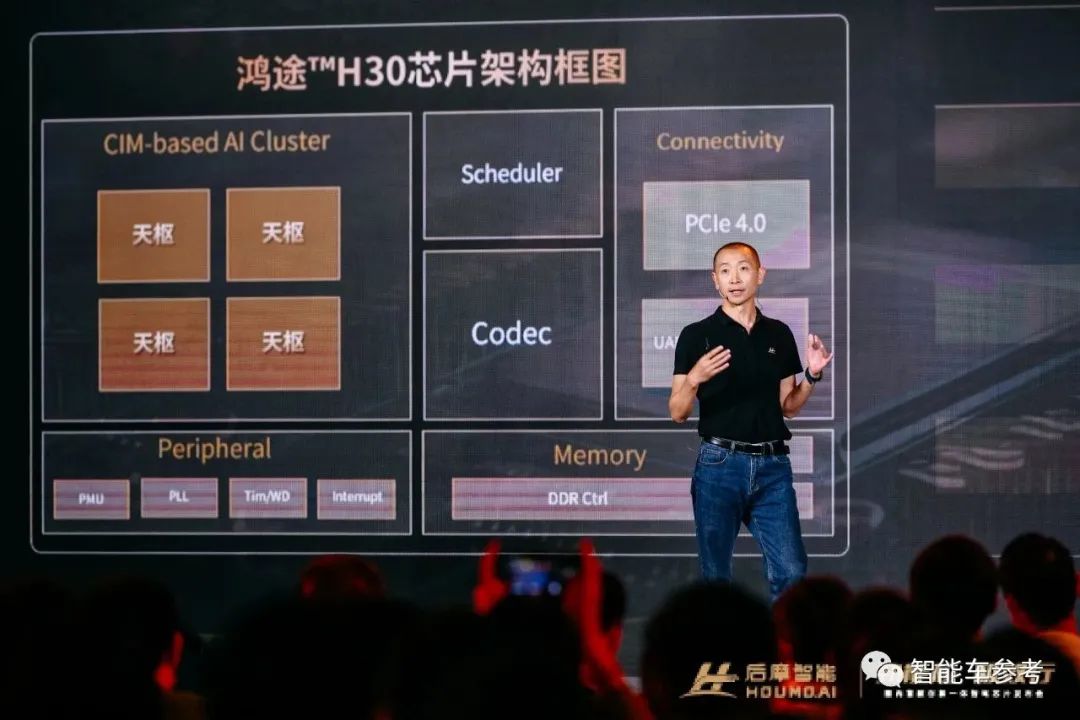
最高能效比!他又死磕“存算一體”2年,拿出全新端邊大模型AI芯片
后摩智能發布M50 AI芯片
金磊 發自 WAIC
量子位 | 公眾號 QbitAI
當他再次高調出現在大眾面前,已經是時隔兩年之久。
他就是后摩智能CEO吳強博士,很多人好奇他和他的團隊在這兩年時間里都在做什么。
而就在今年WAIC期間,吳強終于給出了答案——
發布潛心兩年的成果:后摩漫界?M50,一款業界能效比最高的存算一體端邊大模型AI芯片。

△后摩智能CEO吳強發布后摩漫界?M50
M50擁有160TOPS@INT8的物理算力,100TFLOPS@bFP16的浮點算力,以及高達153.6 GB/s的超高帶寬和最大48GB的內存。
更令人側目的是,實現這一切的典型功耗,僅僅10W——相當于一個手機快充的功率。
用吳強的話來說就是:
我們希望讓大模型算力像電力一樣隨處可得、隨取隨用,真正走進每一條產線、每一臺設備、每一個人的指尖。

兩年前,后摩智能帶著第一代存算一體芯片驚艷亮相WAIC。
兩年后,面對大模型時代帶來的全新機遇與挑戰,他們依舊穩健,選擇繼續死磕存算一體這條當時看來頗為“冷門”的賽道,并再次拿出了業界第一的成績。
把存算一體推入了第二代
M50之所以能實現如此驚艷的能效比,其背后實則是后摩智能在存算一體技術上的持續深耕和迭代突破。
因為它所搭載的,正是后摩智能自研的第二代存算一體技術。

要理解這一的技術,我們首先要明白什么是“存算一體”。
在傳統的計算機架構(馮·諾依曼架構)中,計算單元和存儲單元是分離的。CPU或GPU要計算數據,需要先從內存中把數據“搬運”過來,計算完成后再“搬運”回去。
這個“搬運”過程,就像快遞運輸,不僅耗費時間(帶寬限制),還消耗大量能量(功耗),形成了所謂的“功耗墻”和“存儲墻”,成為制約芯片性能提升的最大瓶頸。
