
LeCun世界模型出2代了!62小時搞定機(jī)器人訓(xùn)練,開啟物理推理新時代
聞樂 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
物理學(xué)正在走向人工智能——
Meta開源發(fā)布V-JEPA 2世界模型:一個能像人類一樣理解物理世界的AI模型。

圖靈獎得主、Meta首席AI科學(xué)家Yann LeCun親自出鏡宣傳,并稱:
我們相信世界模型將為機(jī)器人技術(shù)帶來一個新時代,使現(xiàn)實(shí)世界中的AI智能體能夠在不需要大量機(jī)器人訓(xùn)練數(shù)據(jù)的情況下幫助完成家務(wù)和體力任務(wù)。

那什么是世界模型呢?
簡單說,就是能夠?qū)φ鎸?shí)物理世界做出反應(yīng)的AI模型。
它應(yīng)該具備以下幾種能力:
- 理解:世界模型應(yīng)該能夠理解世界的觀察,包括識別視頻中物體、動作和運(yùn)動等事物。
- 預(yù)測:一個世界模型應(yīng)該能夠預(yù)測世界將如何演變,以及如果智能體采取行動,世界將如何變化。
- 規(guī)劃:基于預(yù)測能力,世界模型應(yīng)能用于規(guī)劃實(shí)現(xiàn)給定目標(biāo)的行動序列。
V-JEPA 2(Meta Video Joint Embedding Predictive Architecture 2 )是首個基于視頻訓(xùn)練的世界模型(視頻是關(guān)于世界信息豐富且易于獲取的來源)。
它提升了動作預(yù)測和物理世界建模能力,能夠用于在新環(huán)境中進(jìn)行零樣本規(guī)劃和機(jī)器人控制。

V-JEPA 2一發(fā)布就引起了一片好評,甚至有網(wǎng)友表示:這是機(jī)器人領(lǐng)域的革命性突破!


62小時訓(xùn)練即可生成規(guī)劃控制模型
V-JEPA 2采用自監(jiān)督學(xué)習(xí)框架,利用超過100萬小時的互聯(lián)網(wǎng)視頻和圖像數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,不依賴語言監(jiān)督,證明純視覺自監(jiān)督學(xué)習(xí)可以達(dá)到頂尖表現(xiàn)。

上圖清晰地展示了如何從大規(guī)模視頻數(shù)據(jù)預(yù)訓(xùn)練到多樣化下游任務(wù)的全過程:
輸入數(shù)據(jù):利用100萬小時互聯(lián)網(wǎng)視頻和100萬圖片進(jìn)行預(yù)訓(xùn)練。
訓(xùn)練過程:使用視覺掩碼去噪目標(biāo)進(jìn)行視頻預(yù)訓(xùn)練。
下游應(yīng)用分為三類:
- 理解與預(yù)測:行為分類、物體識別、行為預(yù)測;
- 語言對齊:通過與LLM對齊實(shí)現(xiàn)視頻問答能力;
- 規(guī)劃:通過后訓(xùn)練行動條件模型(V-JEPA 2-AC)實(shí)現(xiàn)機(jī)器人操作。
V-JEPA 2采用聯(lián)合嵌入預(yù)測架構(gòu)(JEPA),主要包含兩個組件:編碼器和預(yù)測器。
編碼器接收原始視頻并輸出能夠捕捉有關(guān)觀察世界狀態(tài)的語義信息的嵌入。
預(yù)測器接收視頻嵌入以及關(guān)于要預(yù)測的額外上下文,并輸出預(yù)測的嵌入。


研究團(tuán)隊用視頻進(jìn)行自監(jiān)督學(xué)習(xí)來訓(xùn)練V-JEPA 2,這就能夠在無需額外人工標(biāo)注的情況下進(jìn)行視頻訓(xùn)練。
V-JEPA 2的訓(xùn)練涉及兩個階段:先是無動作預(yù)訓(xùn)練(下圖左側(cè)),然后是額外的動作條件訓(xùn)練(下圖右側(cè))。

經(jīng)過訓(xùn)練后,V-JEPA 2在運(yùn)動理解方面取得了優(yōu)異性能(在Something-Something v2上達(dá)到77.3的 top-1準(zhǔn)確率),并在人類動作預(yù)測方面達(dá)到了當(dāng)前最佳水平(在Epic-Kitchens-100上達(dá)到39.7的recall-at-5),超越了以往的任務(wù)特定模型。

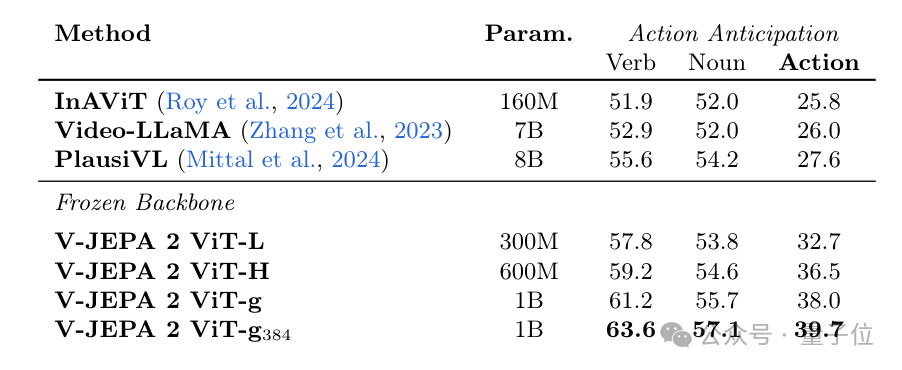
此外,在將V-JEPA 2與大型語言模型對齊后,團(tuán)隊在8B參數(shù)規(guī)模下多個視頻問答任務(wù)中展示了當(dāng)前最佳性能(例如,在PerceptionTest上達(dá)到84.0,在TempCompass上達(dá)到76.9)。

