
騰訊發(fā)最大開源MoE模型,3890億參數(shù)免費(fèi)可商用,跑分超Llama3.1
與混元大模型“同宗同源”
夢晨 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
騰訊拿出看家本領(lǐng),來擠開源賽道,突然發(fā)布了市面上最大的開源MoE模型。
Hunyuan-Large,3890億總參數(shù),520億激活參數(shù)。
跑分超過Llama 3.1 405B等開源旗艦,上下文長度支持也高出一檔來到256k。

雖然Hunyuan-Large還不算騰訊內(nèi)部的旗艦?zāi)P停v訊介紹底層技術(shù)與混元大模型“同宗同源”:
很多細(xì)節(jié)都是內(nèi)部業(yè)務(wù)打磨好再開源出來的,比如用到了騰訊元寶App的AI長文閱讀等功能里。
現(xiàn)在這樣的一個模型徹底開源,免費(fèi)可商用,算是很有誠意了。

這次騰訊Hunyuan-Large總共開源了三個版本:預(yù)訓(xùn)練模型、微調(diào)模型、FP8量化的微調(diào)模型。
在開源社區(qū)掀起一陣熱議,HuggingFace首席科學(xué)家Thomas Wolf墻裂推薦并總結(jié)了幾個亮點(diǎn)。
- 數(shù)學(xué)能力很強(qiáng)
- 用了很多精心制作的合成數(shù)據(jù)
- 深入探索了MoE訓(xùn)練,使用共享專家、總結(jié)了MoE的Scaling Law。

各路開發(fā)者中,有立馬開始下載部署的動手派,也有人希望騰訊入局后,開源模型卷起來能迫使Meta造出更好的模型。
這次騰訊同步發(fā)布了技術(shù)報告,其中很多技術(shù)細(xì)節(jié)也引起討論。
如計算了MoE的Scaling Law公式,C ≈ 9.59ND + 2.3 ×108D。
又比如用交叉層注意力節(jié)省KV緩存的內(nèi)存占用。

下面送上發(fā)布會現(xiàn)場演講和技術(shù)報告精華內(nèi)容總結(jié)。
Hunyuan-Large技術(shù)報告
MoE的Scaling Law
直接上公式:
C ≈ 9.59ND + 2.3 × 108D
其中C表示計算預(yù)算(單位FLOPs),N表示激活參數(shù)數(shù)量,D表示訓(xùn)練數(shù)據(jù)量(單位tokens)。
與傳統(tǒng)密集模型的計算預(yù)算公式C=6ND相比,MoE模型公式的差異主要體現(xiàn)在兩個方面:
一是系數(shù)從6增加到9.59,反映了MoE額外的路由計算開銷,包含專家切換的計算成本。
二是增加了常數(shù)項2.3×108D,反映了長序列MoE模型attention計算的額外開銷。
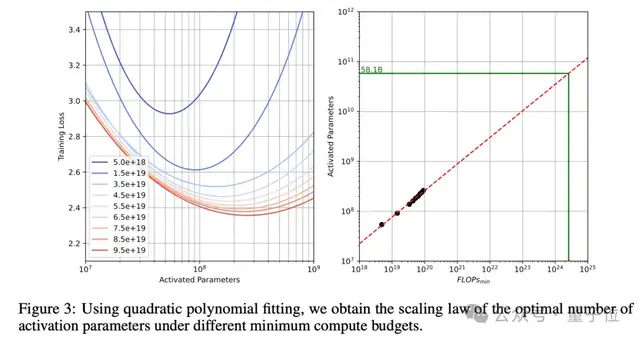
為了確定最優(yōu)激活參數(shù)量,團(tuán)隊投入大量成本展開實(shí)驗(yàn):
訓(xùn)練一系列激活參數(shù)范圍從10M到1B的模型,使用最高1000億tokens的訓(xùn)練數(shù)據(jù),覆蓋100億到1000億tokens的不同數(shù)據(jù)規(guī)模。
使用isoFLOPs曲線,在固定計算預(yù)算下尋找最優(yōu)點(diǎn),同時考慮實(shí)際訓(xùn)練batch size的影響,分析不同參數(shù)量和數(shù)據(jù)量的組合,計算得出最優(yōu)激活參數(shù)量約為58.1B。
而最終Hunyuan-Large選擇了52B的激活參數(shù)量,主要考慮到最優(yōu)點(diǎn)附近曲線平滑,在58.1B附近有較大容差空間,以及計算資源約束、訓(xùn)練穩(wěn)定性要求和部署效率平衡等實(shí)踐因素。
路由和訓(xùn)練策略
除了揭秘最優(yōu)參數(shù)配比,技術(shù)報告中還詳解了Hunyuan-Large獨(dú)特的”MoE心法”。
混合路由策略:
Hunyuan-Large采用共享專家(shared expert)和特殊專家(specialized experts)相結(jié)合的混合路由。
每個token激活1個共享專家和1個專門專家,共享專家處理所有token的通用知識,而特殊專家則用top-k路由策略動態(tài)激活,負(fù)責(zé)處理任務(wù)相關(guān)的特殊能力。
回收路由策略:
傳統(tǒng)MoE常因?qū)<页d而丟棄過多tokens。Hunyuan-Large設(shè)計了專家回收機(jī)制,保持相對均衡的負(fù)載,充分利用訓(xùn)練數(shù)據(jù),保證模型的訓(xùn)練穩(wěn)定性和收斂速度。

