
小模型站起來了,瀏覽器里跑出SOTA,抱抱臉:快逃,合成數(shù)據(jù)不是未來
小模型也要訓(xùn)練數(shù)萬億tokens
夢晨 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
瀏覽器里直接能跑的SOTA小模型來了,分別在2億、5億和20億級別獲勝,抱抱臉出品。

秘訣只有兩個:
- 狠狠地過濾數(shù)據(jù)
- 在高度過濾的數(shù)據(jù)集上狠狠地訓(xùn)練
抱抱臉首席科學(xué)家Thomas Wolf,總結(jié)團(tuán)隊在開發(fā)小模型時的經(jīng)驗,拋出新觀點,引起業(yè)界關(guān)注:
合成數(shù)據(jù)目前只在特定領(lǐng)域有用,網(wǎng)絡(luò)是如此之大和多樣化,真實數(shù)據(jù)的潛力還沒完全發(fā)揮。
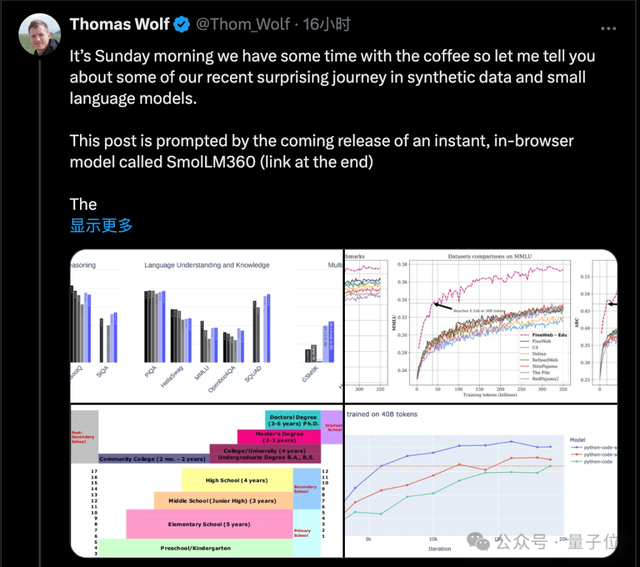
目前360M模型版本已發(fā)布Demo,在線可玩(注意流量)。

在瀏覽器里調(diào)用本地GPU運行,連模型權(quán)重帶網(wǎng)頁前端UI,400MB搞定。

嚴(yán)格過濾網(wǎng)絡(luò)數(shù)據(jù),性能直線上升
針對微軟Phi系列小模型,聲稱使用了一半合成數(shù)據(jù),效果很好,但不公開數(shù)據(jù)。
開源界扛把子抱抱臉看不下去了:
造一個對標(biāo)的大型合成數(shù)據(jù)集,開源它。
而且,團(tuán)隊隱隱暗示了,此舉也有檢驗微軟在測試集上刷榜的傳聞,到底有沒有這回事的考慮。

抱抱臉使用當(dāng)時最好的開源模型Mixtral-8-7B構(gòu)造了25B合成數(shù)據(jù)。
訓(xùn)練出來的模型效果還不錯,但仍然在某種程度上低于Phi-1和Phi-1.5的水平。
他們嘗試了讓大模型在中學(xué)水平上解釋各種主題,最終只有在MMLU測試上表現(xiàn)不好,因為MMLU是博士水平的題目。

真正的性能突破,反而來自一項支線任務(wù):
除了用大模型從頭生成合成數(shù)據(jù),也試試用大模型篩選過濾網(wǎng)絡(luò)數(shù)據(jù)。
具體來說是使用Llama3-70B-Struct 生成的標(biāo)注開發(fā)了一個分類器,僅保留FineWeb數(shù)據(jù)集中最具教育意義的網(wǎng)頁。
使用經(jīng)過嚴(yán)格過濾的網(wǎng)絡(luò)數(shù)據(jù)后,性能直線上升,并在大多數(shù)基準(zhǔn)測試中超過了所有其他類似大小的模型,包括Phi-1.5。

