子豪 發自 凹非寺
量子位 報道 | 公眾號 QbitAI
量化,作為神經網絡壓縮和加速的重要手段,往往要依賴真實數據進行校準。
此前,一些無數據量化方法雖然解決了數據依賴問題,但是卻存在數據分布和樣本同質化問題,致使量化模型的精度下降。
現在,為解決這一問題,來自北航、耶魯大學、商湯研究院的研究團隊,共同開發了多樣化的樣本生成(DSG)方法。
這一研究成果,不僅解決了數據依賴問題,還能有效避免同質化、增強數據的多樣性,甚至獲得與真實數據媲美的效果。

△多樣化樣本生成(DSG)方法
這篇論文已經入選CVPR 2021 Oral。
不妨來了解一下這項研究。
松弛對齊分布(SDA):解決分布同質化問題
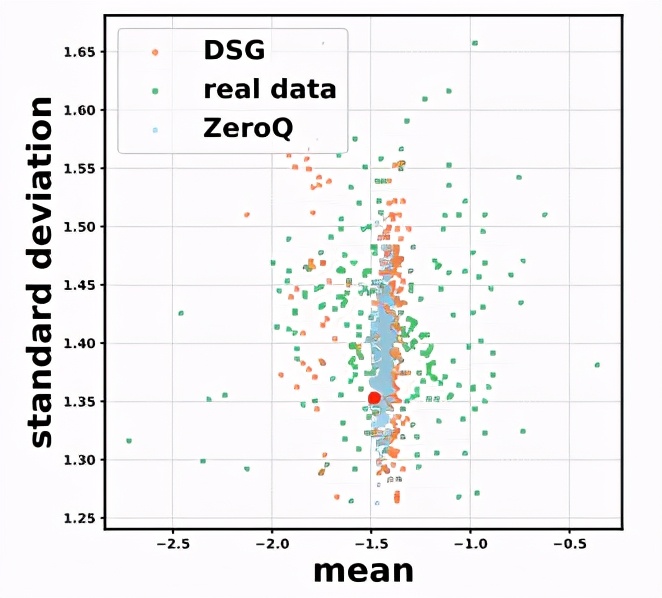
由于合成數據是去匹配批歸一化(BN)統計量參數,因此,每層的特征分布容易過擬合,產生在數據分布上的同質化現象,無法獲得真實數據那樣多樣化的分布。

△生成數據的分布同質化問題
為解決這一問題,研究團隊提出了一種松弛對齊批歸一化的數據分布的方法(SDA),為均值和標準差引入松弛量(δi)和(γi),就是通過在原始的批歸一化統計量損失函數中,添加松弛常數,允許合成數據與批歸一化層的統計量之間存在差距,松弛對BN層參數的約束。
第 i 個批歸一化層的損失項變為如下形式: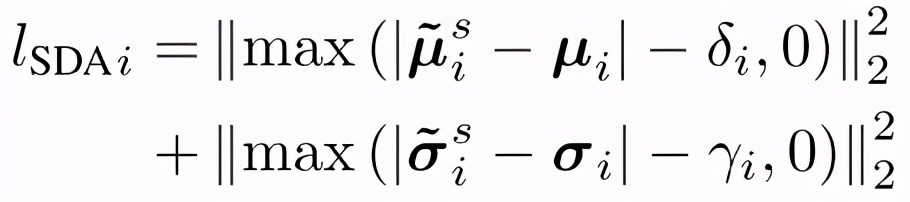
在特定范圍內,合成數據的統計量會在寬松的約束下波動。其特征分布變得更加多樣化,從而解決分布同質化問題。
一個重大挑戰是不使用真實數據,如何確定松弛量?
