
透明物體也能被機器人抓起來了,單目的那種 | ICRA 2025
地瓜機器人&中科院自動化所等共同提出
地瓜機器人團隊 投稿
量子位 | 公眾號 QbitAI
讓機器人精準抓起透明物體,這個難題終于被解決了。
而且還是僅靠一張圖、單目的那種方法。
效果是這樣的:

這就是由地瓜機器人和中科院自動化所等單位共同提出的一項新研究——
MODEST,一個針對透明物體的單目深度估計和語義分割的多任務框架。

MODEST算法框架作為通用抓取模型的前置模塊,即插即用,靈活高效,且無需依賴額外傳感器。
并且僅靠單張RGB圖像,便可實現透明物體的抓取,效果上甚至要優于其它雙目和多視圖的方法。
可以廣泛應用于智能工廠、實驗室自動化、智慧家居等場景,降低設備成本并大幅提升機器人對透明物體的操作能力。
值得一提的是,這項研究已經入選全球機器人領域頂會ICRA 2025(IEEE機器人與自動化國際會議)。
如何做到的?
當前透明物體的抓取核心在于深度信息的獲取,目前無論是深度傳感器還是多視角重建的方法都無法獲取透明物體準確完整的深度信息。
透明物體復雜的折射和反射特性給機器人感知造成了很大困難。在大多數RGB圖像中的透明物體往往缺乏清晰的紋理,而容易與背景混為一體。
此外,商用深度相機也難以準確捕捉這些物體的深度信息,導致深度圖缺失或噪聲過多,從而限制了機器人在多個領域的廣泛應用。
為了解決透明物體感知難題,傳統方法大多依賴特殊傳感設備或多視角圖像,增加了時間和經濟成本,并常常受限于應用場景。
MODEST單目框架首次突破了傳統傳感器處理透明物體時的限制,降低了設備成本和使用復雜度,提供了更加高效、經濟和便捷的透明物體感知方案。
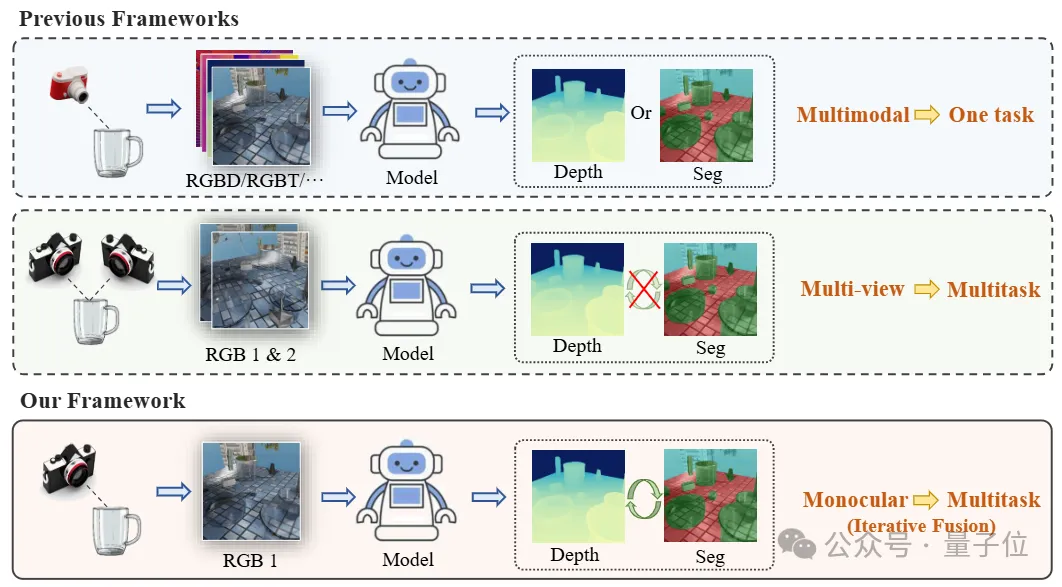 △單目透明物體感知框架與其他方法之間的對比