專家特定學(xué)習(xí)率適配策略:
不同專家承載的tokens差異巨大,應(yīng)設(shè)定不同學(xué)習(xí)率,如共享專家使用較大的學(xué)習(xí)率,確保每個子模型有效地從數(shù)據(jù)中學(xué)習(xí)并有助于整體性能。
高質(zhì)量合成數(shù)據(jù)
混元團(tuán)隊開發(fā)了一套完整的高質(zhì)量數(shù)據(jù)合成流程,主要包括四個步驟:指令生成、指令進(jìn)化、回答生成和回答過濾。

在指令生成階段,混元團(tuán)隊使用高質(zhì)量的數(shù)據(jù)源作為種子,覆蓋多個領(lǐng)域和不同復(fù)雜度,確保指令的多樣性和全面性。
接下來是指令演化階段,通過提升指令的清晰度和信息量,擴(kuò)充低資源領(lǐng)域的指令,并逐步提升指令的難度,使得指令更加豐富、精準(zhǔn)和具有挑戰(zhàn)性。
在回答生成階段,混元團(tuán)隊采用專門的模型針對不同領(lǐng)域生成專業(yè)的答案。這些模型在規(guī)模和設(shè)計上各有不同,以確保生成的回答能夠滿足不同領(lǐng)域的要求。
最后是回答過濾階段,混元團(tuán)隊采用critique模型對生成的回答進(jìn)行質(zhì)量評估,并進(jìn)行自一致性檢查,以確保輸出的答案是高質(zhì)量的。
通過這四步合成流程,混元團(tuán)隊能夠生成大量高質(zhì)量、多樣化的指令-回答數(shù)據(jù)對,為MoE模型的訓(xùn)練提供了豐富、優(yōu)質(zhì)的數(shù)據(jù)支持。
這種數(shù)據(jù)合成方法不僅提高了模型的訓(xùn)練效率,也極大地促進(jìn)了模型在多種下游任務(wù)上的表現(xiàn)。
長文能力優(yōu)化
為了實(shí)現(xiàn)強(qiáng)大的長文本處理能力,混元團(tuán)隊在訓(xùn)練過程中采用了多項策略。
首先是分階段訓(xùn)練,第一階段處理32K tokens的文本,第二階段將文本長度擴(kuò)展至256K tokens。在每個階段,都使用約100億tokens的訓(xùn)練數(shù)據(jù),確保模型能夠充分學(xué)習(xí)和適應(yīng)不同長度的文本。
在訓(xùn)練數(shù)據(jù)的選擇上,25%為自然長文本,如書籍、代碼等,以提供真實(shí)的長文本樣本;其余75%為普通長度的數(shù)據(jù)。這種數(shù)據(jù)組合策略確保了模型在獲得長文理解能力的同時,也能保持在普通長度文本上的基礎(chǔ)處理能力。
此外,為了更好地處理超長序列中的位置信息,混元團(tuán)隊對位置編碼進(jìn)行了優(yōu)化。他們采用了RoPE位置編碼方法,并在256K tokens階段將base frequency擴(kuò)展到10億。這種優(yōu)化方式能夠有效地處理超長序列中的位置信息,提升模型對長文本的理解和生成能力。
除了在公開數(shù)據(jù)集上進(jìn)行評測,混元團(tuán)隊還開發(fā)了一個名為”企鵝卷軸”的長文本評測數(shù)據(jù)集。
“企鵝卷軸”包含四個主要任務(wù):信息抽取、信息定位、定性分析和數(shù)值推理。