而存算一體,顧名思義,就是將計算和存儲融合在一起,讓數據在存儲單元內部就近完成計算,從根本上解決了數據來回搬運的問題。這好比將工廠直接建在了倉庫里,省去了所有的物流環節,效率自然大大提升。
吳強在創業之初就敏銳地意識到,要想在英偉達這樣的國際巨頭環伺下實現“彎道超車”,就必須在架構上進行創新。存算一體,便是他認定的那條另辟蹊徑的道路。
M50采用的第二代SRAM-CIM(基于SRAM的存內計算)技術,是真正的“存內計算”。
吳強解釋道:
很多朋友問存內和近存有什么區別?如果把SRAM的陣列或者結構改變,它就是存內。如果不改變,它只是拿標準的SRAM,在旁邊做計算,那就是近存。
后摩智能選擇的是更徹底、更具挑戰性的前者——他們把SRAM的陣列全部打開,進行了深度的結構性改變。
這一代的存算IP實現了“雙端口加載與計算并行”,權重加載和矩陣計算可以同時進行,效率倍增。
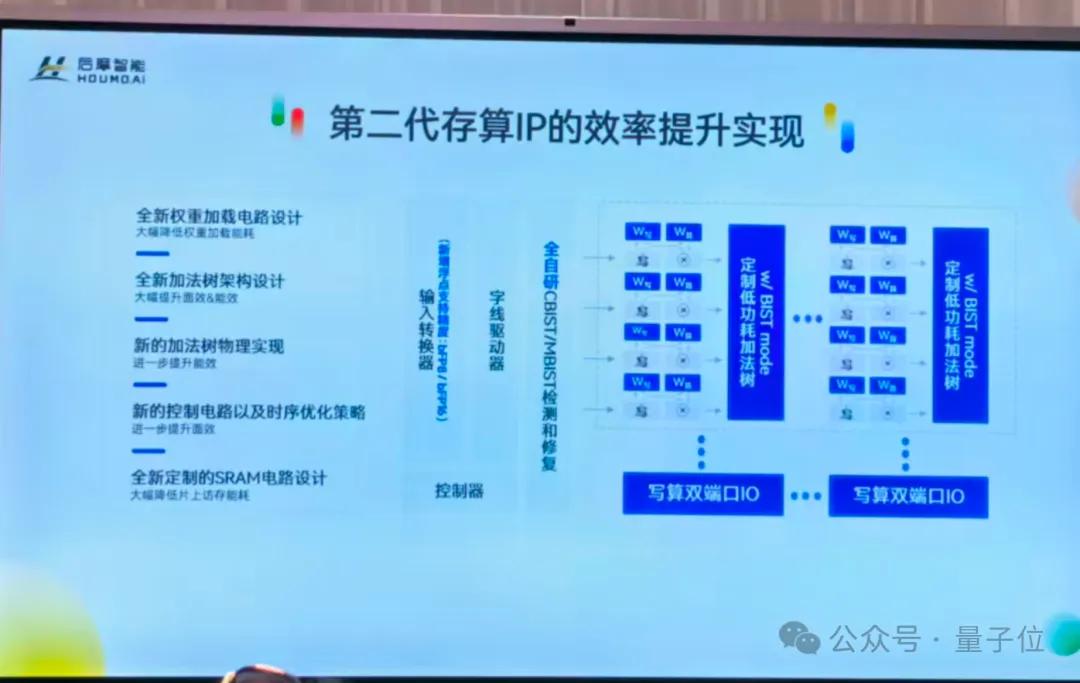
同時,為了解決量產難題,后摩智能團隊自主摸索出了一套針對存算芯片的測試和可靠性保障方案(MBIST和CBIST),趟出了一條業內無人走過的路。
有了高效的存算IP,還需要一個聰明的“大腦”來調度和使用它。后摩智能為此自研了全新的第二代IPU(AI處理器)架構——天璇。
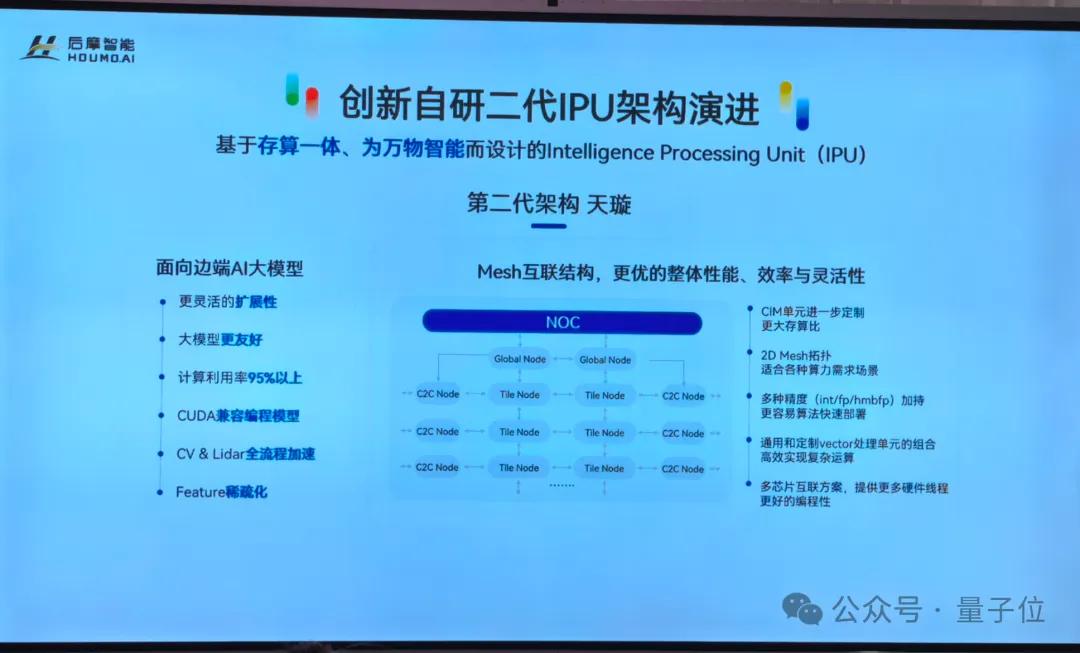
天璇架構針對大模型的計算特點,做了大量優化,其中最核心的創新之一,就是彈性計算(Elastic Computing),或者叫自適應計算。
這有點類似于GPU的稀疏加速技術。
在GPU中,如果權重參數為“0”,計算時就可以跳過,從而實現加速。但這種技術的限制是,權重必須嚴格為“0”。而在現實應用中,要讓大量權重都恰好為“0”是非常困難的,因此GPU的稀疏加速效果往往不盡如人意。
而存算一體的特性,給了后摩智能一個絕佳的機會。他們的SRAM存算,是按照一個比特(bit)一個比特進行串行計算的。這意味著,他們可以做到更細粒度的優化。