△單目透明物體感知框架與其他方法之間的對比MODEST主要聚焦于透明物體的深度估計,通過設計的語義和幾何結合的多任務框架,獲取物體準確的深度信息,之后結合基于點云的抓取網絡實現透明物體的抓取。
相當于在通用抓取網絡前面增加一個針對透明物體的增強模塊。
MODEST模型的整體架構如圖所示,輸入為單目RGB圖像,輸出為透明物體的分割結果和場景深度預測。
網絡主要由編碼、重組、語義幾何融合和迭代解碼四個模塊組成。
輸入圖像首先經過基于ViT的編碼模塊進行處理,隨后重組為對應分割和深度兩個分支的多尺度特征。
在融合模塊中對兩組特征進行混合和增強,最后通過多次迭代逐步更新特征,并獲得最終預測結果。
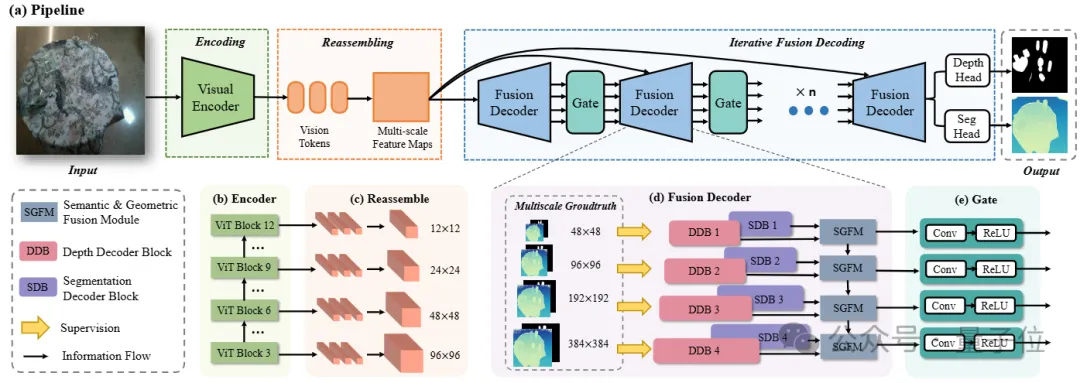 △基于語義幾何融合和迭代策略的透明物體單目多任務框架
△基于語義幾何融合和迭代策略的透明物體單目多任務框架對于透明物體來說,語義分割任務可以為深度估計提供語義和上下文信息,而同樣深度估計可以為分割提供邊界、表面等幾何信息。
為了充分挖掘兩個任務間的互補信息,MODEST 算法框架構建了基于注意力機制的語義幾何融合模塊,旨在同時提升兩個任務的性能。
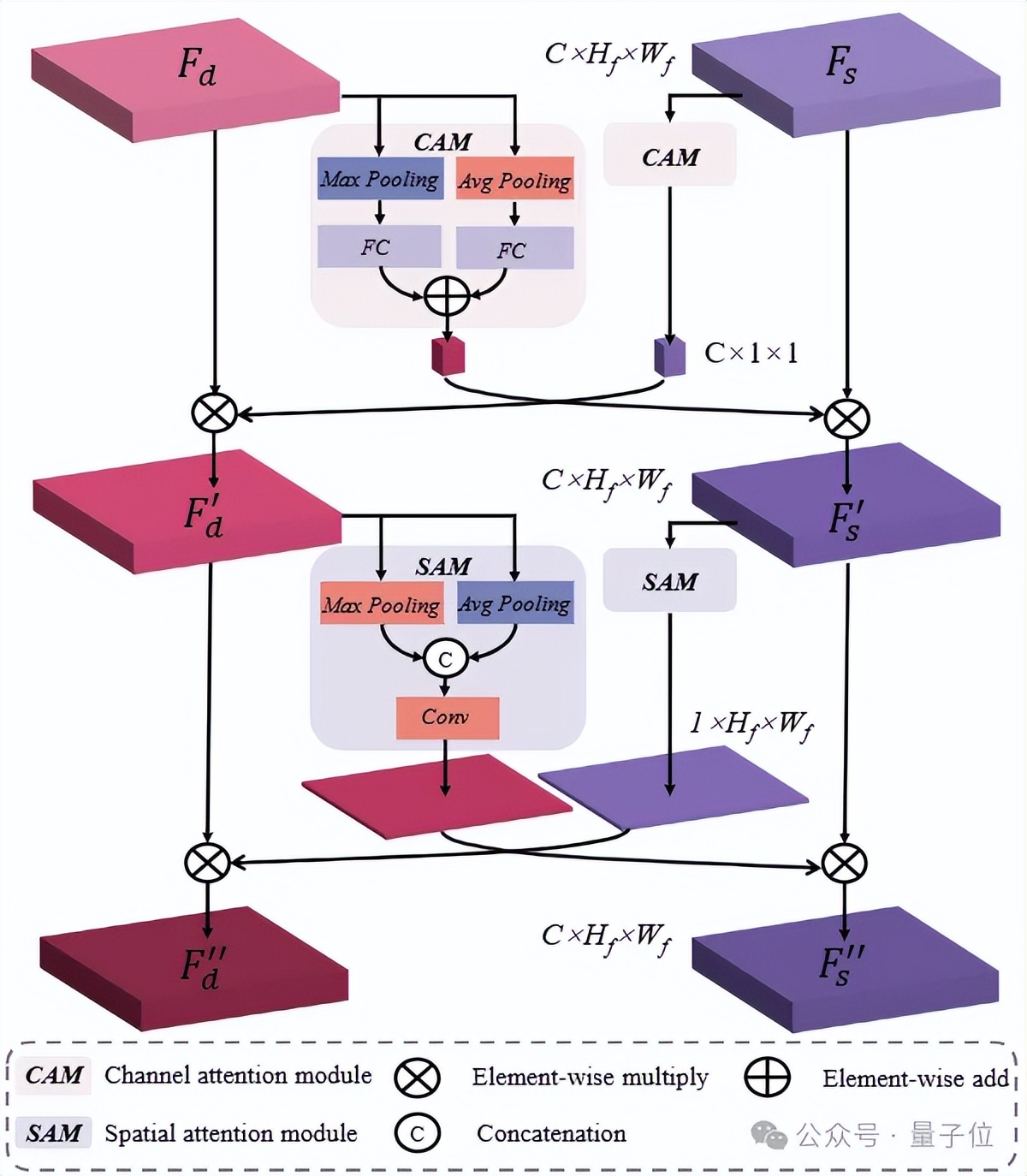 △語義幾何融合模塊結構
△語義幾何融合模塊結構當人類觀察透明物體等不顯著物體時,我們人類會傾向于先注意物體的整體輪廓,然后是局部細節。受人眼啟發,MODEST框架提出了一種由粗到細的特征更新策略,進一步提升預測精度。
實驗結果
為了測試MODEST全新算法框架的檢測效果,團隊選取了透明物體領域兩個影響力廣泛的公開仿真數據集Syn-TODD和真實數據集ClearPose。
