
綜藝后期狂喜:編輯一幀,整個(gè)視頻跟著變!比LNA渲染快5倍,Adobe聯(lián)合出品
尚恩 發(fā)自 凹非寺
量子位 | 公眾號(hào) QbitAI
前不久跑男為了讓“kunkun”原地消失,后期只能一幀一幀的摳圖。
現(xiàn)在,只要編輯一幀,整個(gè)視頻就跟著變!


就是點(diǎn)點(diǎn)kunkun,整集就自動(dòng)消失的那種(手動(dòng)狗頭)。

Adobe Research和英屬哥倫比亞大學(xué)的研究人員發(fā)現(xiàn),使用INVE(交互式神經(jīng)視頻編輯),只需在單幀上“畫筆涂鴉”,就能自動(dòng)應(yīng)用改動(dòng)到整個(gè)視頻中。

不僅可以編輯視頻中的對(duì)象并保留空間和光影關(guān)系,甚至可以編輯移動(dòng)對(duì)象的紋理色彩。

網(wǎng)友驚呼:太牛了!

交互式神經(jīng)視頻編輯
INVE(Interactive Neural Video Editing)是一種實(shí)時(shí)視頻編輯解決方案。
研究團(tuán)隊(duì)受到分層神經(jīng)圖集(LNA)的研究啟發(fā)。測(cè)試發(fā)現(xiàn),通過使用INVE,可以將稀疏幀編輯一致地傳播到整個(gè)視頻剪輯,輔助視頻編輯過程。

視頻中的場(chǎng)景通常由非靜態(tài)背景和一個(gè)或多個(gè)前景物體組成,運(yùn)動(dòng)軌跡也會(huì)不同。
早期的2D方法需要獨(dú)立編輯每一幀,并使用幀間跟蹤來協(xié)調(diào)整個(gè)視頻。
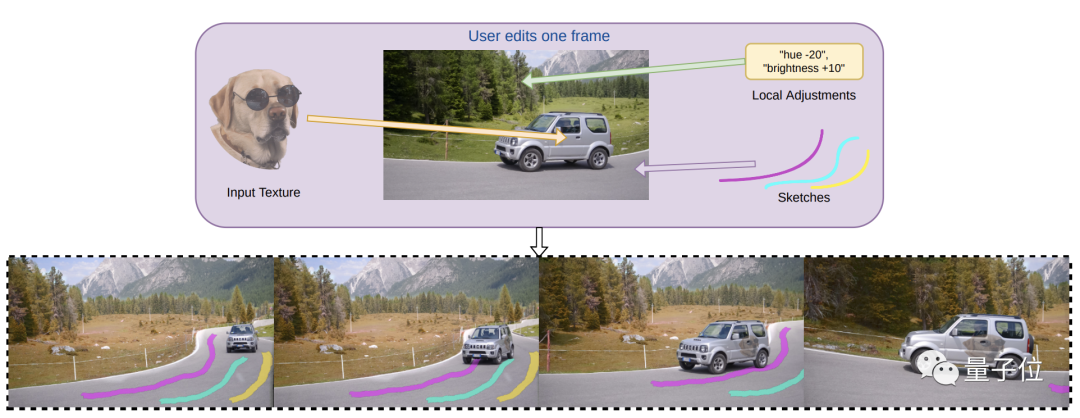
假如我們要把這個(gè)小狗頭像放在車門上,按照傳統(tǒng)方式,視頻中車是往前移動(dòng)的,為避免不出現(xiàn)溢出效果,就需要一幀一幀訓(xùn)練和測(cè)試反復(fù)編輯。
這種方式費(fèi)時(shí)費(fèi)力不說,還容易導(dǎo)致明顯的視覺偽影。
而最近發(fā)展起來的分層神經(jīng)圖集(LNA)方法,可以通過一組分層神經(jīng)網(wǎng)絡(luò)2D圖集對(duì)單個(gè)訓(xùn)練和測(cè)試,達(dá)到編輯整個(gè)視頻的效果。
雖避免了逐幀編輯,但也有一些問題,比如處理速度較慢、對(duì)某些編輯用例支持不足。

因此,研究團(tuán)隊(duì)基于LNA方法,通過學(xué)習(xí)圖像圖集和圖像之間的雙向函數(shù)映射,并引入矢量化編輯,使得在圖集和圖像中一致編輯成為可能。
同時(shí),采用多分辨率哈希編碼來改善模型的收斂速度。
如何實(shí)現(xiàn)
研究團(tuán)隊(duì)基于光流提取算法RAFT,在包含70幀且分辨率為768×432的視頻上訓(xùn)練和測(cè)試模型。
首先,團(tuán)隊(duì)在每個(gè)訓(xùn)練批次中隨機(jī)采樣了10,000個(gè)視頻像素,然后設(shè)定了一個(gè)模型參數(shù)值。
通過將GPU優(yōu)化的Fully Fused MLP架構(gòu)引入,僅迭代大約12,000個(gè)次數(shù)就完成訓(xùn)練,相比于LNA的300,000個(gè)迭代次數(shù)要少得多。

