
更高智商更快思考!螞蟻開源最新萬億語言模型,多項復雜推理SOTA
推理,數學,編程,樣樣精通
時令 發自 凹非寺
量子位 | 公眾號 QbitAI
又一個萬億參數級國產模型開源了!
就在剛剛,螞蟻正式發布百靈大模型的第一款旗艦模型——
擁有萬億參數的通用語言模型Ling-1T。
剛一登場,不僅超越開源模型DeepSeek-V3.1-Terminus、Kimi-K2-Instruct-0905,還超越了閉源模型GPT-5-main、Gemini-2.5-Pro。
在有限輸出token的條件下,于代碼生成、軟件開發、競賽數學、專業數學、邏輯推理等多項復雜推理基準中取得SOTA表現。

不僅如此,Ling-1T還展現出高效思考與精準推理的優勢。例如,在競賽數學榜單AIME 25上,Ling-1T就超越了一眾模型獲得最優表現。

更重要的是,Ling-1T在推理速度上的表現堪稱驚艷,輸入剛落下,模型立刻就啟動思考進程。無論是復雜的邏輯推演,還是生成多輪長文本,它都能快速響應保持流暢輸出。
Ling-1T參數夠多,但它到底有多強、有多快?還是得通過實測才能見真章。
推理高效,前端有驚喜
不妨先用經典推理題目來小試一下身手。
讓7米長的甘蔗通過2米高1米寬的門。
只見Ling-1T先將其判斷為一個典型的空間幾何優化問題,并進行了關鍵障礙分析。

隨后,共提出了4種解決方案,每種方案都有具體的操作步驟和適用場景說明。

更關鍵的是,Ling-1T還能嚴謹地對每種方法進行物理可行性驗證,詳細分析其所需條件和潛在風險。
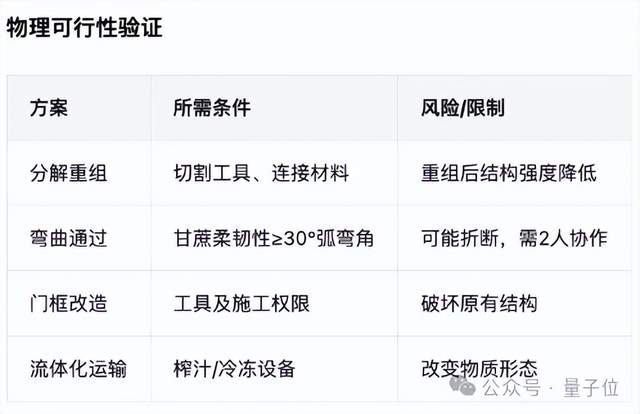
可以說是有理有據了(doge)。
既然如此,咱可就給Ling-1T上難度了,用一道“外星人分裂”問題測試一下其數學能力。
一個外星人來到地球后等可能選擇以下四件事中的一件完成:
1、自我毀滅;
2、分裂成兩個外星人;
3、分裂成三個外星人;
4、什么都不做。
此后每天,每個外星人均會做一次選擇,且彼此之間相互獨立。
求地球上最終沒有外星人的概率。

Ling-1T反應非常快,幾乎是一看到問題就迅速開始分析與推理。
它首先確定了題目的類型,并對題目進行了建模,接著一步步求解最后得到正確答案:√2-1。
推理能力測試完畢,接下來輪到代碼能力上場了。
正值諾貝爾獎揭曉之際,咱用它生成一個介紹諾貝爾獎的網站如何?

新模型kuku就是干啊,效果如下所示:

很直觀,無需特意提醒,Ling-1T就將內容分成概覽、獎項類別、歷史時間線等模塊,讓用戶可以快速定位感興趣的信息。
無論是想了解整體概況、深入某個獎項類別,還是回顧諾貝爾物理學獎的歷史演變,都能獲得清晰、系統的呈現,使用體驗更加直觀高效。
雙節假期剛結束,旅游攻略是不是做得頭都大了。嘗試用Ling-1T規劃出行路線,它不僅把景點按特色分類,還貼心規劃好一日游的時間安排和費用,連適合的交通工具、地道美食都一并推薦。所有選項都打上了清晰標簽,讓你輕松選擇。

