
一句話生成任務(wù)專屬LoRA!Transformer作者創(chuàng)業(yè)公司顛覆LLM微調(diào)
能夠動態(tài)調(diào)制大模型的超網(wǎng)絡(luò)架構(gòu)
鷺羽 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
告別繁瑣微調(diào),一句話就能生成LoRA?!
由Transformer作者之一Llion Jones聯(lián)合創(chuàng)立的明星AI公司SakanaAI,近期推出Text-to-LoRA (T2L),徹底簡化了模型適配流程:

現(xiàn)在,微調(diào)大模型時動輒數(shù)周的數(shù)據(jù)集準備、反復(fù)調(diào)整超參數(shù)的復(fù)雜流程,可以省了。

使用T2L生成的LoRA在參數(shù)壓縮率上可達80%卻僅降1.2%準確率,零樣本場景下更以78.3%的平均準確率超越現(xiàn)有SOTA方法。
可以說,“一句話定制模型”的時代正在開啟,非技術(shù)用戶不再需要學(xué)習(xí)復(fù)雜的微調(diào)知識,直接用通俗易懂的自然語言就可以完成相應(yīng)工作。

有網(wǎng)友甚至把它比喻為LLM的一個只有文字描述的私人教練,將會徹底改變游戲規(guī)則。
目前該論文已被ICML2025收錄。

詳細內(nèi)容如下:
從文本到LoRA
LLM在執(zhí)行特定任務(wù)前,都需要先進行適配的LoRA微調(diào),為每個任務(wù)單獨訓(xùn)練低秩矩陣,往往耗費大量計算資源和時間。
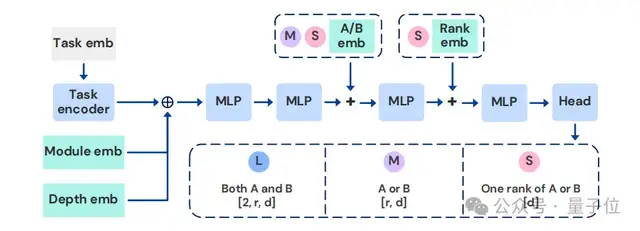
研究團隊從人類視覺系統(tǒng)中汲取靈感,即在有限的感官線索下可以實現(xiàn)環(huán)境快速適應(yīng),并由此構(gòu)建了能夠動態(tài)調(diào)制大模型的超網(wǎng)絡(luò)架構(gòu)Text-to-LoRA(T2L)。

T2L包含3種架構(gòu)變體,它們在輸出空間和參數(shù)規(guī)模上各有不同,具體為:
- T2L-L:
為每個目標模塊(如注意力層、MLP 層)和網(wǎng)絡(luò)層生成完整的 LoRA 權(quán)重矩陣。
該架構(gòu)的參數(shù)規(guī)模最大,但能靈活適配不同層的特性,適用于需要精細控制每層適配的場景。
- T2L-M:
按模塊類型(而非具體層)共享輸出空間。對于同一類型的模塊,超網(wǎng)絡(luò)僅生成一組共享的LoRA矩陣,并應(yīng)用于該類型下的所有層。
該架構(gòu)通過參數(shù)共享減少了模型規(guī)模,同時保留了模塊類型級別的適配能力,在參數(shù)效率和性能之間取得平衡。
- T2L-S:
為整個模型生成統(tǒng)一的LoRA適配器,不區(qū)分模塊類型和層索引。
該架構(gòu)參數(shù)規(guī)模最小,適用于計算資源有限或任務(wù)需求較通用的場景,通過全局適配實現(xiàn)快速部署。
為了訓(xùn)練T2L模型,可以采用兩種訓(xùn)練模式,分別是基于LoRA的重建和跨多個任務(wù)的監(jiān)督微調(diào) (SFT)。
LoRA重建的核心思想是讓T2L從任務(wù)的文本描述中,生成與真實LoRA適配器效果相近的參數(shù),從而最大限度地減少生成適配器和目標適配器之間的重建損失。
這種方法避免了傳統(tǒng)方法中對大量任務(wù)數(shù)據(jù)的依賴,轉(zhuǎn)而利用已有的LoRA適配器和文本描述構(gòu)建監(jiān)督信號,壓縮了現(xiàn)有的LoRAs,但難以進行零鏡頭泛化。
而監(jiān)督微調(diào)則是使用任務(wù)描述,在任務(wù)數(shù)據(jù)集上直接端到端訓(xùn)練T2L。這改進了對未知任務(wù)的泛化,并能夠根據(jù)文本描述生成具有可引導(dǎo)行為的適配器。

