為Token付費是一件很愚蠢的事情,用戶應該為智能付費丨RockAI劉凡平@MEET2026
“端側(cè)模型不是云端大模型的小參數(shù)版本“
編輯部 整理自 凹非寺
量子位 | 公眾號 QbitAI
“人工智能要發(fā)展到下一個臺階,一定要突破兩座大山。第一座大山是Transformer,第二座大山是反向傳播算法。”
在大模型規(guī)模不斷拔高、算力與數(shù)據(jù)卷到極致的當下,RockAI創(chuàng)始人劉凡平提出了一個與主流共識截然不同的判斷。
下一階段的智能,不在“更大”,而在“活起來”。
本質(zhì)是讓模型擺脫靜態(tài)函數(shù)的桎梏,讓端側(cè)設(shè)備具備原生記憶、自主學習與持續(xù)進化的能力。
這意味著AI的方向要從云端集中式的算力競爭,遷移到每一臺設(shè)備,每一個個體都能參與學習,生成知識的全新范式。
在量子位MEET2026智能未來大會上,劉凡平將這一轉(zhuǎn)折點稱為硬件覺醒:
當模型在端側(cè)能像大腦一樣稀疏激活、實時形成記憶,并在物理世界中不斷更新自身,設(shè)備就不再是工具,而是“活”的智能體。
而無數(shù)這樣的智能體在現(xiàn)實世界中學習、協(xié)作,便將孕育出真正能夠產(chǎn)生知識的群體智能。

這既是對Transformer與反向傳播算法這“兩座大山”的正面突破,也是邁向通用人工智能的一條新路徑。
為了準確呈現(xiàn)劉凡平的完整思考,以下內(nèi)容基于演講實錄進行整理編輯,希望能提供新的視角與洞察。
MEET2026智能未來大會是由量子位主辦的行業(yè)峰會,近30位產(chǎn)業(yè)代表與會討論。線下參會觀眾近1500人,線上直播觀眾350萬+,獲得了主流媒體的廣泛關(guān)注與報道。
核心觀點梳理
- 為Token付費是一件很愚蠢的事情,用戶應該為智能付費。
- 端側(cè)模型不是云端大模型的小參數(shù)版本,端側(cè)模型關(guān)鍵在于自主學習和原生記憶,Transformer架構(gòu)模型無法在端側(cè)實現(xiàn)這一點。
- 人工智能要發(fā)展到下一個臺階,一定要突破兩座大山。第一座大山是Transformer,第二座大山是反向傳播算法。
- 原生記憶和自主學習帶來的變化除了Token不再收費,更多的還有重新定義硬件的價值。
- 每臺設(shè)備擁有自己的智能并能向物理世界學習,就會產(chǎn)生群體智能,如同人類社會個體相互合作產(chǎn)生知識。現(xiàn)有大模型(尤其是Transformer架構(gòu)大模型)本身不產(chǎn)生知識,只是傳播知識;群體智能才是邁向通用人工智能的最佳途徑。
- ……
以下為劉凡平演講全文:
硬件可能覺醒嗎?
很高興能夠和大家在今天分享RockAI在模型層面的思考,也許今天講的內(nèi)容和大家平常理解的有些不一樣——我們認為通用人工智能一定有自己的發(fā)展路徑。
今天分享的主題是硬件覺醒。
我們知道硬件是沒有生命的,怎么可能覺醒?沒錯,我們做大模型應該重新思考這一切的東西,這一切就是因為被Transformer束縛了。
我想問一下大家,你期待的未來的智能硬件是什么樣子?是你的智能手機還是平板,還是前兩天的豆包手機?
今天很多大會嘉賓都提到了Agent,提Agent的時候都提到一個點:工具,更高效的工具。
當前很多人還是把大模型當工具用。就像計算器一樣,我需要的時候拿過來用一下,不需要的時候就放開了。
從智能發(fā)展角度來想想:豆包手機能按照指令打開APP做相應的事情,下一步會發(fā)生什么?它能打開微信發(fā)信息,那微信未來的樣態(tài)還是現(xiàn)在這樣嗎?它能打開高德地圖,高德地圖十年以后還是現(xiàn)在這樣嗎?
