
新架構(gòu)Mamba更新二代!作者:別爭了,數(shù)學(xué)上Transformer和SSM是一回事
統(tǒng)一兩大序列建模架構(gòu)
夢晨 發(fā)自 凹非寺
量子位 | 公眾號(hào) QbitAI
Transformer挑戰(zhàn)者、新架構(gòu)Mamba,剛剛更新了第二代:
Mamba-2,狀態(tài)空間擴(kuò)大8倍,訓(xùn)練速度提高50%!
更重要的是,團(tuán)隊(duì)研究發(fā)現(xiàn)原來Transformer和狀態(tài)空間模型(SSM)竟然是近親??
兩大主流序列建模架構(gòu),在此統(tǒng)一了。

沒錯(cuò),這篇論文的提出的重磅發(fā)現(xiàn):Transformer中的注意力機(jī)制與SSM存在著非常緊密的數(shù)學(xué)聯(lián)系。

團(tuán)隊(duì)通過提出一個(gè)叫結(jié)構(gòu)化狀態(tài)空間二元性(Structured State Space Duality,SSD)的理論框架,把這兩大模型家族統(tǒng)一了起來。

Mamba一代論文年初被ICLR拒稿,當(dāng)時(shí)還讓許多學(xué)者集體破防,引起一陣熱議。
這次二代論文在理論和實(shí)驗(yàn)上都更豐富了,成功入選ICML 2024。

作者依然是Albert Gu和Tri Dao兩位。
他們透露,論文題目中“Transformers are SSMs”是致敬了4年前的線性注意力經(jīng)典論文“Transformers are RNNs”。

那么,SSM和注意力機(jī)制究竟是怎么聯(lián)系起來的,Mamba-2模型層面又做出哪些改進(jìn)?
統(tǒng)一SSM和注意力機(jī)制
Transformer的核心組件是注意力機(jī)制,SSM模型的核心則是一個(gè)線性時(shí)變系統(tǒng)。
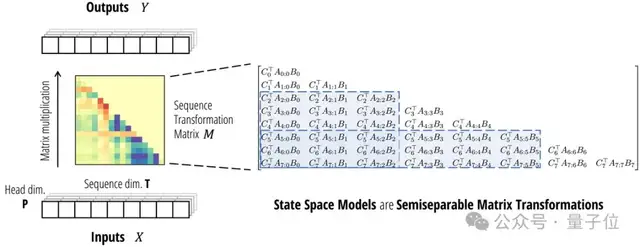
兩者看似不相關(guān),但論文指出:它們都可以表示成可半分離矩陣(Semiseparable Matrices)的變換。
先從SSM的視角來看。
SSM本身就定義了一個(gè)線性映射,恰好對(duì)應(yīng)了一個(gè)半可分離矩陣。
半可分離矩陣有著特殊的低秩結(jié)構(gòu),這種結(jié)構(gòu)又恰好對(duì)應(yīng)了SSM模型中的狀態(tài)變量。
于是,矩陣乘法就相當(dāng)于SSM的線性時(shí)變系統(tǒng)了。帶選擇性的SSM本質(zhì)上就是一種廣義線性注意力機(jī)制。
從注意力的視角看又如何?
團(tuán)隊(duì)試圖以更抽象方式來刻畫注意力機(jī)制的本質(zhì),畢竟“Softmax自注意力”只是眾多可能形式中的一種。
更一般地,任意帶掩碼的注意力機(jī)制,都可以表示為4個(gè)張量的縮并(Contraction)。
其中QKV對(duì)應(yīng)注意力中的query,key,value,L對(duì)應(yīng)掩碼矩陣。

借助這一聯(lián)系,它們在線性注意力的基礎(chǔ)上提出了結(jié)構(gòu)化掩碼注意力SMA(Structured Masked Attention)。
當(dāng)注意力的掩碼矩陣是半可分離的,就與SSM等價(jià)了。

基于這個(gè)發(fā)現(xiàn),作者進(jìn)一步推導(dǎo)出兩種等價(jià)的計(jì)算形式,這就是本文核心思想”狀態(tài)空間二元性”SSD的由來。

Mamba-2:更強(qiáng)學(xué)習(xí)能力,更快訓(xùn)練推理
基于SSD思想的新算法,Mamba-2支持更大的狀態(tài)維度(從16擴(kuò)大到256),從而學(xué)習(xí)更強(qiáng)的表示能力。
新方法基于塊分解矩陣乘法,利用了GPU的存儲(chǔ)層次結(jié)構(gòu),提高訓(xùn)練速度。

架構(gòu)設(shè)計(jì)上,Mamba-2簡化了塊的設(shè)計(jì),同時(shí)受注意力啟發(fā)做出一些改動(dòng),借鑒多頭注意力創(chuàng)建了多輸入SSM。

有了與注意力之間的聯(lián)系,SSD還可以輕松將Transformer架構(gòu)多年來積累起來的優(yōu)化方法引入SSM。
比如引入張量并行和序列并行,擴(kuò)展到更大的模型和更長的序列。
又比如引入可變序列長度,以實(shí)現(xiàn)更快的微調(diào)和推理。

Mamba-2的SSD層比Mamba-1中的關(guān)聯(lián)掃描快很多,使團(tuán)隊(duì)能夠增加狀態(tài)維度并提高模型質(zhì)量。

實(shí)驗(yàn)中,3B參數(shù)規(guī)模的Mamba-2,在300B tokens訓(xùn)練,超越了相同規(guī)模的Mamba-1和Transformer。

Mamba-2在需要更大狀態(tài)容量的任務(wù)上比Mamba-1有了顯著改進(jìn),例如硬關(guān)聯(lián)召回任務(wù)?(MQAR)。

團(tuán)隊(duì)還對(duì)Mamba-2+注意力的混合架構(gòu)模型做了一些實(shí)驗(yàn)。發(fā)現(xiàn)4-6個(gè)注意力層與Mamba-2層混合模型的性能,甚至優(yōu)于Transformer++(原版結(jié)構(gòu)+現(xiàn)代最佳實(shí)踐)和純Mamba-2。

作者Tri Dao認(rèn)為,這說明了Attention和SSM兩種機(jī)制可以互為補(bǔ)充,另外他還提出了對(duì)未來研究方向的思考。

最后,除了52頁的論文之外,兩位作者還撰寫了四篇更易讀的系列博客文章。

他們特別建議:先看博客,再看論文。

對(duì)Mamba-2模型或者狀態(tài)空間二元性理論感興趣的,可以讀起來了~
博客(兩個(gè)地址內(nèi)容一樣):
https://tridao.me/blog/
https://goombalab.github.io/blog/
論文:
https://arxiv.org/abs/2405.21060
代碼和模型權(quán)重:
https://github.com/state-spaces/mamba
參考鏈接:
[1]https://x.com/_albertgu/status/1797651240396144758
[2]https://x.com/tri_dao/status/1797650443218436165
相關(guān)閱讀


華為北大等聯(lián)手打造的Transformer竟在CV領(lǐng)域超過了CNN:多項(xiàng)底層視覺任務(wù)達(dá)到SOTA
多種任務(wù)共享一個(gè)Transformer 模塊。



顏水成團(tuán)隊(duì)開源VOLO:無需額外數(shù)據(jù),首次在ImageNet上達(dá)到87.1%的精度
Transformer揚(yáng)眉吐氣:我們真的不比CNN差



