
北大團(tuán)隊用Diffusion升級DragGAN,泛化更強(qiáng)生成質(zhì)量更高,點一點「大山拔地而起」
DragonDiffusion來了
明敏 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
北大團(tuán)隊最新工作,用擴(kuò)散模型也能實現(xiàn)拖拉拽P圖!
點一點,就能讓雪山長個兒:

或者讓太陽升起:

這就是DragonDiffusion,由北京大學(xué)張健老師團(tuán)隊VILLA(Visual-Information Intelligent Learning LAB),依托北京大學(xué)深圳研究生院-兔展智能AIGC聯(lián)合實驗室,聯(lián)合騰訊ARC Lab共同帶來。
它可以被理解為DragGAN的變種。
DragGAN如今GitHub Star量已經(jīng)超過3w,它的底層模型基于GAN(生成對抗網(wǎng)絡(luò))。

一直以來,GAN在泛化能力和生成圖像質(zhì)量上都有短板。
而這剛好是擴(kuò)散模型(Diffusion Model)的長處。
所以張健老師團(tuán)隊就將DragGAN范式推廣到了Diffusion模型上。
該成果發(fā)布時登上知乎熱榜。

有人評價說,這解決了Stable Diffusion生成圖片中部分殘缺的問題,可以很好進(jìn)行控制重繪。

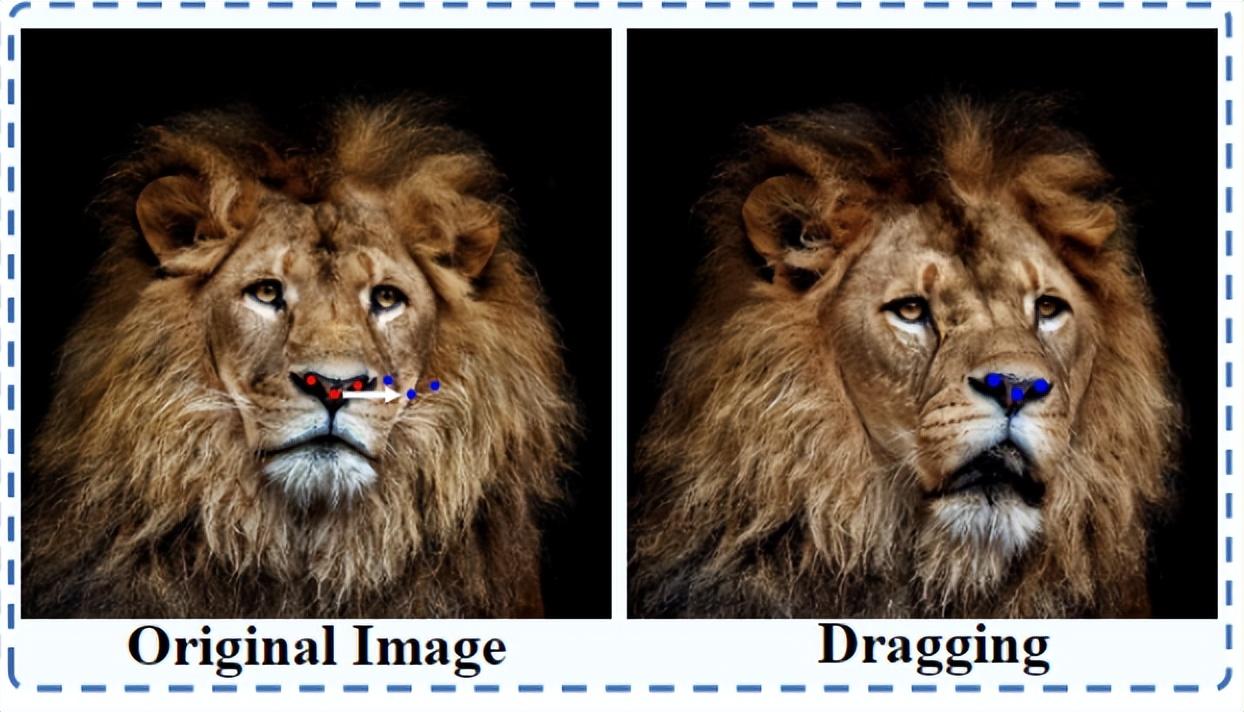
讓獅子在照片中轉(zhuǎn)頭
Dragon Diffusion能帶來的效果還包括改變車頭形狀:

讓沙發(fā)逐漸變長:

再或者是手動瘦臉:

也能替換照片中的物體,比如把甜甜圈放到另一張圖片里:

或者是給獅子轉(zhuǎn)轉(zhuǎn)頭:
該方法框架中包括兩個分支,引導(dǎo)分支(guidance branch)和生成分支(generation branch)。
首先,待編輯圖像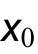 通過Diffusion的逆過程,找到該圖像在擴(kuò)散隱空間中的表示,作為兩個分支的輸入。
通過Diffusion的逆過程,找到該圖像在擴(kuò)散隱空間中的表示,作為兩個分支的輸入。
其中,引導(dǎo)分支會對原圖像進(jìn)行重建,重建過程中將原圖像中的信息注入下方的生成分支。
生成分支的作用是引導(dǎo)信息對原圖像進(jìn)行編輯,同時保持主要內(nèi)容與原圖一致。
根據(jù)擴(kuò)散模型中間特征具有強(qiáng)對應(yīng)關(guān)系,DragonDiffusion在每一個擴(kuò)散迭補(bǔ)中,將兩個分支的隱變量 通過相同的UNet去噪器轉(zhuǎn)換到特征域。
通過相同的UNet去噪器轉(zhuǎn)換到特征域。
然后利用兩個mask,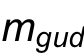 和
和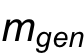 區(qū)域。標(biāo)定拖動內(nèi)容在原圖像和編輯后圖像中的位置,然后約束的內(nèi)容出現(xiàn)在區(qū)域。
區(qū)域。標(biāo)定拖動內(nèi)容在原圖像和編輯后圖像中的位置,然后約束的內(nèi)容出現(xiàn)在區(qū)域。