大家會發(fā)現(xiàn),目前是一個中間狀態(tài),并不是終極狀態(tài)。
為Token付費是一件很愚蠢的事情
剛剛很多嘉賓提到,Token消耗量增長了10倍,尤其是使用上Agent之后。
這本質(zhì)是在為Token付費。
但大家有沒有想過:為Token付費是一件很愚蠢的事情。
我們?yōu)槭裁醋龃竽P停渴且驗橹悄堋H绻顿M,應該是為智能付費,為什么為Token付費?
打個比方,有的人講話只要簡單幾句就能說清楚,有的人說話很啰嗦,我難道要為它的啰嗦付費嗎?肯定是不對的。
細想一下,就會發(fā)現(xiàn)為Token付費是一個錯誤。未來(兩年之后)回頭看,我相信大家一定也會疑惑當年居然還為Token付過費、充值過。
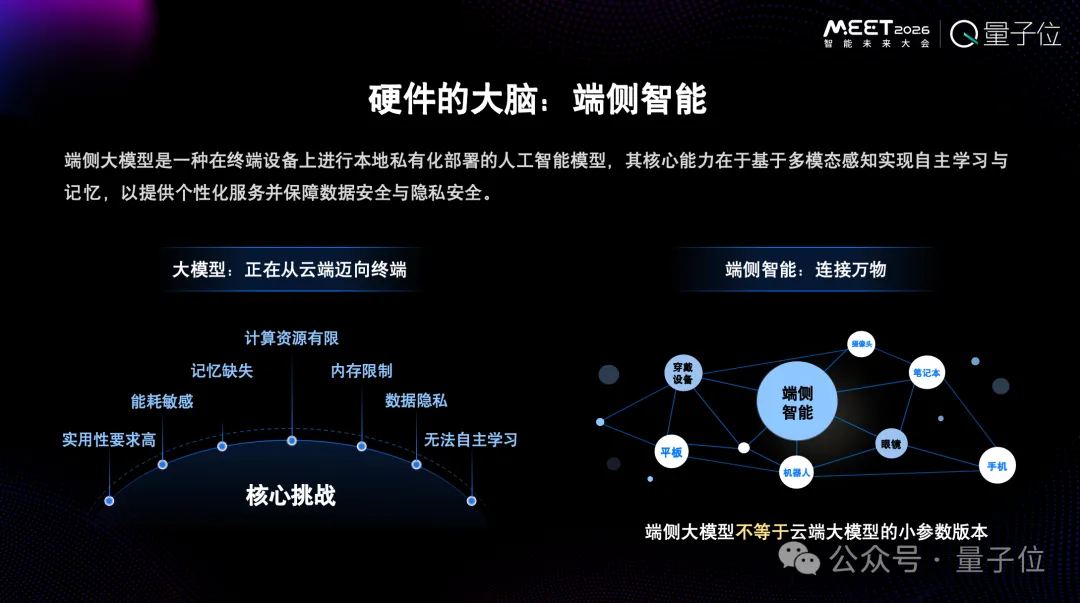
端側(cè)模型并不是云端大模型的小參數(shù)版本
硬件已經(jīng)發(fā)生了很多變化,當前的云端大模型已經(jīng)慢慢走向了終端設(shè)備。
為什么這么說?我們不否定云端大模型的好處,尤其在工具使用上,云端大模型非常優(yōu)秀。
但是未來AI是屬于每一個人的。要讓AI走向每一個人的世界,最重要的是端側(cè)的智能。
一方面因為端側(cè)離你更近,而且端側(cè)還有一個“數(shù)據(jù)無處不在”的好處。
我一直以來比較反感把所有數(shù)據(jù)采集到云端,云端訓練好了再下發(fā)給用戶使用。
數(shù)據(jù)明明就在你的身邊,為什么做不到就讓它在你身邊?因為云端大模型參數(shù)量太大了,也沒有這么多設(shè)備收集你身邊的數(shù)據(jù)。
端側(cè)大模型如果能在設(shè)備上收集數(shù)據(jù),而且是完全屬于你個人的數(shù)據(jù),且這臺設(shè)備又能和你其他設(shè)備關(guān)聯(lián),那個時候大家就不會單純把模型當做一個工具來使用了。
很多人覺得端側(cè)受限于設(shè)備,算力有限,所以在云端做幾十B的“大”模型,端側(cè)做幾B的“小”模型,就成了端側(cè)模型。