測(cè)試顯示該方法在單個(gè)NVIDIA RTX 4090 GPU上的渲染速度為24.81 FPS,對(duì)比LNA的渲染速度5.34 FPS,渲染速度快了近5倍。
經(jīng)過相同數(shù)量的迭代訓(xùn)練,團(tuán)隊(duì)模型的重建、流場(chǎng)損失都比LNA更快地收斂。
此外,為實(shí)現(xiàn)點(diǎn)跟蹤,團(tuán)隊(duì)選擇逆映射的方法,允許添加跟蹤單個(gè)/少數(shù)點(diǎn)的剛性紋理。
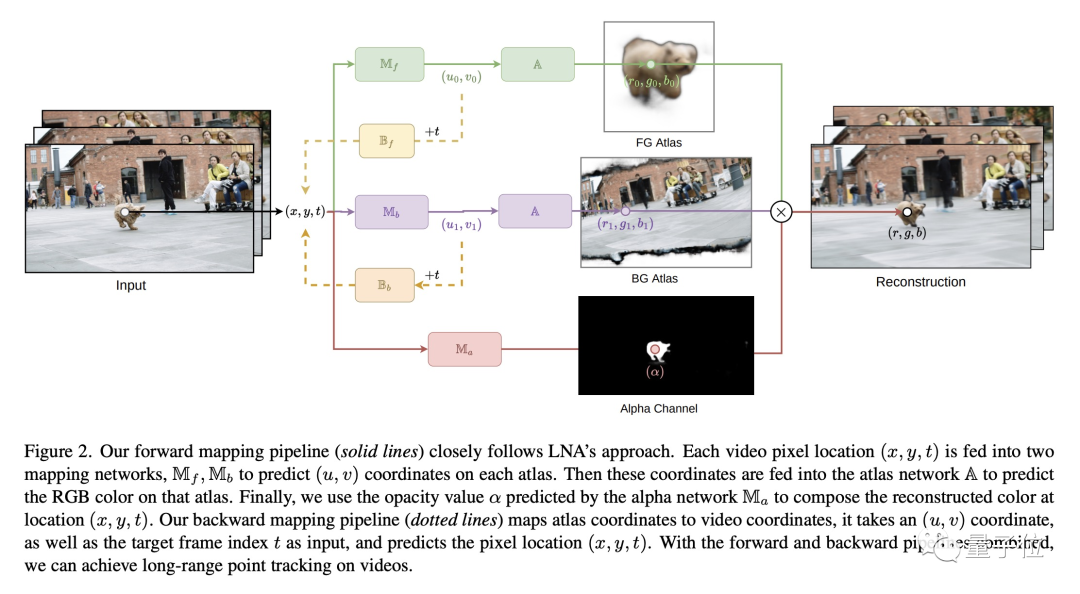
團(tuán)隊(duì)提出“矢量化素描技術(shù)”,將多邊形鏈直接映射到圖集中,更精確地控制線條,從而減少計(jì)算成本并避免有視覺偽影。
再通過分層編輯,允許在圖集之上疊加多個(gè)可編輯圖層,使每個(gè)圖層都可獨(dú)立訪問和編輯。
分層編輯支持多種類型的編輯,包括畫筆涂鴉、局部調(diào)整、紋理編輯。
比如畫筆涂鴉,就可以直接使用畫筆工具草圖涂鴉。

比如紋理編輯,可以導(dǎo)入外部圖形,跟蹤和變形的運(yùn)動(dòng)對(duì)象。

研究團(tuán)隊(duì)
作者團(tuán)隊(duì)由來自Adobe Research、英屬哥倫比亞大學(xué)、AI Vector研究所和CIFAR AI組成。
第一作者是Jiahui Huang,目前是Adobe Research的研究工程師,碩士畢業(yè)于英屬哥倫比亞大學(xué)。

其他作者包括Kwang Moo Yi、Oliver Wang和Joon Young Lee,整個(gè)團(tuán)隊(duì)研究方向主要也是在計(jì)算機(jī)視覺、機(jī)器學(xué)習(xí)和視頻編輯領(lǐng)域。
論文地址已貼,感興趣的可以去看看。
論文傳送門 :
https://arxiv.org/abs/2307.07663
參考鏈接:
[1]https://twitter.com/_akhaliq/status/1681162394393886720/
[2]https://gabriel-huang.github.io/inve/
- 特斯拉CFO突然辭職,未來去向成迷,離任前已拋600萬美元股票2023-08-08
- 韓國(guó)LK-99作者發(fā)布新視頻,樣本室溫25度懸浮,已有網(wǎng)友估算磁化率2023-08-04
- 馬斯克買下ai.com域名!奧特曼剛砸千萬美元購入,4個(gè)月轉(zhuǎn)手給鋼鐵俠2023-08-03
- 谷歌用大模型重寫超級(jí)助手,為推進(jìn)度先裁員重組!2023-08-01