抱抱臉團(tuán)隊稱這項實驗結(jié)果是“苦樂參半”的:雖然模型性能前所未有的高,但也顯示出了合成數(shù)據(jù)還是比不過真實數(shù)據(jù)。
后來他們用同樣的思路從自然語言擴(kuò)展到代碼,過濾的代碼數(shù)據(jù)集也被證明是非常強(qiáng)大的。
將HumanEval基準(zhǔn)測試成績從13%左右直接提高到20%以上。
最終他們構(gòu)造的混合數(shù)據(jù)集中,去重的過濾數(shù)據(jù)集占絕大部分,純合成數(shù)據(jù)Cosmopedia v2只占15%。
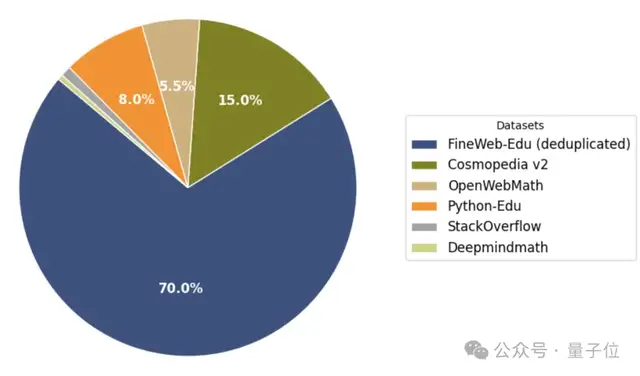
所以總得來說,合成數(shù)據(jù)還有用嗎?
團(tuán)隊認(rèn)為,可能只對確實缺少真實數(shù)據(jù)的領(lǐng)域更有意義了,比如推理和數(shù)學(xué)。

即使小模型也要訓(xùn)練數(shù)萬億tokens
就在他們對這些新發(fā)現(xiàn)和結(jié)果感到興奮時,一位新實習(xí)生Elie Bakouch加入了。
雖然他當(dāng)時只是實習(xí)生,但確是一位精通各類訓(xùn)練技巧的專家。

在Elie的幫助下,團(tuán)隊將模型尺寸從1.7B開始下降到360M甚至170M,也就是對標(biāo)經(jīng)典模型GPT-1、GPT-2和BERT。
在這個過程中有了第二個重要發(fā)現(xiàn):與過去的共識不同,即使是小模型也要在數(shù)萬億token上訓(xùn)練,時間越長越好。
此外數(shù)據(jù)退火(Anneal the data)也被證明是有效的,也就是在訓(xùn)練的最后一部分保留一組特殊的高質(zhì)量數(shù)據(jù)。
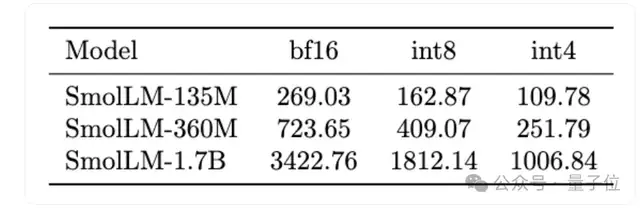
最終發(fā)布的系列模型適合部署在從智能手機(jī)到筆記本電腦的各種設(shè)備上,最大的1.7B模型BF16精度只占3G內(nèi)存。
作為參考,iPhone 15入門版也有6G,安卓手機(jī)就更多了。
雖然這次訓(xùn)練出來的基礎(chǔ)模型足夠好,但團(tuán)隊也還是發(fā)現(xiàn)一個問題。
過去的對齊和微調(diào)技術(shù),如SFT、DPO、PPO等都是針對大模型非常有效,但對小模型效果并不理想。
團(tuán)隊分析,對齊數(shù)據(jù)集中包含許多對小模型來說過于復(fù)雜的概念,并且缺乏精心設(shè)計的簡單任務(wù)。
下一個新坑也挖好了,有興趣的團(tuán)隊可以開始搞起,沒準(zhǔn)就成了小模型大救星。
在線試玩:
https://huggingface.co/spaces/HuggingFaceTB/instant-smollm
參考鏈接:
[1]https://huggingface.co/blog/smollm
[2]https://x.com/Thom_Wolf/status/1825094850686906857
相關(guān)閱讀


Fake It until You Make It:數(shù)據(jù)合成技術(shù),LLM時代的「血液提供商」
填補真實數(shù)據(jù)的不足,同時應(yīng)對數(shù)據(jù)稀缺和隱私問題。


僅1/70的數(shù)據(jù)量,多模態(tài)檢索效果卻更優(yōu)! 智源發(fā)布BGE-VL,合成數(shù)據(jù)立大功
算法能夠以極低成本持續(xù)生成多樣化且高質(zhì)量的多模態(tài)三元組


20K合成數(shù)據(jù)就能讓大模型能力飆升!還能實現(xiàn)模型自我迭代,上海AI Lab數(shù)據(jù)合成新范式
還意外發(fā)現(xiàn),在增大合成數(shù)據(jù)量的情況下,模型性能持續(xù)提升。