針對T2L的適配器壓縮性能,團隊進行了實驗驗證。
通過設(shè)置9個不同的NLP任務(wù),將一一對應(yīng)的LoRA適配器參數(shù)壓縮為文本描述的嵌入向量,并通過3種T2L變體分別重建LoRA參數(shù)。
實驗發(fā)現(xiàn),重建LoRA與原始LoRA相比,參數(shù)規(guī)模從15.8M下降為3.2M,壓縮率達80%,但在任務(wù)的平均準確率上僅下降了1.2%,證明了壓縮過程中的知識保留能力。
其中,T2L-L在壓縮后性能最接近原始LoRA,而T2L-S壓縮率最高。
T2L能夠?qū)崿F(xiàn)高效的參數(shù)壓縮,可以極大地減少存儲需求,幫助LLM在資源受限環(huán)境中進行部署。
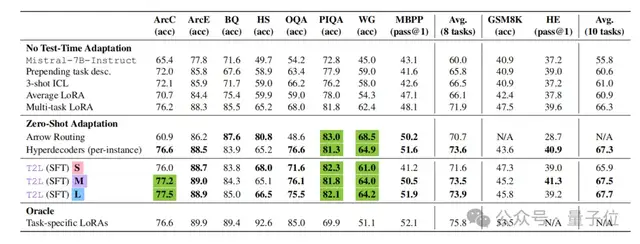
團隊還進一步驗證了T2L在零樣本場景下生成LoRA適配器的能力。
構(gòu)建了12個全新的NLP任務(wù)并各自提供自然語言描述,使用T2L生成的對應(yīng)LoRA適配器直接應(yīng)用于基礎(chǔ)模型,測試其在標注數(shù)據(jù)集上的性能。
結(jié)果表明,T2L的平均準確率達到了78.3%,顯著高于多任務(wù)LoRA的65.1%,和目前最先進的零樣本LoRA路由方法Arrow Routing的72.4%。
其中T2L-L因為能夠為不同層定制參數(shù),在復(fù)雜任務(wù)中表現(xiàn)最佳,而T2L-S在簡單任務(wù)上效率更高,參數(shù)規(guī)模僅為T2L-L的五分之一,但性能僅下降3.2%。
源于超網(wǎng)絡(luò)對 “文本語義 – 參數(shù)空間” 映射的顯式學(xué)習(xí),T2L實現(xiàn)了真正的文本驅(qū)動,無需任務(wù)數(shù)據(jù)即可通過自然語言描述生成有效LoRA,這為模型快速適應(yīng)長尾任務(wù)提供了可能。
Transformer作者創(chuàng)業(yè)公司
背后的公司Sakana AI,由前谷歌研究人員Llion Jones于2023年7月共同創(chuàng)立。
Llion Jones是著名論文《Attention Is All You Need》的8位核心作者之一,論文中首次提出了Transformer架構(gòu),為現(xiàn)代LLM架構(gòu)奠定了基石。

在谷歌工作期間,他還深度參與NLP、模型架構(gòu)創(chuàng)新等眾多核心AI項目,例如Prot Trans、Tensor2Tensor等。
而創(chuàng)辦Sakana AI后,他也始終致力于探索超越和補充當(dāng)前Transformer范式的新路徑,例如他們在去年底推出了用于Transformer的新型神經(jīng)記憶系統(tǒng)NAMM,今年1月提出的Transformer2可以針對各種任務(wù)動態(tài)調(diào)整權(quán)重。

目前公司專注利用自然啟發(fā)的方法(如進化計算和集體智能)來開發(fā)基礎(chǔ)模型,例如在今年5月他們根據(jù)達爾文進化論提出了達爾文哥德爾機 (DGM),可以讓AI通過讀取和修改自身代碼來提升編碼性能。

而本篇論文則由Rujikorn Charakorn、Edoardo Cetin、Yujin Tang、Robert T. Lange共同完成。

Rujikorn Charakorn曾在朱拉隆功大學(xué)就讀,目前在VISTEC研究所攻讀博士學(xué)位,主要研究方向是深度強化學(xué)習(xí)、多智能體學(xué)習(xí)和元學(xué)習(xí)。
Edoardo Cetin于2023年獲得倫敦國王學(xué)院的博士學(xué)位,目前是Sakana AI的研究科學(xué)家,此前還曾在推特的Cortex團隊、豐田和高盛實習(xí)。
而Yujin Tang則博士畢業(yè)于東京大學(xué),曾在谷歌工作長達5年,后來于2024年加入Sakana AI。

Robert T. Lange是Sakana AI的研究科學(xué)家和創(chuàng)始成員之一,致力于用基礎(chǔ)模型來增強和自動化科學(xué)發(fā)現(xiàn)過程。
他還主導(dǎo)參與了首個獨立生成學(xué)術(shù)論文的“AI科學(xué)家”項目,還曾在社區(qū)引起廣泛熱議。
論文鏈接:https://arxiv.org/abs/2506.06105
代碼鏈接:https://github.com/SakanaAI/Text-to-Lora
參考鏈接:
[1]https://x.com/RobertTLange/status/1933074366603919638
[2]https://huggingface.co/SakanaAI/text-to-lora/tree/main
[3]https://x.com/tan51616/status/1932987022907670591
[4]https://x.com/SakanaAILabs/status/1932972420522230214
- 知名數(shù)學(xué)家辭職投身AI創(chuàng)業(yè):老板是00后華人女生2025-12-06
- Runway Gen-4.5刷屏發(fā)布,把重量塵土和光影都做對了,網(wǎng)友:顛覆2025-12-02
- 靈光 “一閃”,330萬個“閃應(yīng)用”已創(chuàng)建2025-12-02
- AI也會被DDL逼瘋!正經(jīng)研究發(fā)現(xiàn):壓力越大,AI越危險2025-12-01
相關(guān)閱讀

首個獎勵模型評分基準!清華復(fù)旦港科大聯(lián)合攻克AI評委“偏科”
評估獎勵模型區(qū)分微妙變化和抵抗風(fēng)格偏差的能力



意-1074386009122013216-1.jpeg)




