
中國AI足球隊勇奪世界冠軍,騰訊出品
谷歌、英超曼城聯名舉辦
蕭簫 發自 凹非寺
量子位 報道 | 公眾號 QbitAI
一記漂亮的長傳,直接助攻射門:
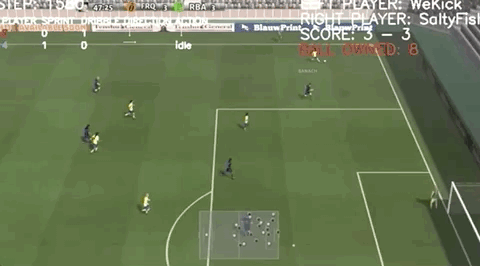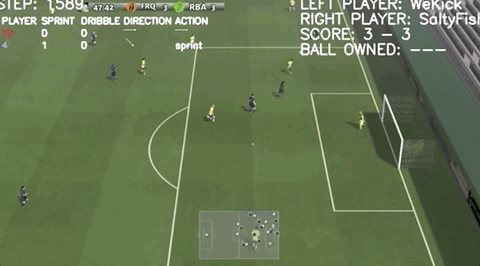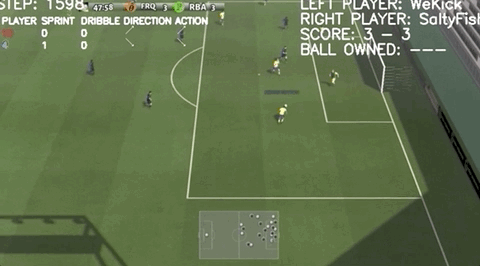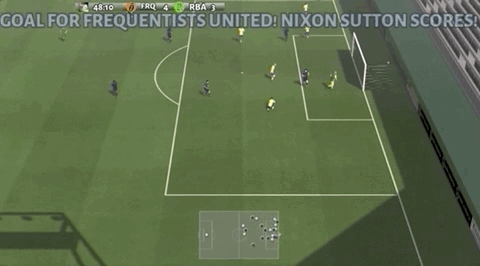
帶球連過兩人:

這樣高超的線上足球技巧,并非上手兩三年的“老玩家”做出的,而是僅僅練習了一個月的騰訊AI“絕悟”。
現在,戰勝大部分榮耀玩家后,AI“絕悟”又化名WeKick,去試手了一把谷歌舉辦的線上世界足球賽。
沒想到,輕輕松松就拿了個冠軍回來:
嗯?打完王者,還能踢FIFA?
沒錯,利用遷移學習,就能讓“足球版絕悟”WeKick,快速掌握踢足球的技巧。
但要想踢出多種策略、穩定掌握這些策略,還得采用不同的方法。
各種風格小模型,共同訓練主模型
從“絕悟”完全體遷移過來的WeKick,針對這場足球比賽,進行了策略性的調整。
與常規足球游戲的“控制整只球隊”不同,這場足球比賽中,每個隊伍需要控制其中1個智能體,與游戲中的10個內置智能體組成球隊(11vs11賽制)。
也就是說,每個智能體“球員”,都需要學習如何在隊友之間傳球,并克服對手的防守以進球。
然而采用強化學習,從0開始訓練一個會踢球的AI,相當困難。
在王者榮耀等MOBA游戲中,智能體可以學習的信號非常多,包括實時經濟、血量、經驗等。
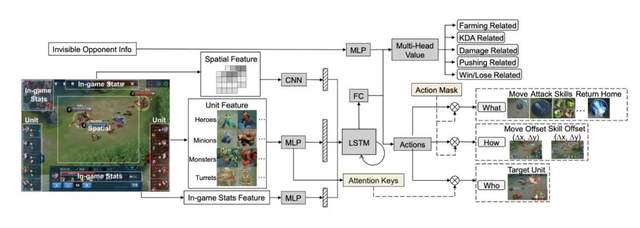
但足球游戲的激勵非常稀疏,幾乎只有“進球”這一項獎勵機制。
稀疏激勵,正是強化學習的難題之一。
為了突破這一難關,“絕悟”WeKick版本采用了3點創新,來對模型進行訓練。
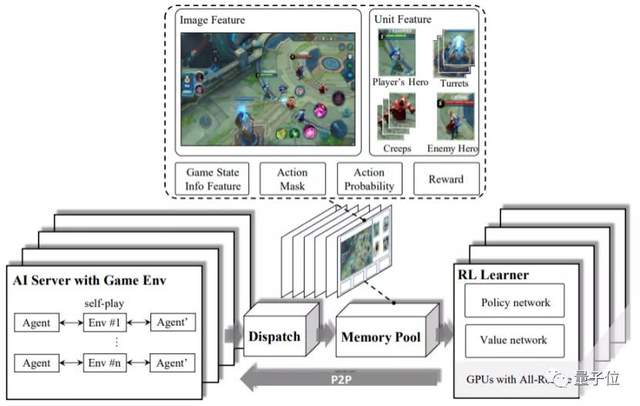
首先,是自博弈?(Self-Play)強化學習。
WeKick部署了一種異步分布式強化學習框架,雖然會犧牲訓練時的部分實時性能,但能夠提升其靈活性,支持在訓練過程中按需調整計算資源。
此外,WeKick還結合生成對抗模擬學習(GAIL)與人工設計獎勵,采用了生成對抗訓練機制。
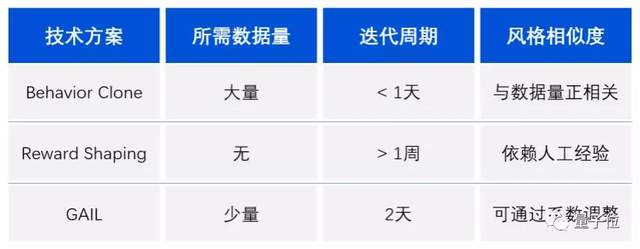
這種機制能夠模擬專家行為的狀態和動作分布,使得WeKick能夠從其他球隊中學習經驗。
之后,將GAIL訓練的模型作為固定對手,再一次進行自博弈訓練,就能提升策略的穩健性。
這種方法雖然不錯,卻存在一個缺陷。
訓練后,模型容易收斂成單一風格,容易發生因“沒見過某種打法”而表現失常、導致成績不佳的情況。
因此,WeKick的團隊想出了一種方法:采用多風格強化學習的訓練方案,讓智能體“球員”們先專精一個領域,再進行配合。