不同于現(xiàn)有的長文本基準(zhǔn)測試,”企鵝卷軸”有以下幾個優(yōu)勢:
- 數(shù)據(jù)多樣性:”企鵝卷軸”包含了各種真實(shí)場景下的長文本,如財務(wù)報告、法律文檔、學(xué)術(shù)論文等,最長可達(dá)128K tokens。
- 任務(wù)全面性:數(shù)據(jù)集涵蓋了多個難度層次的任務(wù),構(gòu)建了一個全面的長文本處理能力分類體系。
- 對話數(shù)據(jù):引入了多輪對話數(shù)據(jù),模擬真實(shí)的長文本問答場景。
- 多語言支持:提供中英雙語數(shù)據(jù),滿足多語言應(yīng)用需求。
推理加速優(yōu)化
為了進(jìn)一步提升Hunyuan-Large的推理效率,混元團(tuán)隊采用了多種優(yōu)化技術(shù),其中最關(guān)鍵的是KV Cache壓縮。
主要結(jié)合了兩種方法:GQA(Grouped-Query Attention)和CLA(Cross-Layer Attention)。
GQA通過設(shè)置8個KV head組,壓縮了head維度的KV cache;而CLA則通過每2層共享KV cache,壓縮了層維度的內(nèi)存占用。
通過這兩種策略的組合,混元MoE模型的KV cache內(nèi)存占用降低了約95%,而模型性能基本保持不變。這種顯著的內(nèi)存優(yōu)化不僅大幅提升了推理效率,也使得模型更易于部署,適配各種實(shí)際應(yīng)用場景。

后訓(xùn)練優(yōu)化
預(yù)訓(xùn)練的基礎(chǔ)上,混元團(tuán)隊采用了兩階段的后訓(xùn)練策略,包括監(jiān)督微調(diào)(SFT)和人類反饋強(qiáng)化學(xué)習(xí)(RLHF),以進(jìn)一步提升模型在關(guān)鍵領(lǐng)域的能力和人類對齊程度。
在SFT階段,混元團(tuán)隊使用了超過100萬條高質(zhì)量數(shù)據(jù),覆蓋了包括數(shù)學(xué)、推理、問答、編程等多個關(guān)鍵能力領(lǐng)域。為了確保數(shù)據(jù)的高質(zhì)量,團(tuán)隊采用了多重質(zhì)量控制措施,包括規(guī)則篩選、模型篩選和人工審核。整個SFT過程分為3輪,學(xué)習(xí)率從2e-5衰減到2e-6,以充分利用數(shù)據(jù),同時避免過擬合。
在RLHF階段,混元團(tuán)隊主要采用了兩階段離線和在線DPO結(jié)合。離線訓(xùn)練使用預(yù)先構(gòu)建的人類偏好數(shù)據(jù)集,以增強(qiáng)可控性;在線訓(xùn)練則利用當(dāng)前策略模型生成多個回復(fù),并用獎勵模型選出最佳回復(fù),以提高模型的泛化能力。
同時,他們還使用了指數(shù)滑動平均策略,緩解了reward hacking問題,確保了訓(xùn)練過程的平穩(wěn)和收斂。
One More Thing
在發(fā)布會現(xiàn)場,騰訊混元大模型算法負(fù)責(zé)人康戰(zhàn)輝還透露,Hunyuan-Large之后,還會考慮逐步開源中小型號的模型,適應(yīng)個人開發(fā)者、邊緣側(cè)開發(fā)者的需求。

另外騰訊同期開源的3D大模型可移步這里了解。
相關(guān)閱讀

京東通過港交所上市聆訊 劉強(qiáng)東持股15.1% 騰訊持股17.8%
6月5日,京東通過港交所上市聆訊,招股書中披露了最新持股情況以及IPO融資的資金用途等信息。



騰訊多媒體實(shí)驗(yàn)室首次攜自由視角技術(shù)亮相中國網(wǎng)媒論壇 觀看體驗(yàn)廣受好評
攜自由視角技術(shù)首次亮相中國網(wǎng)媒論壇,為與會者帶來了360°無死角的互動體驗(yàn)