論文通過cosin距離來度量兩個區(qū)域的相似度,并對相似度進(jìn)行歸一化:
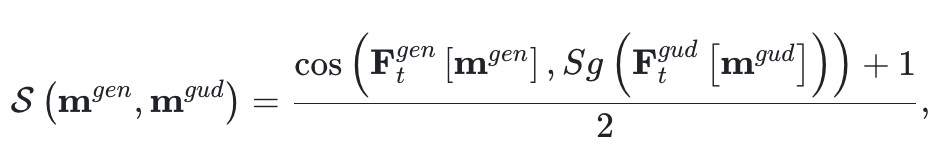
除了約束編輯后的內(nèi)容變化,還應(yīng)該保持其他未編輯區(qū)域與原圖的一致性。這里也同樣通過對應(yīng)區(qū)域的相似度進(jìn)行約束。最終,總損失函數(shù)設(shè)計為:
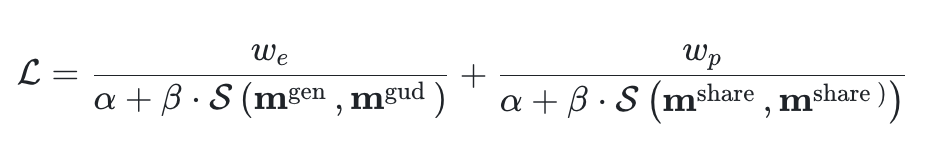
在編輯信息的注入方面,論文通過score-based Diffusion將有條件的擴(kuò)散過程視為一個聯(lián)合的score function:
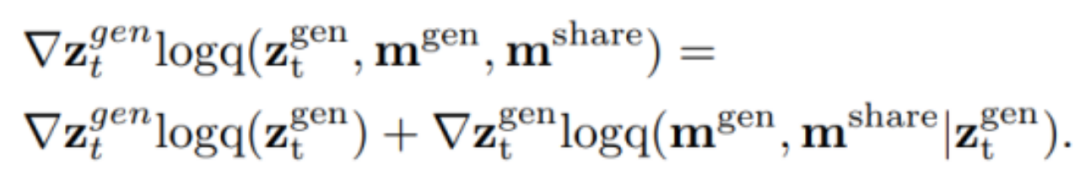
將編輯信號通過基于特征強(qiáng)對應(yīng)關(guān)系的score function轉(zhuǎn)化為梯度,對擴(kuò)散過程中的隱變量 進(jìn)行更新。
進(jìn)行更新。
為了兼顧語義和圖形上的對齊,作者在這個引導(dǎo)策略的基礎(chǔ)上引入了多尺度引導(dǎo)對齊設(shè)計。
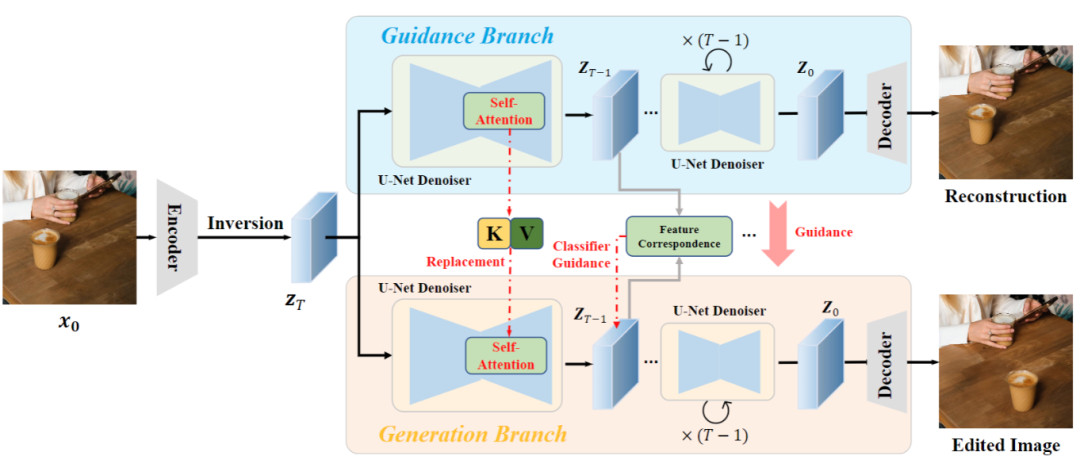
此外,為了進(jìn)一步保證編輯結(jié)果和原圖的一致性,DragonDiffusion方法中設(shè)計了一種跨分支的自注意力機(jī)制。
具體做法是利用引導(dǎo)分支自注意力模塊中的Key和Value替換生成分支自注意力模塊中的Key和Value,以此來實現(xiàn)特征層面的參考信息注入。
最終,論文提出的方法,憑借其高效的設(shè)計,為生成的圖像和真實圖像提供了多種編輯模式。
這包括在圖像中移動物體、調(diào)整物體大小、替換物體外觀和圖像內(nèi)容拖動。