可以將真實數據的特征統計量與批歸一化統計量參數的差距作為參考,根據中心極限定理,可以使用高斯假設作為一個通用的近似值,即從高斯分布中隨機采樣的合成數據,來確定松弛量。
首先,從μ=0,σ=1的高斯分布中采樣1024個合成樣本,將采樣的合成樣本輸入模型,保存均值和標準差;用相應的批歸一化層的參數與之做減法。
分別表示的兩個絕對值的?百分位點,?這個在0與1之間的數決定了松弛量的取值,即決定了合成數據統計量對齊批歸一化統計量參數的松弛程度,當該值較大時,對合成數據的約束更加松散。
層級樣本增強(LSE):解決樣本同質化問題
在一些無數據量化方法中,合成數據的所有樣本都是通過同樣的目標函數被優化的,也就是直接將網絡每層的損失累加來優化所有樣本。
這就導致了樣本的特征分布統計量趨于中心化,出現樣本層面上的同質化現象,而真實數據往往是分散的。
△樣本層面的同質化問題
為解決這一問題,研究團隊提出了一種層級樣本增強的方法(LSE)。
對一個batch中每個合成圖像的損失函數,進行分別設計,從而增強每個樣本對于特定層的損失。
具體地說,對于具有N個批歸一化層的網絡,可以提供N個不同的損失項,并將它們中的每一個應用于特定數據樣本。