吳強對此解釋道:
我們并不需要它(權重)整個是0,我只要它在bit里面有0,我就可能做彈性加速,我就可能授予這個0跳過去0的加速。
這個看似微小的區別,帶來了本質的不同。
它讓加速的機會大大增加,也讓量化變得更加靈活,可以實現7bit、6bit甚至5bit的超低精度量化,從而在不犧牲太多精度的情況下,將性能壓榨到極致。根據后摩的數據,天璇架構最高可提供160%的加速效果。
此外,天璇架構還在業內首次實現了在存算架構上直接進行浮點運算,并成功量產。這意味著,開發者可以直接運行開源的FP16浮點模型,無需復雜的量化和精度調優,大大降低了應用落地的門檻和開發周期。

再強大的硬件,也需要軟件來釋放其全部潛能。與M50配套的,是后摩智能新一代編譯器工具鏈——后摩大道?。
這款完全重構的編譯器,最大的特點是靈活易用。它支持細顆粒度的算子,能將復雜的算子自動拆分、組合和優化。
開發者不再需要面對幾百個優化選項手動“煉丹”,編譯器可以自動搜索最優化的策略,大大減輕了適配和部署的負擔。

從底層的存算IP,到上層的IPU架構,再到頂層的編譯器工具鏈,后摩智能通過全棧自研,將軟硬件深度協同優化,最終打磨出了M50這把刺穿端邊大模型計算“最后一公里”的利刃。
衍生出了更多存算一體產品
這顆業界能效比最高的芯片還只是故事的開始。
為了讓M50的算力能夠以最便捷的方式觸達不同場景,后摩智能同步推出了一系列硬件產品,構建了覆蓋終端與邊緣的完整產品矩陣。
終端側:力擎TM系列M.2卡
在終端側,首先是力擎TMLQ50 M.2卡。
這款產品的大小僅如同一塊口香糖,采用標準的M.2接口,可以“即插即用”地為AI PC、AI Stick、陪伴機器人等移動終端提供強大的本地AI能力。
單卡即可支持7B/8B模型推理速度超過25 tokens/s。吳強特別提到,低功耗帶來的一個巨大優勢是可以使用被動散熱,無需風扇,這對于智能語音設備等對噪音敏感的場景至關重要。

