
首創雙NPU架構一鳴驚人!聯發科天璣9500重磅加碼主動式AI體驗
讓AI跑得久、跑得穩
克雷西 發自 深圳
量子位 | 公眾號 QbitAI
一個問題,在當前的智能手機中,如果AI需要成為具有自主意識、會主動實現功能的“常駐能力”,而不只是一個需要頻繁被動煥新的“功能模塊”,什么樣的芯片架構才能真正跟得上這樣的改變?
聯發科給出的答案是:以更犀利的算力和更友好的能效表現,創造超性能+超能效雙NPU架構,始終讓“AI Always on”。

這是一次從技術形態到使用方式的轉變:目的是讓AI不再依賴被動喚醒,而是作為系統能力始終在線、隨時響應,融入用戶的每一次操作。
這一趨勢正在形成共識。
隨著大模型下沉,端側AI的使用頻率越來越高,從輸入法里的預測補全,到拍照時的構圖建議,從鎖屏摘要到圖像生成,AI正在從“調用一次”變為“時刻可用”。
為此,SoC不僅要能跑得快,更要讓AI跑得久、跑得穩,甚至在用戶毫無察覺的情況下完成實時響應。
天璣9500圍繞這一目標重構芯片底座:首發雙NPU架構,結合存算一體、硬件壓縮等多項關鍵技術,在ETHZ蘇黎世移動SoC AI榜單中蟬聯榜首,相比上一代跑分翻倍。

顯然,聯發科不僅追求生成速度的提升,更意在構建AI在終端常駐運行所需的基礎條件。
AI能力Always on
天璣9500正在讓手機的AI變得更快、更聰明,也更貼近你的使用節奏。
寫文案、整理想法、擴寫內容、總結語音筆記……這類需要組織語言、梳理思路的任務,現在可以更快完成。
3B大模型在天璣9500上的輸出性能相比上一代提升100%,內容生成更快、更流暢,連續輸出時思路更連貫。
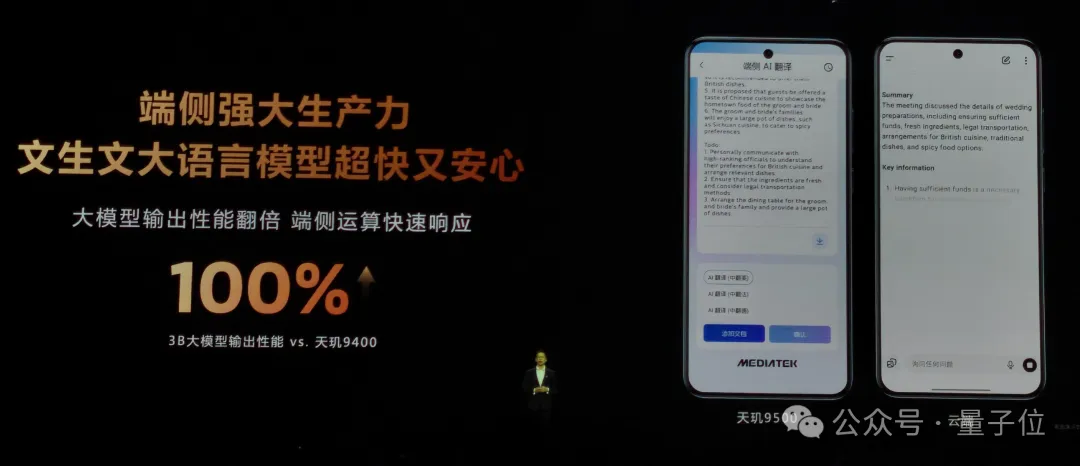
當輸入變長,它也能高效處理。
天璣9500支持128K上下文窗口,是上代的4倍,能一次性讀入相當于10小時錄音的數萬字文本。

對于會議記錄、采訪稿、對話內容等長文材料,它可以根據要求快速提取重點,顯著減少整理所需時間。

在文生圖任務中,天璣9500支持的DiT模型推理性能提升100%,首次實現端側4K超高畫質生圖,僅需10秒即可完成生成。

你可以根據一句文字描述,快速獲得高質量圖片,不依賴云端、不限網絡環境,適合隨時創作、分享或作為創意素材打底。

圖生圖方面,天璣9500支持個性化風格生成。

你可以用已有圖片為基礎,自定義輸出風格,例如將照片轉為手繪、插畫、水彩風,或套用特定藝術濾鏡。在表達創意的同時,也提升了圖像內容的獨特性和辨識度。

你可以用它進行素材美化、或嘗試創意改圖,完成社交發布、內容創作等日常任務。
為了讓這些能力真正服務于日常場景,聯發科與手機廠商也在深入合作,共同推動端側AI落地。
vivo與聯發科基于天璣9500聯合打造了藍心AI錄音機、分鐘級訓練的定制美顏,以及全場景的藍心大模型端側推理與訓練能力;

OPPO則在小布識屏與AI意圖搜索上,與天璣9500進行異構計算和內存優化協同,還有更多品牌正與聯發科圍繞天璣9500展開端側AI能力部署探索。

不只是生成和理解,天璣9500也具備了一種全新的AI運行方式,讓AI能力在手機中保持持續在線。
這意味著,部分AI功能可以常駐系統后臺,無需反復喚醒,也不會影響你的使用節奏。比如在拍照時,它會自動運行,實現幀幀追焦,即使你不停移動,焦點也能始終準確鎖定,畫質清晰穩定,達到單反級水準。