假設每次生成N個圖像,即批大小設置為N,和模型中的批歸一化層的個數相同。
定義一個增強矩陣:XLSE=(I+11T),
其中I是一個N維單位矩陣,1是N維全1列向量,L是包含每層損失項的向量。那么該批次的損失函數定義為:L=1T(XLSE·L)/N
其中XLSEL是N維列向量,其第i個元素表示該批次中第i個圖像的損失函數。因此,該批次的每個樣本都被施加唯一的損失項,對特定層的損失項進行了增強。
對于具有N個批歸一化層的網絡,這一方法可以同時批量生成各種樣本,每種樣本在特定層上進行增強。
采用SDA方法獲得的包含每層損失項的向量,將L替換為LSDA,從而將SDA方法與LSE方法結合。
通過上述兩種方法,解決了生成樣本的同質化問題,并且增強了多樣性。
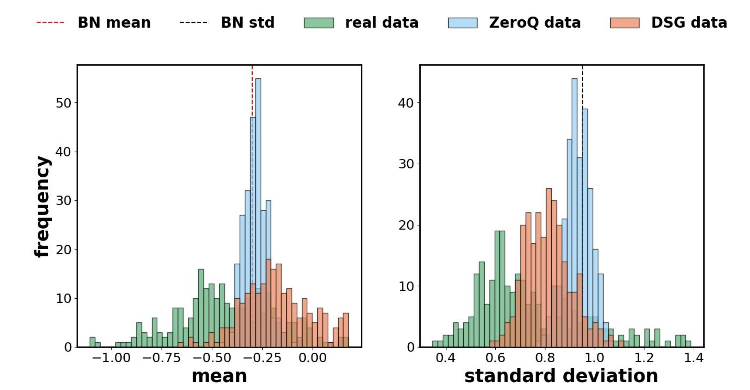
△真實樣本和生成樣本的激活值統計量分布
實驗情況
為了驗證該多樣化樣本生成方法在不同網絡架構,數據集和不同量化位寬上的效果,研究團隊在ImageNet數據集,使用各種模型與離線量化方案進行了實驗。