在其上與目前最先進的透明物體雙目方法SimNet、多視圖方法MVTran以及多任務方法InvPT和TaskPrompter進行對比實驗。
兩個大規模數據集都擁有超過100k的良好標注圖像數據,并且包含了嚴重遮擋等極端場景。
1、公開數據集上的定性和定量對比實驗
 △仿真數據集Syn-TODD上的定性對比結果
△仿真數據集Syn-TODD上的定性對比結果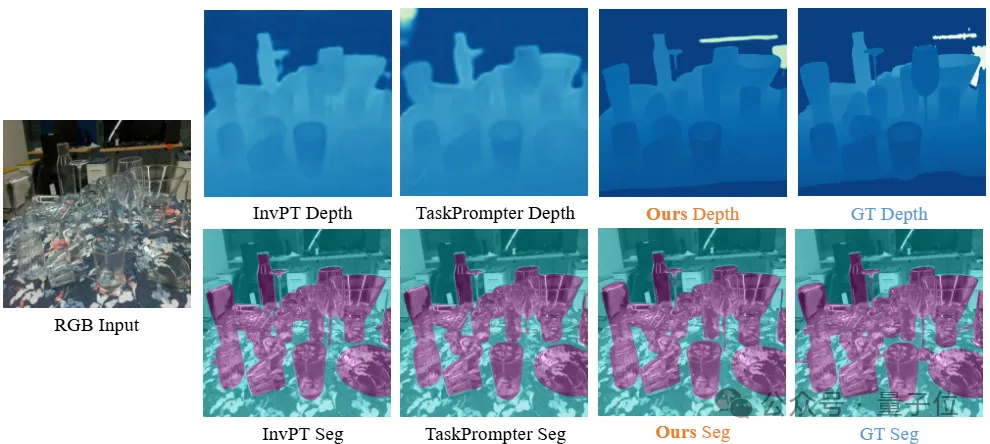 △真實數據集ClearPose上的定性對比結果
△真實數據集ClearPose上的定性對比結果通過在兩個數據集上的定性對比結果可以看出,由于透明物體會錯誤地折射背景,并且在RGB圖像中缺乏紋理,因此SimNet、MVTrans等方法無法獲得令人滿意的預測,從而導致深度圖和分割掩膜的大面積缺失。
然而,通過有效的融合和迭代,在某些即使人眼都難以分析和判斷的場景,團隊的方法依然能夠產生完整和清晰的預測結果。
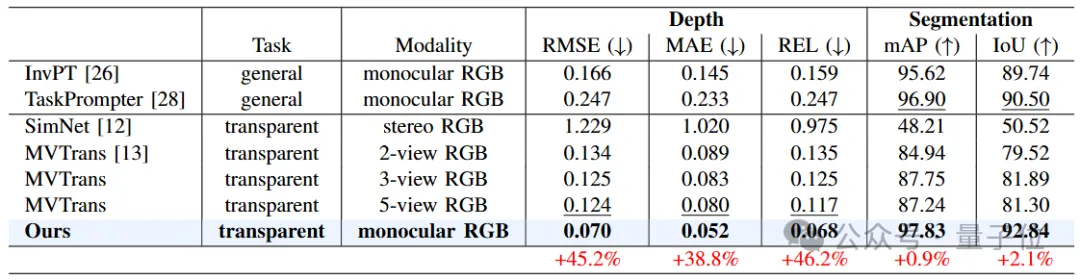 △仿真數據集Syn-TODD上的定量對比結果
△仿真數據集Syn-TODD上的定量對比結果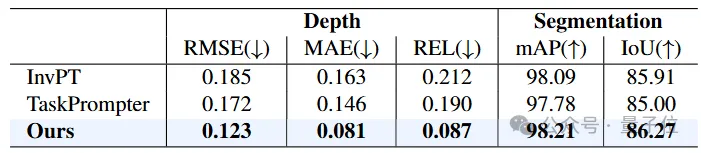 △真實數據集ClearPose上的定量對比結果
△真實數據集ClearPose上的定量對比結果從表格中的定量對比可以看出,MODEST算法框架在各項指標上都要大幅超過其他所有方法。
值得注意的是,盡管只使用單張RGB圖像作為輸入,MODEST在深度估計和語義分割方面都要明顯優于其他雙目甚至多視圖方法。
并且在Syn-TODD數據集上,與排名第二的方法相比,MODEST算法框架在RMSE和REL兩項指標有著超過45%的提升,語義分割的精度也均超過了90%。
