于復(fù)雜,它也同樣沒轍了。
因此后來數(shù)學(xué)家們努力的方向在于,在不犧牲效率的前提下擴(kuò)大算法使用范圍。
直到去年夏天,三位研究人員發(fā)表了對(duì)牛頓法的最新改進(jìn)。
將牛頓法擴(kuò)展到迄今為止最廣泛的函數(shù)類別
具體而言,他們發(fā)現(xiàn)牛頓法在處理某些復(fù)雜函數(shù)(如高次冪函數(shù))時(shí)效果不好,這是因?yàn)樗蕾囉诤瘮?shù)的泰勒展開(一種使用求導(dǎo)和多項(xiàng)式逼近原函數(shù)的手段),而這個(gè)展開并不總是能很好地描述原函數(shù),特別是當(dāng)函數(shù)有很多“山谷”(局部最小值)時(shí)。
于是他們提出,如果一個(gè)函數(shù)滿足兩個(gè)條件,那么它就更容易找到最小值:
- 凸形(Convex):函數(shù)的形狀像一個(gè)碗,只有一個(gè)“山谷”
- 平方和(Sum of Squares):函數(shù)可以表示為一些平方項(xiàng)的和
前者意味著如果從任何位置開始尋找,都不會(huì)陷入局部最小值的問題,因?yàn)橹挥幸粋€(gè)最小值,而且無(wú)論從哪個(gè)方向開始,都會(huì)滑向這個(gè)唯一的最低點(diǎn)。
后者意味著可以很容易地識(shí)別和計(jì)算函數(shù)的最小值,因?yàn)槠椒胶托问降暮瘮?shù)特別容易處理,其平方數(shù)總是非負(fù)的,而且它們的最小值是0。
接下來,為了滿足上述條件,他們使用了一種叫做半定規(guī)劃(Semidefinite Programming)的技術(shù)來調(diào)整泰勒展開,具體步驟如下:
1、微調(diào)泰勒展開。不直接使用函數(shù)的泰勒展開,而是對(duì)其進(jìn)行微調(diào),使其既凸形又可以表示為平方和。
2、增加調(diào)整因子。在泰勒展開中加入一個(gè)調(diào)整因子,這個(gè)因子可以幫助他們控制展開的形狀,使其更接近原函數(shù),同時(shí)滿足凸形和平方和的條件。
3、多導(dǎo)數(shù)收斂。他們的方法可以使用任意多個(gè)導(dǎo)數(shù)來進(jìn)行泰勒展開,這意味著他們可以更快地找到函數(shù)的最小值。使用更多的導(dǎo)數(shù)可以讓算法以更高的速度(比如立方速度)收斂到最小值。
最終他們創(chuàng)造了這種更強(qiáng)版本的牛頓法,能夠以更少的迭代次數(shù)找到最小值。
他們的算法如下:

在下面這個(gè)函數(shù)中,與傳統(tǒng)牛頓法相比,其改進(jìn)版本(第三階牛頓法)在理論上提供了更快的收斂速度,并且在實(shí)踐中可能比經(jīng)典牛頓法更有效,尤其是在初始點(diǎn)離最小值點(diǎn)較遠(yuǎn)的情況下。

一位華人參與
這項(xiàng)工作是三位數(shù)學(xué)家在普林斯頓大學(xué)期間合作完成的。

其中華人Jeffrey Zhang,目前是耶魯大學(xué)生物醫(yī)學(xué)信息學(xué)與數(shù)據(jù)科學(xué)博士后研究員,研究方向包括大型語(yǔ)言模型、數(shù)據(jù)科學(xué)和統(tǒng)計(jì)學(xué)、計(jì)算復(fù)雜性、多項(xiàng)式優(yōu)化、博弈論和機(jī)制設(shè)計(jì)。