但端側(cè)模型并不是云端大模型的小參數(shù)版本。
RockAI對端側(cè)大模型有兩個非常關(guān)鍵的定義:自主學習和原生記憶。這是我們認為最重要的事情。
如果是Transformer架構(gòu)的模型,無法在端側(cè)實現(xiàn)自主學習與原生記憶。
跳出Transformer架構(gòu)去看問題
Transformer很優(yōu)秀。
我自己就是國內(nèi)最早研究Transformer的人之一,對它早期的成功非常認可。
但它現(xiàn)在進入到一個死亡螺旋的狀態(tài),帶來一個問題——為了讓模型能力足夠突出我們要加大算力、加大數(shù)據(jù),帶來成本極大提升。大家和競爭對手都在做同樣的事情。
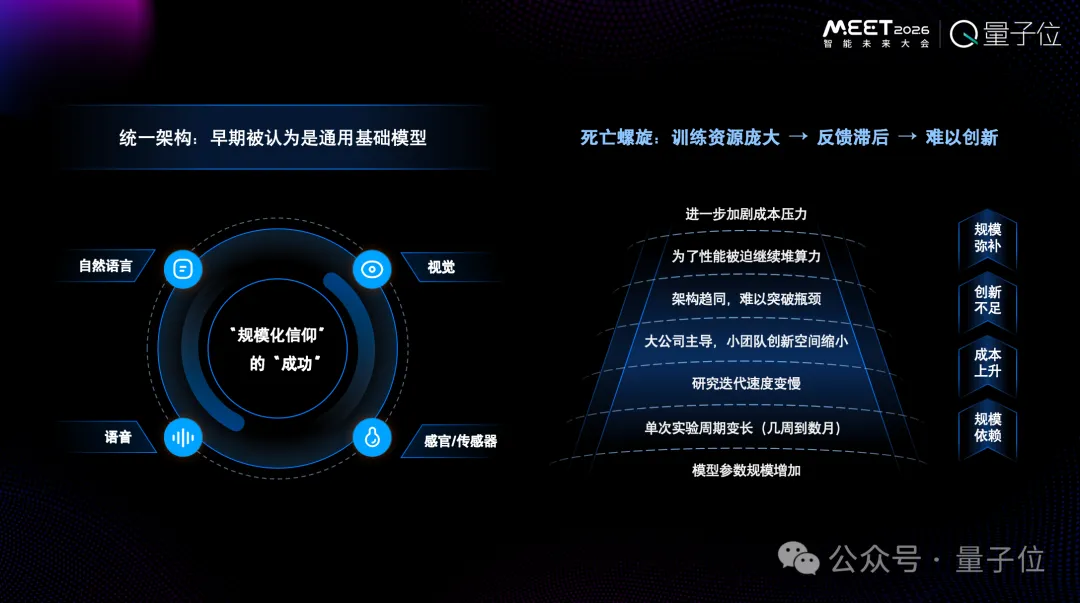
你會發(fā)現(xiàn),大家都沒有管架構(gòu),大家都在干數(shù)據(jù)和算力。因為“只要我數(shù)據(jù)算力夠了,我就做得更好”。
我們認為,信仰Scaling Law的成功在現(xiàn)在看來是錯誤的。不僅我這樣說,現(xiàn)在很多人也有類似的觀點。
核心本質(zhì)不在于模型不夠大,而在于思考的方式錯了。
模型本身是一個靜態(tài)函數(shù),這種靜態(tài)函數(shù)是不太可能會具備真正的智能。因為人的大腦是一個動態(tài)函數(shù),每時每刻都在建立新的連接,而新的連接是動態(tài)結(jié)構(gòu)的。人的大腦是因為這樣才有了記憶的能力。

另一個誤區(qū)是“更多參數(shù)就意味著更多智能”。
在Transformer架構(gòu)下這樣想沒錯,但如果跳出Transformer架構(gòu)就不是這樣了。
舉一個簡單的例子——
生物界,一條蛇或者一個小兔子它沒有智能嗎?應該沒有人否定它們的智能。
和人腦相比,它們大腦擁有的“參數(shù)”肯定少很多。
另外還有長上下文。
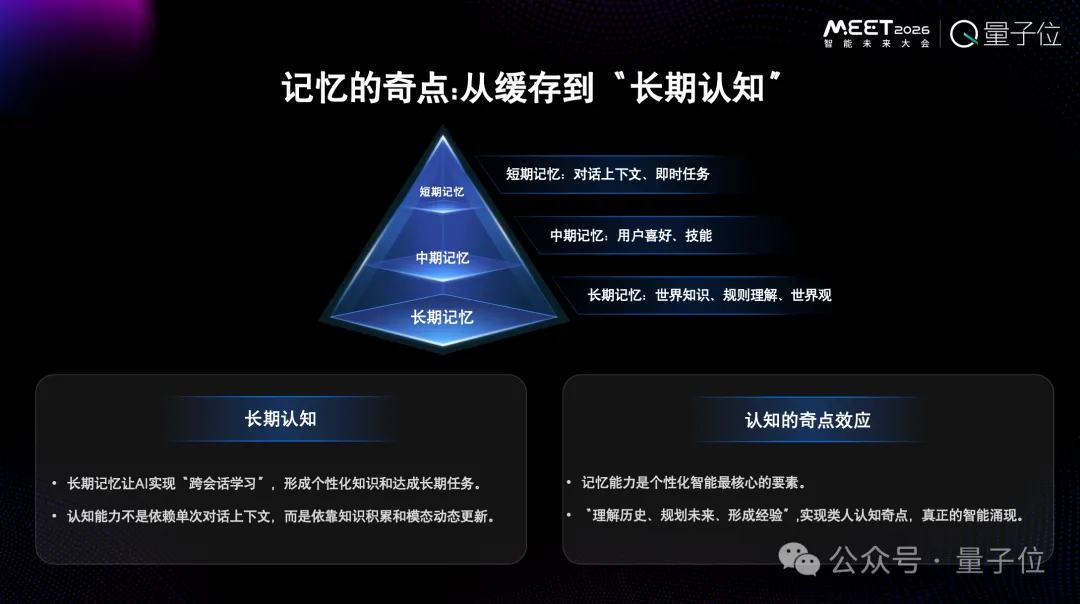