其次是力擎TMLQ50 Duo M.2卡。
在標準M.2卡的基礎上,它集成了兩顆M50芯片,算力、帶寬、內存全部翻倍,達到320TOPS算力,突破了14B/32B大模型在端側部署的瓶頸。
值得一提的是,這兩顆芯片并非簡單的堆砌,而是通過后摩自研的C-to-C互聯技術協同工作,實現1+1>2的效果。

邊緣側:力謀?系列加速卡及計算盒子
在邊緣側,后摩智能同樣發布了一些利產品。
首先是力謀?LM5050/LM5070加速卡。
面向對體積不那么敏感,但對算力有更高要求的邊緣計算場景,后摩推出了半高半長和全高全長的加速卡,分別集成2顆和4顆M50芯片,最高可提供640TOPS的物理算力。
這樣的算力足以在邊緣端支持70B甚至千億參數級別的大模型。而功耗,相比友商同等算力產品動輒幾百瓦的“電老虎”,后摩的加速卡僅為幾十瓦,能效優勢極為突出。

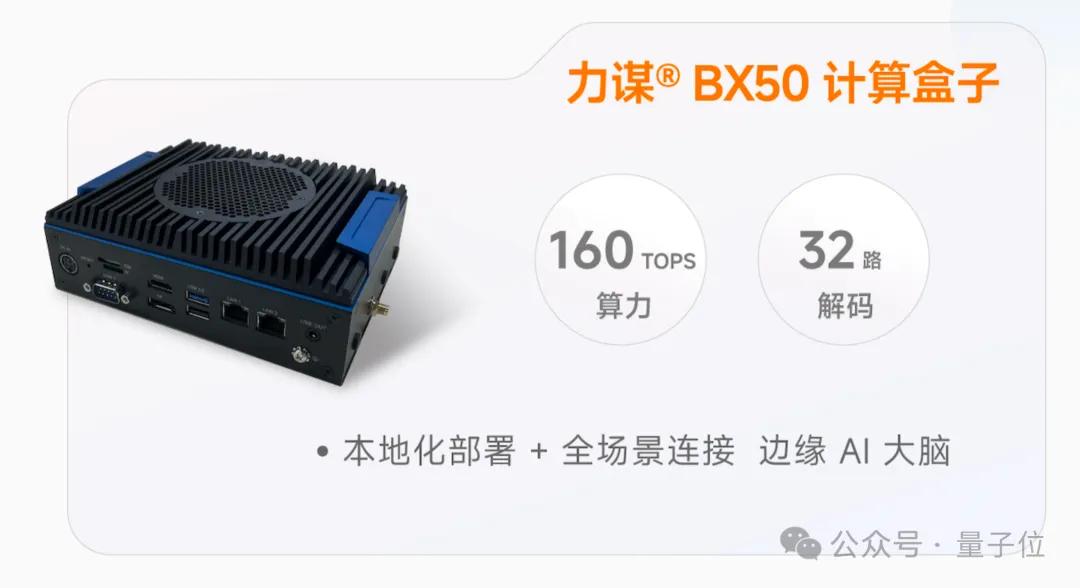
其次是力謀?BX50智能計算盒。
這是一款All-in-One的解決方案,在一個緊湊的機身內,集成了強大的M50芯片、豐富的I/O接口,并支持加密安全功能,可適配邊緣場景,支持多達32路視頻分析與本地大模型的同時運行。
從消費終端的AI PC、學習機,到智能辦公的會議系統,再到智能工業的產線質檢,后摩智能的產品矩陣,讓離線、安全、低延遲的本地大模型應用成為可能,真正構建起一個“低功耗、高安全、好體驗”的端邊智能新生態。
為什么要死磕存算一體?
首先,這是差異化競爭的必然選擇。
面對英偉達、華為這樣“大而全”的巨頭,初創公司如果跟在后面亦步亦趨,很難有出頭之日。
正如吳強所述:
如果跟國際巨頭競爭,需要一些比較創新的架構才有可能另辟蹊徑彎道超車。
存算一體,就是他找到的那個“蹊徑”。
其次,這是技術發展的必然趨勢。
大模型時代,應用對算力和帶寬的需求是空前的,而傳統架構的瓶頸日益凸顯。