也就是說,先訓練一群具備一定競技能力的基礎模型,每個模型分別掌握運球過人、傳球配合、射門得分……
然后,基于基礎模型,訓練出多種風格的各個模型,過程中會定期加入主模型作為選手,避免模型堅持原來的風格。

最后,將這些模型集合起來,訓練一個主模型,期間除了主模型以歷史模型為對手,還會拿所有風格化基礎模型當對手,確保主模型能應對各種風格的踢球方式。
通過這3種方式訓練出來的模型WeKick,既具有豐富的足球經驗,也能準確地對抗各種不同風格的比賽技巧。
谷歌+英超,線上足球賽
這個線上足球賽Google Football,有點像是一款AI操作的足球游戲,由谷歌和英超曼城俱樂部在Kaggle上聯合舉辦。

比賽采用谷歌強化學習環境,基于開源足球游戲Gameplay Football開發,共有來自世界頂級院校、研究機構的1100多支隊伍參與挑戰。
與足球賽的比賽規則一致,線上足球賽同樣需要遵守越位、黃牌、紅牌等規則。
而在谷歌提供的足球環境中,智能體“球員”則可以做出短傳、長傳、運球、射門等動作。
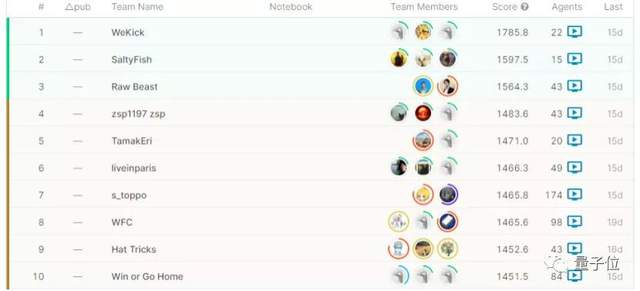
在經過幾輪廝殺后,WeKick最終以1785.8的總分,在這場競技中以顯著優勢勝出。
不過,這也并非“絕悟”第一次參加谷歌舉辦的足球賽。
在5v5的多智能體天梯賽Google Research Football League中,“絕悟”同樣取得了第一名的成績。
事實上,在游戲AI上一路向前的“絕悟”,已經歷了3次進化。
從最初攻克Atari游戲開始,到后來的圍棋AI“絕藝”,再到包括王者榮耀在內的MOBA游戲AI“絕悟”,和如今的足球游戲AI“WeKick”,這一深度強化學習智能體正變得更復雜。
騰訊AI Lab表示,它們的目標是向通用人工智能(AGI)不斷邁進。

整體訓練框架:
https://arxiv.org/abs/1912.09729
Kaggle足球賽排行榜:
https://www.kaggle.com/c/google-football/leaderboard
- 首個GPT-4驅動的人形機器人!無需編程+零樣本學習,還可根據口頭反饋調整行為2023-12-13
- IDC霍錦潔:AI PC將顛覆性變革PC產業2023-12-08
- AI視覺字謎爆火!夢露轉180°秒變愛因斯坦,英偉達高級AI科學家:近期最酷的擴散模型2023-12-03
- 蘋果大模型最大動作:開源M芯專用ML框架,能跑70億大模型2023-12-07