值得一提的是,基于Ling-1T強大的推理能力,研究團隊還進一步提出了“語法–功能–美學”混合獎勵機制,這意味著其生成的代碼不僅正確、功能完整,還兼顧了界面和視覺美感。
例如,在ArtifactsBench前端能力基準上,Ling-1T就以明顯優勢成為開源模型中的第一名。
“中訓練+后訓練”,讓模型真正“學會思考”
模型開源之外,這一次螞蟻也完整公布了Ling-1T背后的技術思考。

總結起來,最值得關注的就是研究團隊在擴展模型尺寸和強化推理能力兩方面的探索。
參數數量決定了模型能存儲和表達的信息量,就像大腦的神經元越多,記憶和思考的能力越強。
參數不足時,模型可能只能記住簡單規律,面對復雜或長下文問題時容易出錯。
當參數充足時,模型可以在更大數據量和更復雜任務中實現更準確的推理和更好的泛化能力。
基于上述原因,Ling-1T沿用了Ling 2.0的架構設計,并在此基礎上將總參數量擴展至1萬億,其中每個token激活約50B參數。
其基礎版本(Ling-1T-base)首先在超過20T token的高質量、強推理語料上完成了預訓練,并支持最長128K的上下文窗口。
隨后,團隊通過采用“中訓練+后訓練”相結合的演進式思維鏈(Evo-CoT)方法,這一改進讓模型不僅擁有海量知識,更能像人一樣逐步推理,極大提升了模型的高效思考和精準推理能力。

在研發Ling-1T萬億級模型的過程中,研究團隊發現,擴展模型規模和強化推理能力會帶來一定的性能提升。
在預訓練階段,他們先搭建了一個統一的數據管理系統,這套系統能追蹤每一條數據的來源和流向。
然后,他們整理了超過40萬億token的高質量語料,并挑選出最優部分,用于Ling-flash-2.0的20萬億token預訓練計劃。
畢竟模型的推理能力就像大腦思考問題,先打基礎知識,再訓練邏輯推理,基礎打得扎實,思考才能快而準確。
為了讓模型既能積累豐富知識,又能提高推理能力,團隊將預訓練分成3個階段:
第一階段先用10T token高知識密度語料訓練,讓模型先全面掌握事實、概念和常識,為后續推理打下堅實基礎。
第二階段用10T token高推理密度語料訓練,讓模型學會邏輯推理、多步思考和問題解決技巧,讓模型不僅知道答案,還能分析思路,提高解決復雜問題的能力。
中間訓練階段(Midtrain)則擴展上下文窗口到32K token,同時提高推理類語料的質量和比例,并加入思維鏈推理內容,為模型進入后訓練做好熱身準備,保證邏輯連貫性和推理效率。
整個訓練過程中,團隊根據Ling Scaling Laws設置學習率和批量大小,并用自研的WSM(Warmup-Stable and Merge)替代傳統的WSD(Warmup-Stable-Decay)學習率策略。
要知道,在訓練大模型時需要控制學習率(學習速度),就像學習彈琴或開車一樣,速度太快容易出錯,太慢又不夠高效。
為此,WSM框架可實現無衰減學習率卻能提升模型性能,核心思路可以概括為以下3步:
Warmup(預熱):訓練一開始慢慢來,讓模型穩定起來,不出大錯。
Stable(穩定):訓練中期保持穩定的學習速度,讓模型慢慢學到規律。
Merge(合并):把訓練過程中不同階段保存下來的模型“融合”在一起,相當于把每一階段的優點結合起來,既保留早期探索的優勢,又強化后期收斂的效果,讓模型最終表現更好。
Ling-1T通過中訓練檢查點合并技術表明,即使不采用傳統的學習率衰減策略,模型仍能在絕大多數下游任務中取得更優性能。
實驗結果顯示,影響模型表現最關鍵的不是合并次數,而是合并時的訓練窗口,即何時進行合并以及合并持續的時間長度,對性能的影響遠超其他因素。