2024年,長上下文方面有很多突破。但我們一直不認為長上下文是一種記憶,真正的記憶應該像人大腦的海馬體一樣,會把所有信息通過加工處理壓縮存儲下來,根據(jù)需要的情況會移除掉一部分信息。
這種記憶是參數(shù)化的記憶,不是靠上下文完成的。靠上下文完成,記憶就會很短。
為什么現(xiàn)在大家又執(zhí)著于做上下文?是因為Agent,而Agent背后的Transformer架構(gòu)模型部署后是一個靜態(tài)函數(shù),沒辦法,只能通過上下文改變它的能力。
講到這里大家就會恍然大悟,長上下文其實是一個退而求其次的方案,并不是真正智能的解決方案。
上下文窗口超過100萬Tokens也好,200萬Tokens也好,1000萬Tokens也好……但每時每刻產(chǎn)生的Token遠遠超過了這個量。就拿今天大會大家分享的內(nèi)容來說,就已經(jīng)遠遠超過了1萬Tokens。
記憶能讓人形成長期認知,是一個過程。我們的價值觀就是記憶逐步積累起來的。如果記憶只靠長上下文,那么就形成不了價值觀,更不會有知識沉淀。
人的聰明來自長時間的積累。
訓推同步,帶來自主進化
回到剛才說的,未來的智能硬件最重要的應該是原生記憶和自主學習。
剛才說了原生記憶,現(xiàn)在來說自主學習,自主學習是一定要走向物理世界的。
自主學習帶來的一大好處就是模型不會因為部署就“死亡”了。
可能大家不知道,因為參數(shù)已經(jīng)固定,所以模型在部署的那一刻就死掉了。想要改變,就只能上傳到云端服務(wù)器重新訓練,過一段時間再下發(fā)給大家使用。
一旦能夠自主學習,隨之而來的自主進化就會帶來全新的改變。我們就不再認為它是一個固定的工具,而是可以持續(xù)學習的。
我們把這種持續(xù)學習狀態(tài)的技術(shù)稱之為訓練和推理同步進行。
訓練和推理同步進行,就像我站在這里輸出一些內(nèi)容(可以看成大模型的推理過程)的時候,也在獲得一些新的東西。我的推理和訓練是同時完成的。大腦不僅在推理,參數(shù)也在不斷改變,這就是“活”的東西。
今天發(fā)布了一個模型,過三個月再去問這三個月里發(fā)生的事情,它是不知道的,需要通過知識外掛RAG等方式彌補。這不是臨時方案是什么?