在該方法中,所有的內(nèi)容編輯和保存信號都來自圖像本身,無需任何微調(diào)或訓(xùn)練附加模塊,這能簡化編輯過程。
研究人員在實驗中發(fā)現(xiàn),神經(jīng)網(wǎng)絡(luò)第一層太淺,無法準(zhǔn)確重建圖像。但如果到第四層重建又會太深,效果同樣很差。在第二/三層的效果最佳。

相較于其他方法,Dragon Diffusion的消除效果也表現(xiàn)更好。

來自北大張健團(tuán)隊等
該成果由北京大學(xué)張健團(tuán)隊、騰訊ARC Lab和北京大學(xué)深圳研究生院-兔展智能AIGC聯(lián)合實驗室共同帶來。
張健老師團(tuán)隊曾主導(dǎo)開發(fā)T2I-Adapter,能夠?qū)U(kuò)散模型生成內(nèi)容進(jìn)行精準(zhǔn)控制。
在GitHub上攬星超2k。
該技術(shù)已被Stable Diffusion官方使用,作為涂鴉生圖工具Stable Doodle的核心控制技術(shù)。

兔展智能聯(lián)手北大深研院建立的AIGC聯(lián)合實驗室,近期在圖像編輯生成、法律AI產(chǎn)品等多個領(lǐng)域取得突破性技術(shù)成果。
就在幾周前,北大-兔展AIGC聯(lián)合實驗室就推出了登上知乎熱搜第一的的大語言模型產(chǎn)品ChatLaw,在全網(wǎng)帶來千萬曝光同時,也引發(fā)了一輪社會討論。
聯(lián)合實驗室將聚焦以CV為核心的多模態(tài)大模型,在語言領(lǐng)域繼續(xù)深挖ChatLaw背后的ChatKnowledge大模型,解決法律金融等垂直領(lǐng)域防幻覺,可私有化、數(shù)據(jù)安全問題。
據(jù)悉,實驗室近期還會推出原創(chuàng)對標(biāo)Stable Diffusion的大模型。
論文地址:
https://arxiv.org/abs/2307.02421
項目主頁:
https://mc-e.github.io/project/DragonDiffusion/
- DeepSeek-V3.2-Exp第一時間上線華為云2025-09-29
- 你的AI助手更萬能了!天禧合作字節(jié)扣子,解鎖無限新功能2025-09-26
- 你的最快安卓芯片發(fā)布了!全面為Agent鋪路2025-09-26
- 任少卿在中科大招生了!碩博都可,推免學(xué)生下周一緊急面試2025-09-20
相關(guān)閱讀

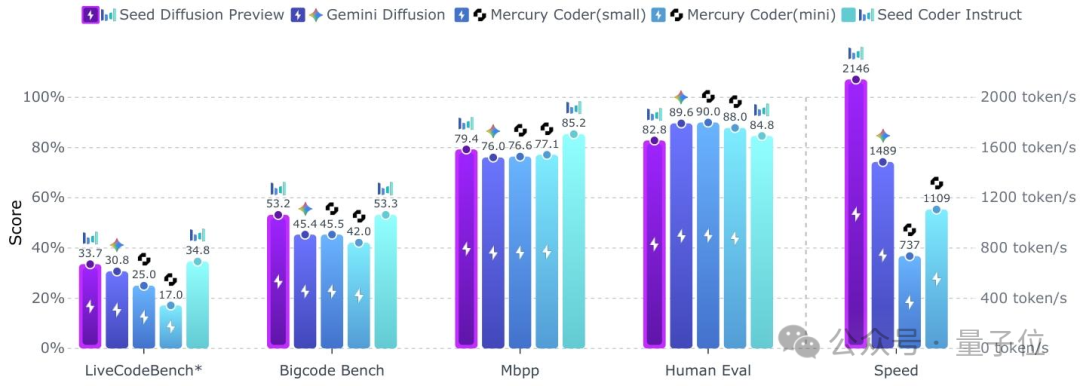
字節(jié)Seed發(fā)布擴(kuò)散語言模型,推理速度達(dá)2146 tokens/s,比同規(guī)模自回歸快5.4倍
字節(jié)也押注離散擴(kuò)散路線了


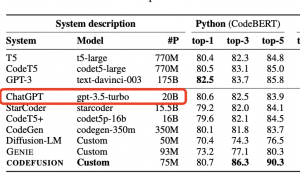
ChatGPT真實參數(shù)只有200億,首次被微軟曝光!網(wǎng)友驚:要開源了?
業(yè)內(nèi)首個用擴(kuò)散模型做代碼生成。





