
AI分割一切!智源提出通用分割模型SegGPT,「一通百通」的那種
SegmentAnything Model
允中 發自 凹非寺
量子位 | 公眾號 QbitAI
視覺領域的GPT-3時刻,真的要來了?
Meta分割一切的SAM(SegmentAnything Model)剛炸完場,幾乎同時,國內的智源研究院視覺團隊也提出了通用分割模型SegGPT——
Segment Everything in Context,首個利用視覺上下文完成各種分割任務的通用視覺模型。
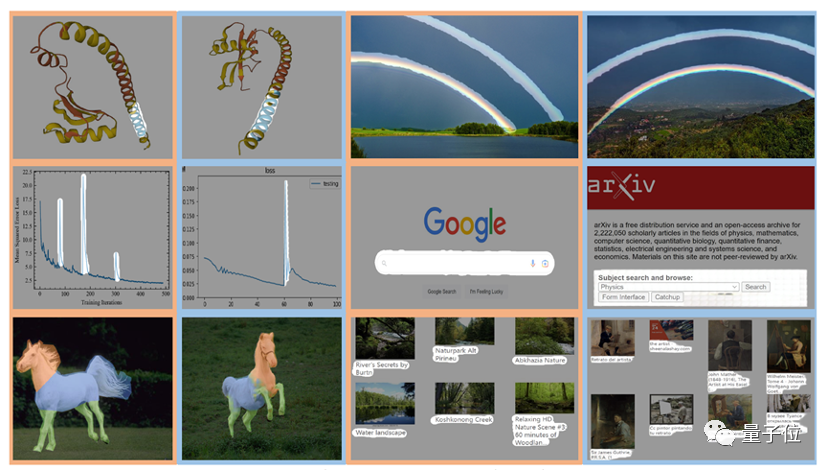
就像這樣,在一張畫面中標注出彩虹,就能批量分割其他畫面中的彩虹。

和 SAM 相比,視覺模型的 In-context 能力是最大差異點 :
- SegGPT “一通百通”:可使用一個或幾個示例圖片和對應的掩碼即可分割大量測試圖片。用戶在畫面上標注識別一類物體,即可批量化識別分割出其他所有同類物體,無論是在當前畫面還是其他畫面或視頻環境中。
- SAM“一觸即通”:通過一個點、邊界框或一句話,在待預測圖片上給出交互提示,識別分割畫面上的指定物體。
這也就意味著,SAM的精細標注能力,與SegGPT的批量化標注分割能力,還能進一步相結合,產生全新的CV應用。

具體而言,SegGPT 是智源通用視覺模型 Painter 的衍生模型,針對分割一切物體的目標做出優化。
SegGPT 訓練完成后無需微調,只需提供示例即可自動推理并完成對應分割任務,包括圖像和視頻中的實例、類別、零部件、輪廓、文本、人臉等等。
該模型具有以下優勢能力:
- 通用能力:SegGPT具有上下文推理能力,模型能夠根據上下文(prompt)中提供掩碼,對預測進行自適應的調整,實現對“everything”的分割,包括實例、類別、零部件、輪廓、文本、人臉、醫學圖像等。
- 靈活推理能力:支持任意數量的prompt;支持針對特定場景的tuned prompt;可以用不同顏色的mask表示不同目標,實現并行分割推理。
- 自動視頻分割和追蹤能力:以第一幀圖像和對應的物體掩碼作為上下文示例,SegGPT能夠自動對后續視頻幀進行分割,并且可以用掩碼的顏色作為物體的ID,實現自動追蹤。
更多案例展示
作者在廣泛的任務上對SegGPT進行了評估,包括少樣本語義分割、視頻對象分割、語義分割和全景分割。下圖中具體展示了SegGPT在實例、類別、零部件、輪廓、文本和任意形狀物體上的分割結果。

用畫筆大致圈出行星環帶(左圖),在預測圖中準確輸出目標圖像中的行星環帶(右圖)。

SegGPT能夠根據用戶提供的宇航員頭盔掩碼這一上下文(左圖),在新的圖片中預測出對應的宇航員頭盔區域(右圖)。
訓練方法
SegGPT將不同的分割任務統一到一個通用的上下文學習框架中,通過將各類分割數據轉換為相同格式的圖像來統一各式各樣的數據形式。
具體來說,SegGPT的訓練被定義為一個上下文著色問題,對于每個數據樣本都有隨機的顏色映射。
目標是根據上下文完成各種任務,而不是依賴于特定的顏色。訓練后,SegGPT可以通過上下文推理在圖像或視頻中執行任意分割任務,例如實例、類別、零部件、輪廓、文本等。
論文地址:https://arxiv.org/abs/2211.07636
代碼地址:https://github.com/baaivision/Painter
Demo:https://huggingface.co/spaces/BAAI/SegGPT
— 完 —
- 蘋果芯片主管也要跑路!庫克被曝出現健康問題2025-12-07
- 世界模型和具身大腦最新突破:90%生成數據,VLA性能暴漲300%|開源2025-12-02
- 谷歌新架構突破Transformer超長上下文瓶頸!Hinton靈魂拷問:后悔Open嗎?2025-12-05
- 90后華人副教授突破30年數學猜想!結論與生成式AI直接相關2025-11-26
相關閱讀


登頂五大數據集!最強目標跟蹤算法SiamRPN++開源了,商湯出品 | CVPR 2019 Oral
SiamRPN++在5個大型跟蹤數據集上,都拿到了最好成績。