我們作為研究者,應該要面臨這樣的現(xiàn)實——
大模型的很多方案都是臨時方案,并不是真正的終局方案,終局方案就是要改架構(gòu)。
我自己的觀點是這樣的:人工智能要往下發(fā)展到更高的臺階,一定要突破兩個大山,第一座大山是Transformer,第二座大山是反向傳播算法(反向傳播算法制約了現(xiàn)在很多設(shè)備的發(fā)展,包括算力的發(fā)展)。
模型架構(gòu)一定要改
為了讓模型不再死亡、能夠進化,模型架構(gòu)一定要改變。
以我們自己研發(fā)的Yan架構(gòu)的大模型為例,整個模型極端稀疏化,激活機制比MoE更稀疏。
它模仿了人類大腦的運行機制。人的大腦大概有860億參數(shù),但二十幾瓦的大腦預算峰值就可以推動大腦運算。
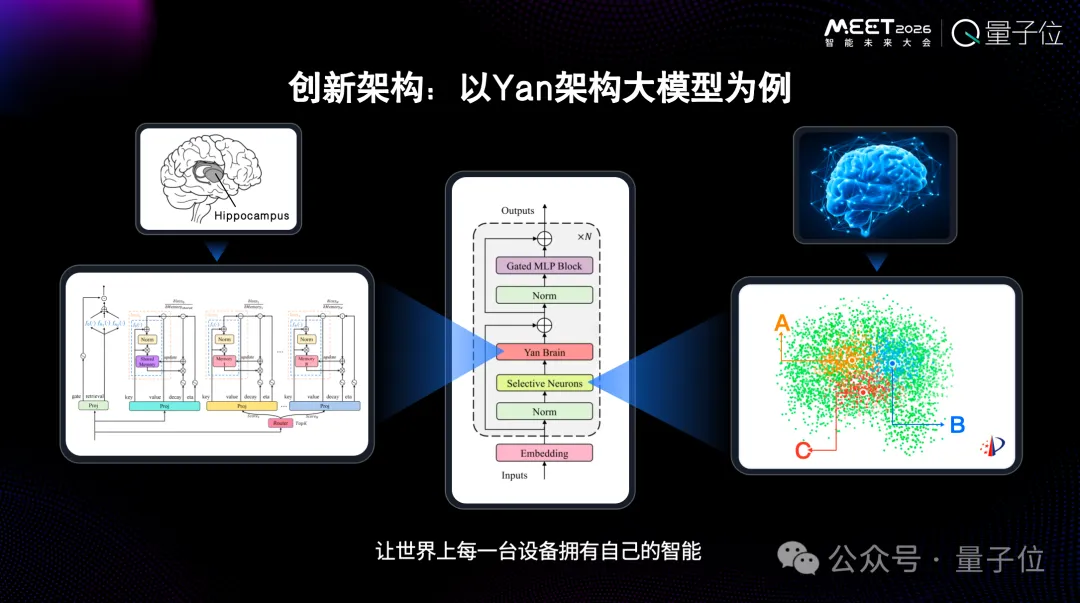
另外,我們在模型中加入了記憶模塊。也就是說,推理過程中,隨著你跟它溝通,記憶模塊會發(fā)生改變。所以真正的記憶開始了,真正個性化開始了。
如果一個設(shè)備擁有了自主學習,就有了新的可能性。
今年世界人工智能大會我們發(fā)布的一個部署了模型的小設(shè)備,是一個機器狗,最開始什么能力都沒有,但是可以現(xiàn)學現(xiàn)會。我們模型不一定需要云端GPU,手機、CPU上都能直接跑。

這還僅僅是一個簡單的機器狗。如果范圍更大一點,到具身智能呢?