結果表明,在ResNet-18和ResNet-50上,DSG在各種比特設置下優于ZeroQ,尤其是在較低比特下。在某些設置下,甚至取得了超過真實數據的結果。
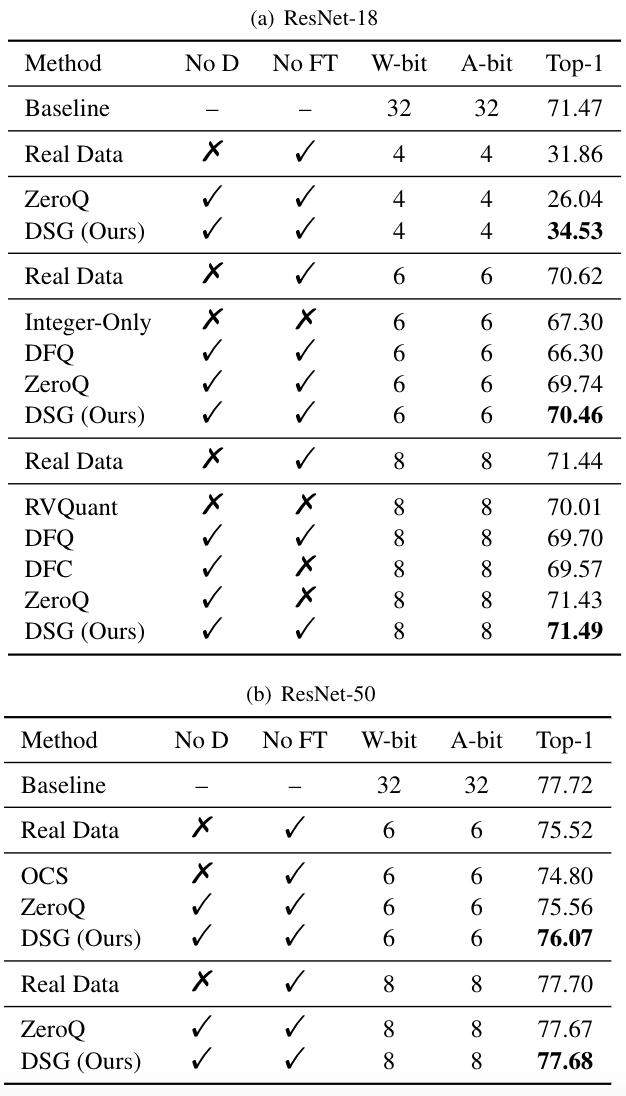
△在ResNet-18(a)和ResNet-50(b)上的對比實驗
采用各種離線校準方法時,DSG相比ZeroQ有一致的性能提升。
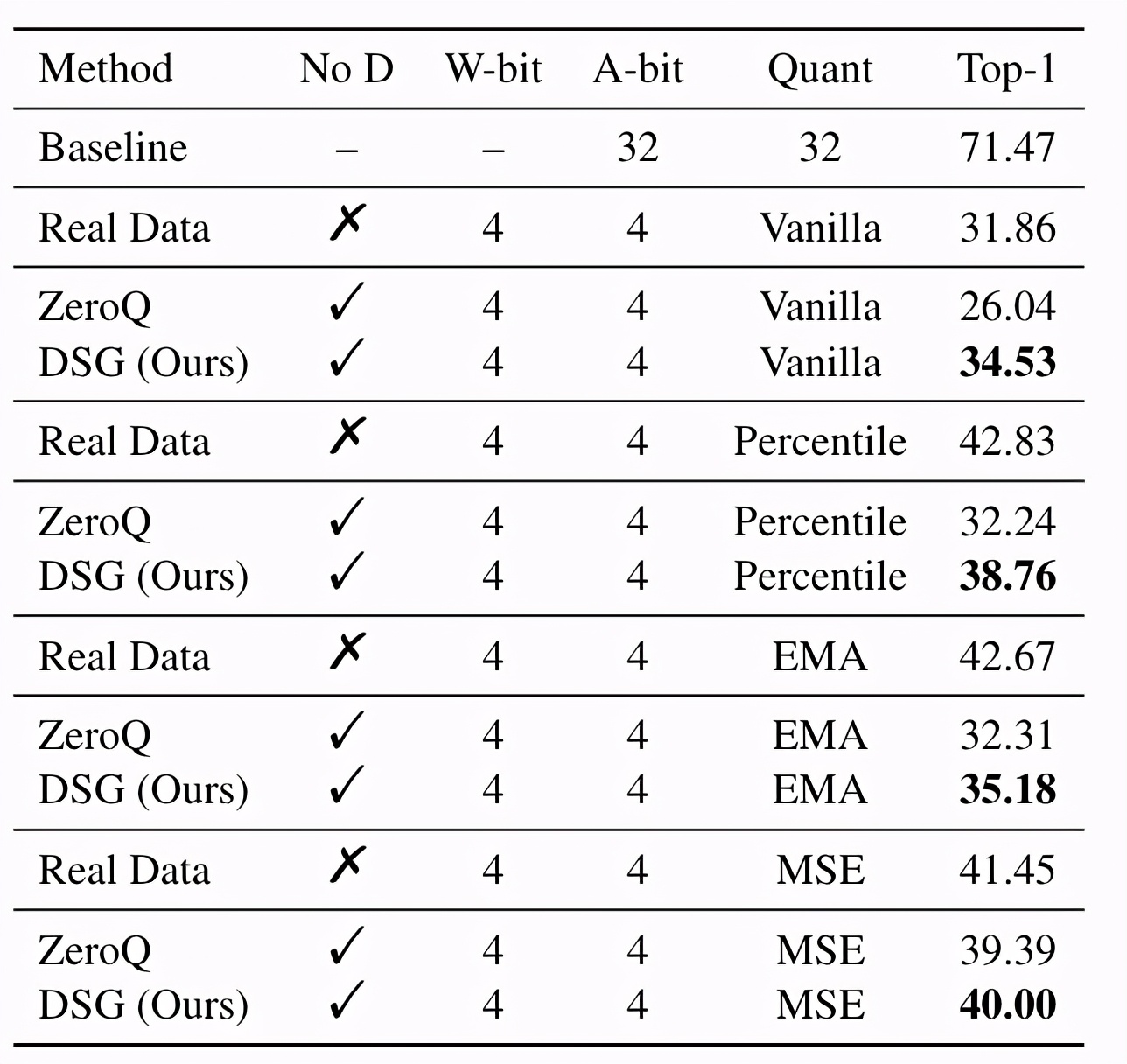
△ResNet-18上采用不同離線校準方法的實驗
為了進一步驗證DSG的有效性,研究團隊還測試了使用最先進的離線量化方法(AdaRound)時的性能。實驗中也使用了Label以及Image Prior方法。
結果表明,DSG依然帶來了性能上的提升。
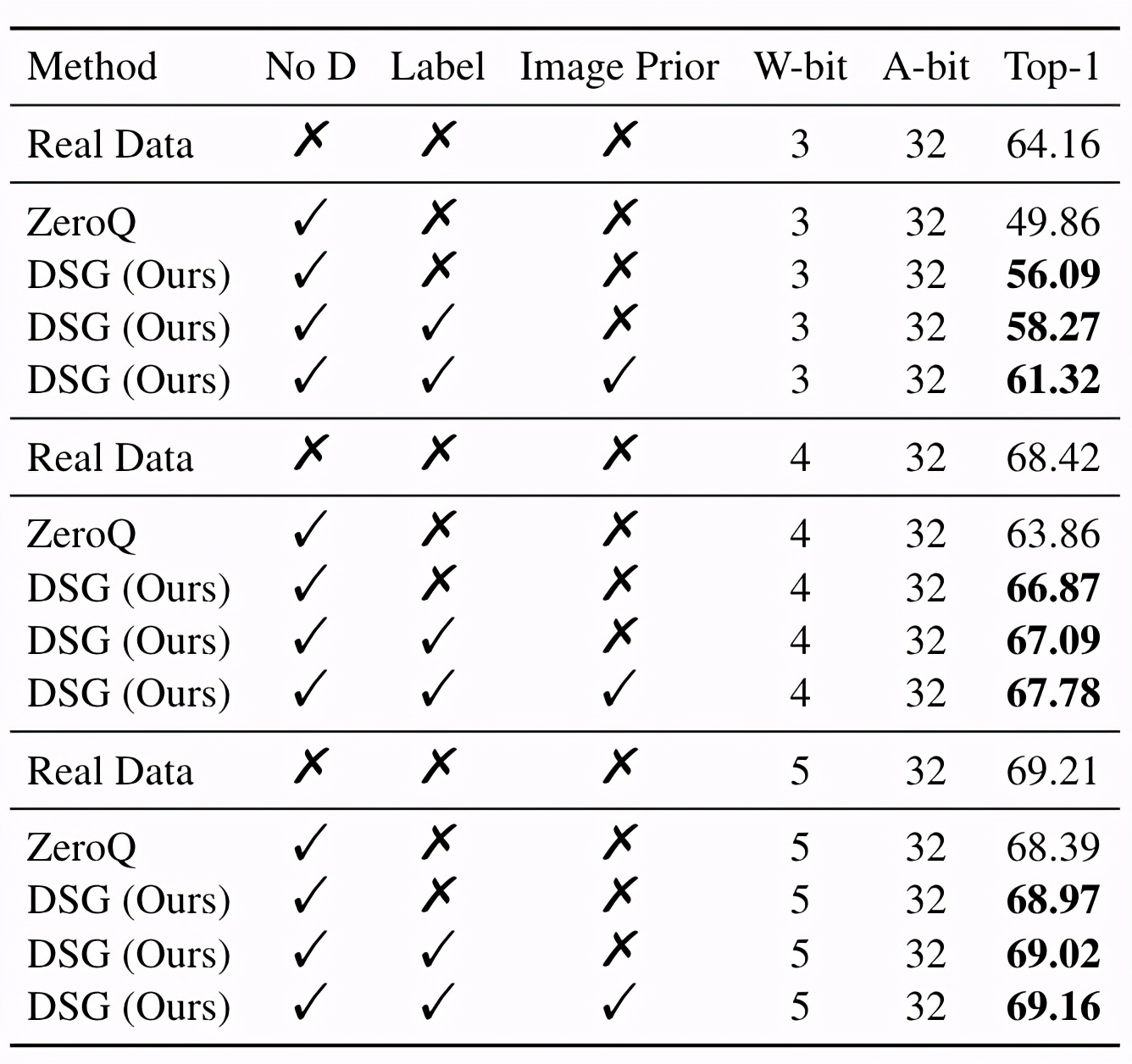
△在ResNet-18上使用AdaRound的實驗
事實表明,DSG在各種網絡訓練架構和各種離線量化方法中表現出色,尤其在超低位寬條件下,效果大大優于現有技術。
研究團隊介紹