吳強和他的團隊發現,大模型應用“既要算力密集,又要帶寬密集”的特點,與存算一體技術“既能提升算力密度,又能提升帶寬”的優勢完美契合。
“我們發現這個之后就很興奮,”吳強說,“我們決定聚焦在端邊大模型AI計算,讓存算和大模型形成共振,釋放更大的勢能。”
最終,這也是實現普惠AI的必經之路。
吳強認為,未來90%的數據處理都將在端和邊完成,只有10%的訓練和復雜任務在云端進行。要讓大模型真正走出云端,賦能千行百業,就必須解決端邊設備算力不足、功耗過高的問題。
這份專注與堅持,也為后摩智能贏得了產業和資本的認可。近年來,公司陸續獲得了中國移動、北京人工智能基金、亦莊國投等重量級產業方和國有資本的投資,為持續的研發創新提供了堅實的后盾。
從兩年前的嶄露頭角,到如今的厚積薄發,吳強和他的后摩智能,正以一種近乎“執拗”的堅持,在存算一體這條道路上篤定前行。
M50的發布,只是他們交出的階段性答卷。未來,當更強大的AI算力以更低的功耗融入我們身邊的每一個設備時,我們或許會再次想起這位熱愛足球、堅持跑步的技術人,以及他那個“讓智能無處不在”的初心。
Two More Thing:
發布會的最后,吳強還透露了兩個有趣的小細節。
一是M50的命名,之所以跳過了M40,這也算是創業公司的生存玄學了,畢竟在芯片行業——跳過“4”,可能就跳過了“生死劫”。
二是他向大家承諾:“下次不用等2年了,明年還會有新品。”
據了解,后摩智能已經啟動了下一代DRAM-PIM(基于DRAM的存內處理)技術的研發。
這個技術將突破1TB/s的片內帶寬,能效再提升三倍,旨在推動百億參數大模型在PC、平板等終端設備上的普及。
- 商湯Seko上線一個月,超10萬創作者選擇它2025-09-29
- 戴爾 x OpenCSG,推出?向智能初創企業的?體化 IT 基礎架構解決方案2025-12-10
- 看完最新國產AI寫的公眾號文章,我慌了!2025-12-08
- 共推空天領域智能化升級!趨境科技與金航數碼強強聯手2025-12-09