2、真實平臺抓取實驗
團隊還將算法遷移到真實機器人平臺,開展了透明物體抓取實驗。
平臺主要由UR機械臂和深度相機構成,在借助MODEST方法進行透明物體精確感知的基礎之上,采用GraspNet進行抓取位姿的生成。
在多個透明物體上的實驗結果表明,MODEST方法在真實平臺上具有良好的魯棒性和泛化性。

One More Thing
值得一提的是,除了MODEST之外,地瓜機器人主導研發的DOSOD開放詞匯目標檢測算法,也入選了ICRA 2025。
MODEST是通過動態語義理解框架提升復雜場景識別準確率,而DOSOD則是結合幾何建模與語義分析技術優化透明物體操作精度。
兩項技術成果均已在規模化商業場景中得到有效驗證。
感興趣的小伙伴可以戳下方鏈接了解詳情哦~
MODEST文章地址:
https://arxiv.org/pdf/2502.14616
MODEST代碼地址:
https://github.com/D-Robotics-AI-Lab/MODEST
DOSOD文章地址:
https://arxiv.org/abs/2412.14680
DOSOD代碼地址:
https://github.com/D-Robotics-AI-Lab/DOSOD?tab=readme-ov-file
- 戴爾 x OpenCSG,推出?向智能初創企業的?體化 IT 基礎架構解決方案2025-12-10
- 看完最新國產AI寫的公眾號文章,我慌了!2025-12-08
- 共推空天領域智能化升級!趨境科技與金航數碼強強聯手2025-12-09
- Ilya剛預言完,世界首個原生多模態架構NEO就來了:視覺和語言徹底被焊死2025-12-06
相關閱讀