北航劉祥龍教授團隊近年來圍繞模型低比特量化、二值量化、量化訓練等方向做出了一系列具有創新性和實用性的研究成果。包括:國際首個二值化點云模型BiPointNet、可微分軟量化DSQ、量化訓練、信息保留二值網絡IR-Net等,研究論文發表在ICLR、CVPR、ICCV等國際頂級會議和期刊上。
商湯研究院-Spring工具鏈團隊致力于通過System+AI技術打造頂尖的深度學習核心引擎。開發的模型訓練和模型部署工具鏈已服務于公司多個核心業務。團隊在量化模型的在線/離線生產、部署對齊、標準工具等方向有著明確的技術規劃。
論文共同第一作者張祥國,北京航空航天大學二年級碩士生,主要研究方向為模型量化壓縮與加速、硬件友好的深度學習,曾作為第一作者發表計算機視覺頂級會議(CVPR)一篇。
論文共同第一作者秦浩桐,北京航空航天大學博士二年級,主要研究方向為模型量化壓縮與加速、硬件友好的深度學習。曾作為第一作者發表頂級會議、期刊(ICLR,CVPR,PR)共4篇。
傳送門
論文地址:
https://arxiv.org/abs/2103.01049
劉祥龍教授團隊主頁:
http://sites.nlsde.buaa.edu.cn/~xlliu/