具身智能現(xiàn)在沒辦法進入千家萬戶,核心原因是沒法在出廠的時候適應每個家庭,服務(wù)好每個家庭。它需要學習。
一個人到了酒店,還得看一下酒店的布局,知道書房在哪里,洗漱間在哪里。
未來設(shè)備也是一樣,它需要專門了解,有一個學習的過程,而不是出廠的時候就會用所用家電了。這個學習的過程是Transformer架構(gòu)現(xiàn)在很難具備的。
智能會重新定義硬件的價值
原生記憶和自主學習帶來的變化不僅僅是Token不再收費了,更多的還有智能重新定義硬件的價值。
舉個例子。比如說花兩萬塊錢買了一只寵物狗,它陪伴了你兩年,你跟它產(chǎn)生了情感依賴。兩年之后你還會花兩萬塊錢把它賣掉嗎?我想那個時候你肯定不是思考兩萬塊錢的事情,而是更在意狗和你之間產(chǎn)生了多深的情感。
未來的硬件其實需要讓用戶與它共同創(chuàng)造價值,而不是為它的功能買單。
就像買一部手機,未來為它付費的不是內(nèi)存,是與它的價值共創(chuàng)。你買它的時候它的價值是最小的時候。
所以我們認為智能會重新定義硬件的價值,它就不再只是一個工具了。
我們的模型能夠在手機、具身智能等設(shè)備上靈活運行。比如在手機上部署的3B的離線模型,保證了用戶的隱私和安全,體驗還非常流暢。
特別強調(diào)的是,在離線情況下,多模態(tài)感知能具備記憶和自主學習能力,那么硬件價值一定會發(fā)生很大變化。這也是全新架構(gòu)帶來的全新可能。
Transformer幾乎不可能做到這個水平。因為手機上運行它會消耗很高的內(nèi)存資源。
每臺設(shè)備擁有自己的能力并能向物理世界學習,就會產(chǎn)生群體智能
當硬件擁有了原生記憶和自主學習,還會發(fā)生什么樣的變化?
不同于OpenAI,也不同于DeepSeek,我們認為這條路徑是群體智能。
每一臺設(shè)備都擁有了自己的智能,此外還能向物理世界進行學習的時候,就會產(chǎn)生群體智能。
群體智能有點像人類社會。每個人都不是全能的,我們不需要造一個全能的人,更不需要人人都全能。大家只需要有自己擅長的點就可以了。
更多智能來自于相互之間的合作,合作過程中會產(chǎn)生真正的知識。

知識有兩部分:一個叫產(chǎn)生,一個叫傳播。
現(xiàn)在大模型——尤其是Transformer架構(gòu)大模型——有很大的一個問題,它本身沒有產(chǎn)生知識。
真正的智能應該是產(chǎn)生知識。人與人之間隨時在產(chǎn)生知識,正是因為每個人的不同產(chǎn)生了不同的解決方案。
真正的智能涌現(xiàn)來自于每個個體,每個個體產(chǎn)生信息之后,再傳播給更多的人。我們是在這樣的過程中形成了人類逐步發(fā)展的文明,而不是靠一個足夠聰明的云端通用大模型來造神。
云端通用大模型的厲害之處無非在于收集的數(shù)據(jù),而收集的數(shù)據(jù)無非來自于人類社會的經(jīng)驗。如果它連自己原生的記憶和自主學習都不具備,是不可能產(chǎn)生真正的智能。
RockAI一直認為群體智能才是邁向通用人工智能最佳的方式,而不是OpenAI造神的路徑。
我的分享就到這里,謝謝!
- 太初元碁喬梁:AI算法已經(jīng)跑到單芯片極限|MEET20262025-12-14
- MEET2026擠爆了,AI圈今年最該聽的20+場演講&對談都在這2025-12-11
- 交大高金朱寧:經(jīng)濟學家視角下AI時代的范式思維轉(zhuǎn)變 | MEET20262025-12-13
- 起底“豆包手機”:核心技術(shù)探索早已開源,GUI Agent布局近兩年,“全球首款真正的AI手機”2025-12-09
相關(guān)閱讀