此前在普林斯頓大學(xué)獲得運(yùn)籌學(xué)和金融工程博士學(xué)位,導(dǎo)師正是同為該論文作者的Amir Ali Ahmadi教授。
更早之前,他在2014年獲得耶魯大學(xué)計(jì)算機(jī)科學(xué)和經(jīng)濟(jì)學(xué)與數(shù)學(xué)學(xué)士學(xué)位。
另一位作者Abraar Chaudhry也是Amir Ali Ahmadi教授的學(xué)生,現(xiàn)喬治亞理工學(xué)院博士后研究員。在普林斯頓攻讀博士之前,他在布朗大學(xué)讀本科。
事實(shí)上,在這三位數(shù)學(xué)家出現(xiàn)之前,有很多數(shù)學(xué)家都進(jìn)行了嘗試。
最早19世紀(jì),被稱為「俄羅斯數(shù)學(xué)之父」的Pafnuty Chebyshev提出了一種牛頓法,用三次方程(指數(shù)為3)近似函數(shù)。
不過當(dāng)原始函數(shù)涉及多個(gè)變量時(shí),他的算法就會(huì)不起作用。
更近的一次,2021年俄羅斯數(shù)學(xué)家Yurii Nesterov展示了如何使用三次方程有效地逼近任何數(shù)量的變量的函數(shù)。
但他的方法無(wú)法擴(kuò)展到使用四次方程、五次方程等近似函數(shù),否則會(huì)降低其效率。

現(xiàn)在,3位數(shù)學(xué)家將內(nèi)斯特羅夫的結(jié)果又推進(jìn)了一步。
與牛頓法的原始版本一樣,這種新算法的每次迭代在計(jì)算上仍然比梯度下降等方法成本更高。
因此,目前這項(xiàng)新工作不會(huì)改變自動(dòng)駕駛汽車、機(jī)器學(xué)習(xí)算法或空中交通管制系統(tǒng)的運(yùn)作方式。在這些情況下,最好的選擇仍然是梯度下降。
賓夕法尼亞大學(xué)Jason Altschuler表示:許多優(yōu)化理念需要花費(fèi)數(shù)年時(shí)間才能完全付諸實(shí)踐。不過這似乎是個(gè)全新的視角。
如果隨著時(shí)間的推移,運(yùn)行牛頓法所需的底層計(jì)算技術(shù)變得更加高效,使得每次迭代的計(jì)算成本更低,那么Ahmadi、Chaudhry和Zhang開發(fā)的算法最終可以在包括機(jī)器學(xué)習(xí)在內(nèi)的各種應(yīng)用中超越梯度下降。
合著者表示,從理論上講,他們目前的算法確實(shí)更快。
論文:
https://arxiv.org/pdf/2311.06374
- 空間智能卡脖子難題被杭州攻克!難倒GPT-5后,六小龍企業(yè)出手了2025-08-28
- 陳丹琦有了個(gè)公司郵箱,北大翁荔同款2025-08-28
- 英偉達(dá)最新芯片B30A曝光2025-08-20
- AI應(yīng)用如何落地政企?首先不要卷通用大模型2025-08-12
相關(guān)閱讀

35歲北大校友突破125年數(shù)學(xué)難題!網(wǎng)友:華人數(shù)學(xué)奇跡年
從牛頓定律數(shù)學(xué)推導(dǎo)流體力學(xué)方程

谷歌造出拉馬努金機(jī):幾毫秒求解數(shù)學(xué)常數(shù),無(wú)需任何先驗(yàn)信息
能發(fā)現(xiàn)公式,今后還能證明定理。

AI學(xué)高數(shù)達(dá)到MIT本科水平,學(xué)了微積分線性代數(shù)概率論等6門課,不光能做題還能出題
GPT-3小學(xué)數(shù)學(xué)不及格,Codex會(huì)做150道高數(shù)題



她15歲,上海高一女生,也是頂尖科學(xué)家論壇最年輕嘉賓
除了有良好的學(xué)習(xí)研究環(huán)境,還有個(gè)人的努力。




