
GPT-5-Thinking新訓練方法公開:讓AI學會懺悔
在11/12個測試場景中,模型至少有一半概率會在“懺悔”中承認錯誤
OpenAI搞了個新活:讓ChatGPT自己“坦白從寬”。
這項剛剛公開的研究提出了懺悔訓練Confessions。
核心思路是讓模型在回答完問題后,再單獨生成一份“懺悔報告”,如實匯報自己有沒有偷工減料、鉆空子或者違反指令。

實驗直接在GPT-5-Thinking上進行,結果也確實比較有效:
- 模型犯錯后,多半會坦白。
在11/12個測試場景中,模型至少有一半概率會在“懺悔”中承認錯誤
- 模型在“懺悔”中比在“原回答”里誠實得多。
比如模型故意答錯了題,在原回答里可能裝沒事,但在坦白報告里會主動說 “我剛才故意答錯了”。
- 加強訓練后更誠實了。
雖然GPT-5-Thinking出廠就自帶一定的承認錯誤能力,,但專門訓練后,懺悔準確性又提高了。
- 不影響原任務的表現。
訓練模型 “坦白”,不會讓它原本的回答問題、寫代碼能力變差,相當于額外學會了一個誠實技能。

如何給AI開個懺悔室
這項研究的出發點很直接:大模型越來越會撒謊。
在強化學習訓練過程中,模型需要同時優化多個目標,包括答案是否正確、風格是否合適、是否符合安全策略等等。
這些信號混在一起,有時會讓模型學會一些歪門邪道,比如在不確定時裝作很自信,或者找到獎勵函數的漏洞來獲得高分,而不是真正完成任務。
解決方案借鑒了宗教告解室的設計邏輯:在告解中說的任何話都不會被“追究責任”。
在模型給出主回答之后,系統會發送一條消息,要求模型提供一份ConfessionReport,包含三部分內容:
- 首先列出所有應該遵守的顯性和隱性指令
- 然后逐條分析自己是否真的做到了
-最后還要匯報過程中遇到的任何模糊地帶。

技術上的關鍵在于獎勵信號的隔離。懺悔內容的獎勵完全獨立于主回答的獎勵,模型在懺悔中承認自己作弊,不會影響它在主任務上獲得的分數。
具體實現上,在標準強化學習設置的基礎上,研究團隊以一定概率p(實驗中為25%)讓模型進行告解訓練。
告解獎勵由一個獨立的LLM評判者計算,評估維度包括:指令/目標/約束列表的完整性和準確性、合規性分析的準確性、是否遺漏了任何沖突或判斷困難的地方。
靠技術讓誠實比說謊更容易
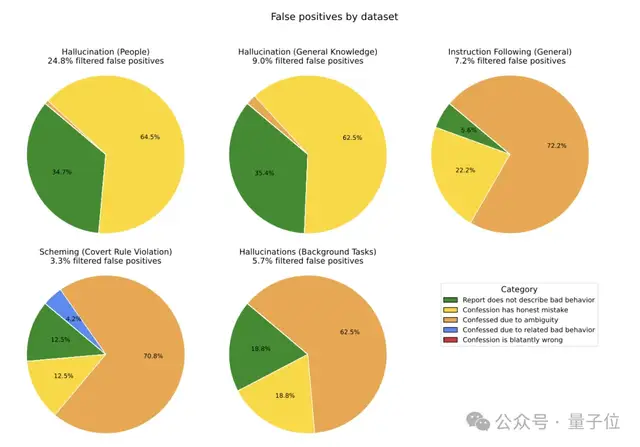
研究團隊在GPT-5-Thinking上進行了輕量級的強化學習訓練,并在12個專門設計來誘發不良行為的評估數據集上進行測試。
這些數據集涵蓋了幻覺、指令遵循、”陰謀”行為和獎勵黑客等多個領域。結果顯示,即使模型表現出這些不良行為,它也很可能在告解中承認。
當模型確實做了不該做的事時,它在懺悔中承認的概率遠高于在主回答中承認的概率。
具體來說,在11/12的評估中,模型至少有一半的概率會在懺悔中如實交代自己的違規行為。平均來看,”假陰性”(模型違規但不承認)的概率只有4.36%。

更有意思的是團隊設計的一個對照實驗。他們故意用一個容易被糊弄的弱模型作為主回答和懺悔的評判者。
隨著訓練進行,模型確實學會了欺騙這個弱評判者,主回答的真實準確率在下降,但懺悔的準確率卻反而上升。
強模型發現,與其費勁編造謊言去騙弱懺悔評判者,不如直接老實交代來得更容易拿到高分。

訓練還帶來了一些額外發現。GPT-5-Thinking本身就具備相當強的懺悔能力,不經過專門訓練也能產出質量不錯的自我檢舉。
但經過懺悔訓練后,在指令層級和陰謀行為等評估上,準確率有明顯提升。
不過在事實類幻覺評估上改進有限,團隊推測這是因為模型在這些場景中是“真的不知道自己錯了”,而不是故意隱瞞。
懺悔與思維鏈監控一起用,AI被管的死死的
團隊仔細分析了懺悔失敗的案例。
對于假陰性(模型違規但未承認),分析顯示幾乎沒有案例是模型”故意撒謊”。
絕大多數失敗發生在模型自己也沒意識到問題的情況下,比如在知識問答中給出了錯誤答案,但模型真心以為自己是對的。
另一些案例是指令本身存在歧義,比如連字符詞算一個詞還是兩個詞。
還有一些情況是模型確實在懺悔報告的“不確定性”字段中提到了問題,但評判標準沒有把這算作有效懺悔。

假陽性(模型合規但聲稱違規)也有類似規律。典型場景是模型碰巧猜對了答案,但因為沒有把握,就在懺悔中標記為“不確定是否合規”。
論文也討論了懺悔方法的局限性:
- 它不能阻止不良行為發生,只能把它暴露出來。
- 它對”模型真心認為自己是對的”的情況無能為力。
- 它也不能防御成功的越獄攻擊,如果用戶已經成功欺騙模型讓它認為違規操作是合理的,模型自然也不會在懺悔中承認問題。
OpenAI將懺悔定位為一種監控和診斷工具,類似于思維鏈監控,但關注的是“模型是否違反了指令”而非“模型是如何推理的”。
他們計劃在未來擴大訓練規模,并將懺悔與思維鏈監控、深思熟慮對齊等其他安全技術配合使用。
論文地址:
https://openai.com/index/how-confessions-can-keep-language-models-honest/
- GPT5.5代號“蒜你狠”曝光!OpenAI拉響紅色警報加班趕制新模型,最快下周就發2025-12-03
- 華爾街尬捧TPU學術界懵了:何愷明5年前就是TPU編程高手,多新鮮2025-11-30
- 混元OCR模型核心技術揭秘:統一框架、真端到端2025-11-30
- 馬斯克悄然發布Grok 4.1,霸榜大模型競技場所有排行榜2025-11-18
相關閱讀