在后訓練階段,由于當前主流的強化學習算法(如GRPO和GSPO)各有局限。
- GRPO:將每個詞元(token)視為獨立動作進行優化,雖精細,但容易導致語義的過度碎片化。
- GSPO:將整個生成序列視為單一動作進行優化,在全局序列級別執行策略更新,雖穩定,但又可能造成獎勵信號的過度平滑。
螞蟻發現,對于推理任務來說,句子比單個詞元或整個序列更符合語義邏輯,它不僅能保持語義完整,又能讓模型在局部邏輯上進行有效訓練,從而更精準地捕捉語言中的推理和邏輯關系,因此更適合作為策略優化的基本單位。
于是,研究團隊創新性地提出了LPO方法(Linguistics-Unit Policy Optimization,LingPO),首次將句子作為中間粒度進行策略優化,在語義與邏輯之間找到最佳平衡,并在這一層面上執行重要性采樣和裁剪,從而幫助萬億參數模型更穩健地訓練。
這種設計既避免了詞元級別的碎片化問題,又克服了序列級別過于籠統的局限,使獎勵信號與模型行為在語義層面上更加精準地對齊。
實驗結果顯示,與GRPO和GSPO相比,LPO在訓練穩定性和模型泛化能力方面都具有明顯優勢。

中國大模型“王炸”連發
今年以來,中國開源力量不斷給予大模型圈驚喜。從DeepSeek這尾鯰魚攪亂基礎大模型格局,到Qwen家族以全面覆蓋、快速迭代的姿態撼動Llama系列王座……國產開源模型不僅在全球榜單上站到C位,更重要的是,每一次“開源大禮包”,都能從不同的角度給模型研究、應用帶來新的思考。
此番螞蟻開源Ling-1T,亦是如此。
在技術范式上,Ling-1T在架構設計和訓練方法上實現了多重創新,以演進式思維鏈的新方法,使得模型在每一階段中生成的思路或結論,都可以被復查、修正或擴展,從而不斷迭代優化。
同時,前一階段的推理成果會被累積并傳遞至后續階段,形成知識的持續演進。這種漸進式的推理機制,不僅增強了思維過程的穩定性和結果準確性,也使得推理路徑清晰可循,顯著提升了復雜任務的可解釋性。
在效果體驗上,Ling-1T展現出令人印象深刻的快速響應能力,即刻可完成復雜任務的推理與生成。
無論是面對抽象的數學問題、多步驟的邏輯推演,還是編程任務與科學背景的深度解析,該模型均能迅速構建出條理清晰、邏輯嚴謹的解答。
總結起來,一方面,Ling-1T讓螞蟻正式加入 “萬億參數開源俱樂部”,與Qwen、Kimi并肩站在開源生態的第一梯隊;另一方面,其創新的非思考模型架構與高效推理優化設計,為業界探索高性能思維模型提供了新的技術范式。
更加值得關注的是,盡管2025年只剩下最后的83天,但螞蟻的最新開源動作,也意味著中國大模型廠商們的開源節奏并沒有放緩。
就在國慶節前,Qwen接連推出多模態模型Qwen3-Next、Qwen3-VL以及圖像編輯模型Qwen-Image-Edit-2509;DeepSeek也在短期內連續開源DeepSeek-V3.1-Terminus和DeepSeek-V3.2-Exp兩個重要版本,還被爆料年底會有更重磅模型進展……現在,假期剛結束,螞蟻再次把這種開源勢頭續住了。
可以預見的是,大模型領域的精彩還將繼續。而下一個驚喜,大概率還是來自中國。
- 快手進軍AI編程!“模型+工具+平臺”一口氣放三個大招2025-10-24
- 匯報一下ICCV全部獎項,恭喜朱俊彥團隊獲最佳論文2025-10-22
- OpenAI以為GPT-5搞出了數學大新聞,結果…哈薩比斯都覺得尷尬2025-10-20
- 首創“AI+真人”雙保障模式!剛剛,百度健康推出7×24小時「能聊、有料、會管」AI管家2025-10-18
相關閱讀


大模型掌握人類空間思考能力!三階段訓練框架學會“邊畫邊想”,5個基準平均提升18.4%
視覺推理正經歷從“視覺轉文本”到“Thinking with Images”的范式轉變