“AI Always on”不是某一項功能,而是一種新的運作方式,讓AI真正融入日常使用,在不打擾你的情況下,持續提供幫助。
超性能+超能效,首創雙NPU架構
要讓端側AI真正進入日常應用,實現“Always on”的常駐智能體驗,必須從硬件架構開始重構運行基礎。
天璣9500圍繞這一目標,首次提出“雙NPU”設計,通過超性能核與超能效NPU協同工作,構建了一套真正面向AI常駐場景的系統方案。

超性能NPU990面向高強度推理任務,搭載全新深層次AI引擎2.0,核心算法調度與執行結構全面重構,支持大模型在本地高效運行。
在ETHZv6.0.3測試中,其得分達到15015,相比天璣9400提升超過一倍,展現出極強的通用算力與生成能力,繼續實現 AI性能的霸榜。

這一性能奠定了AI助手在本地完成摘要、翻譯、命名等復雜任務的能力基礎,也為后續常駐化提供了算力保障。
超能效NPU則專注于AI功能的低功耗常駐場景,是支撐“Always on”體驗的關鍵組件。
其首次采用存算一體架構,將傳統架構中分離的計算單元與緩存單元進行物理融合,避免高頻數據搬移帶來的冗余能耗。得益于此,天璣9500可顯著改善常駐AI任務下的發熱與續航問題。

為了量化能效表現,聯發科引入“能效曲線競爭力”分析體系,實際測得該架構在3~4W功耗區間內,推理效率相比天璣9400提升56%。

相比傳統只能在峰值性能中“跑分”的設計,這一架構重心明確落在真實使用條件下的性能釋放,真正支撐起AI的持續在線與多輪交互。
與硬件架構革新同步,天璣9500還在系統層面對端側AI落地面臨的三大關鍵問題給出了解決路徑。
-
模型加載速度慢,AI助手啟動時延遲高,用戶體驗割裂; -
模型駐留內存時功耗高,設備易發熱,續航難以保障; -
端側模型訓練內存占用過大,定制化和個性化能力難以部署;
針對這些挑戰,天璣9500引入三項系統級技術方案——
在加載階段,首發四通道UFS 4.1,打破傳統帶寬瓶頸,模型加載速度提升40%;
在內存調度上,結合硬件級壓縮,4B大模型在1.6GB內即可運行,即使在DRAM資源有限的場景中也能穩定部署;
在推理階段,1.58bit量化、專用Transformer電路與Eagle推理加速算法三項技術協同發力,生成速度比天璣9400提升2倍以上,保障多輪交互響應的連貫性與即時性;

在訓練端,天璣9500配合vivo自研算法對端側訓練鏈路進行壓縮與結構優化,將內存需求降至2GB,首次實現在終端側完成個性化美顏等訓練任務,讓模型能夠隨著用戶使用不斷進化。
多項技術疊加之后,圍繞加載慢、功耗高、訓練難這三大典型挑戰,天璣9500已經從硬件到底層算法形成了一套系統級應對方案,打通了從模型喚醒、持續運行到個性化優化的完整鏈路。
但架構革新與系統整合的意義遠不止于此。
這些技術不僅是對痛點的響應,更是為AI從“可調用”走向“默認在線”的狀態提供支撐。
在天璣9500上,AI能力不再是某個應用場景中的附加項,而是貫穿圖像、語音、文字、傳感器等多模態輸入的系統能力,隨時響應、主動協同。
也正因此,天璣9500的雙NPU設計不是一次單純的性能演進,而是一場圍繞端側AI運行機制的深層次重建。
AI能力融入原生操作流程
為什么移動AI的演進方向指向“Always on”的端側形態?這并不是一個“端”與“云”的路線抉擇,而是源于用戶行為習慣與AI使用方式的同步演變。
在AI進入移動設備早期,它的存在往往是顯式的、階段性的——用戶有具體操作,AI才啟動響應,交互模式以“工具使用”為核心。
但今天,這種交互邏輯正在改變。
越來越多的AI能力開始融入用戶的原生操作流程,成為交互的一部分。
這種轉變帶來一個核心前提:響應需要是即時的,不可依賴被動加載或臨時喚醒。
換句話說,AI如果想要發揮“主動服務”的價值,就需要常駐于系統之中,成為設備資源調度的一部分,而非外掛式工具。
在這個意義上,Always on不僅是硬件運行狀態,更是面向交互體驗的一種基礎能力。
只有AI能力常在,系統才能實現及時響應,才能支撐從人發出指令到AI感知意圖之間的過渡階段。
而這種即時性,正是推動“無感交互”成為可能的關鍵條件。
當用戶不再需要明確表達請求,系統便已給出恰當響應,AI也就從“輔助功能”逐漸變為“使用默認”。
這也意味著,端側AI將不再局限于某類特定任務,而是開始在系統各層持續參與,推動人機交互朝著更自然、更流暢的方向演進。在這一背景下,聯發科提供了一套具有現實落地能力的技術組合。
通過超性能+超能效的雙NPU架構覆蓋高性能與高能效場景,通過系統級整合解決加載、推理、訓練等關鍵瓶頸,天璣9500為AI從“嘗鮮”走向“好用”提供了堅實支撐。
AI真正融入日常,不僅取決于模型本身有多強,還取決于底層系統是否準備好為它持續供能。
這一代的天璣9500,正在讓這種準備成為現實。
- 14歲華人小孩,折個紙成美國天才少年2025-12-06
- 智能體A2A落地華為新旗艦,鴻蒙開發者新機遇來了2025-12-06
- 《三體》“宇宙閃爍”成真!免佩戴裸眼3D屏登Nature2025-12-06
- ROCK & ROLL!阿里給智能體造了個實戰演練場 | 開源2025-11-26