對于短期任務(wù),例如拾取或放置物體,團(tuán)隊以圖像的形式指定目標(biāo)。
使用V-JEPA 2編碼器獲取當(dāng)前狀態(tài)和目標(biāo)狀態(tài)的嵌入。
從其觀察到的當(dāng)前狀態(tài)開始,機(jī)器人通過使用預(yù)測器來想象采取一系列候選動作的后果,并根據(jù)它們接近目標(biāo)的速度對候選動作進(jìn)行評分。
在每個時間步,機(jī)器人通過模型預(yù)測控制重新規(guī)劃并執(zhí)行朝向該目標(biāo)的最高評分的下一個動作。
對于更長期的任務(wù),例如拾取物體并將其放置在正確的位置,指定一系列機(jī)器人試圖按順序?qū)崿F(xiàn)的視覺子目標(biāo),類似于人類觀察到的視覺模仿學(xué)習(xí)。
通過這些視覺子目標(biāo),V-JEPA 2在新的和未見過的環(huán)境中拾取并放置新物體時,成功率達(dá)到65%–80%。

物理理解新基準(zhǔn)
Meta還發(fā)布了三個新的基準(zhǔn)測試,用于評估現(xiàn)有模型從視頻中理解和推理物理世界的能力。
雖然人類在所有三個基準(zhǔn)測試中表現(xiàn)良好(準(zhǔn)確率85%–95%),但人類表現(xiàn)與包括V-JEPA 2在內(nèi)的頂級模型之間存在明顯差距,這表明模型需要改進(jìn)的重要方向。
IntPhys 2是專門設(shè)計用來衡量模型區(qū)分物理上可能和不可能場景的能力,并在早期的IntPhys基準(zhǔn)測試基礎(chǔ)上進(jìn)行構(gòu)建和擴(kuò)展。
團(tuán)隊通過一個游戲引擎生成視頻對,其中兩個視頻在某個點(diǎn)之前完全相同,然后其中一個視頻發(fā)生物理破壞事件。
模型必須識別出哪個視頻發(fā)生了物理破壞事件。
雖然人類在這一任務(wù)上在多種場景和條件下幾乎達(dá)到完美準(zhǔn)確率,但當(dāng)前的視頻模型處于或接近隨機(jī)水平。

Minimal Video Pairs (MVPBench)通過多項選擇題測量視頻語言模型的物理理解能力。
旨在減輕視頻語言模型中常見的捷徑解決方案,例如依賴表面視覺或文本線索以及偏見。
MVPBench中的每個示例都有一個最小變化對:一個視覺上相似的視頻,以及相同的問題但答案相反。
為了獲得一個示例的分?jǐn)?shù),模型必須正確回答其最小變化對。

CausalVQA測量視頻語言模型回答與物理因果關(guān)系相關(guān)問題的能力。
該基準(zhǔn)旨在專注于物理世界視頻中的因果關(guān)系理解,包括反事實(shí)(如果……會發(fā)生什么)、預(yù)期(接下來可能發(fā)生什么)和計劃(為了實(shí)現(xiàn)目標(biāo)下一步應(yīng)該采取什么行動)相關(guān)的問題。
雖然大型多模態(tài)模型在回答視頻中“發(fā)生了什么”的問題方面能力越來越強(qiáng),但在回答“可能發(fā)生了什么”和“接下來可能發(fā)生什么”的問題時仍然存在困難。
這表明在給定行動和事件空間的情況下,預(yù)測物理世界可能如何演變方面,與人類表現(xiàn)存在巨大差距。

One More Thing
Meta還透露了公司在通往高級機(jī)器智能之路上的下一步計劃。
目前,V-JEPA 2只能在單一時間尺度上學(xué)習(xí)和進(jìn)行預(yù)測。
然而,許多任務(wù)需要跨多個時間尺度的規(guī)劃。
所以一個重要的方向是發(fā)展專注于訓(xùn)練能夠在多個時間和空間尺度上學(xué)習(xí)、推理和規(guī)劃的分層次JEPA模型。
另一個重要的方向是多模態(tài)JEPA模型,這些模型能夠使用多種感官(包括視覺、音頻和觸覺)進(jìn)行預(yù)測。
項目地址:
GitHub:https://github.com/facebookresearch/vjepa2
Hugging Face:https://huggingface.co/collections/facebook/v-jepa-2-6841bad8413014e185b497a6
參考鏈接:
[1]https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/
[2]https://x.com/AIatMeta/status/1932808881627148450
[3]https://ai.meta.com/research/publications/v-jepa-2-self-supervised-video-models-enable-understanding-prediction-and-planning/
— 完 —
- 又一高管棄庫克而去!蘋果UI設(shè)計負(fù)責(zé)人轉(zhuǎn)投Meta2025-12-04
- 萬卡集群要上天?中國硬核企業(yè)打造太空超算!2025-11-29
- 學(xué)生3年投稿6次被拒,于是吳恩達(dá)親手搓了個評審Agent2025-11-25
- 波士頓動力前CTO加盟DeepMind,Gemini要做機(jī)器人界的安卓2025-11-25
相關(guān)閱讀

LeCun發(fā)布最新世界模型:首次實(shí)現(xiàn)16秒連貫場景預(yù)測,具身智能掌握第一視角!還打臉用了VAE
讓機(jī)器人從“被動適應(yīng)環(huán)境”到“主動理解環(huán)境”

拿下3D生成行業(yè)新標(biāo)桿!昆侖萬維Matrix-3D新模型鯊瘋了,一張圖建模游戲場景
單圖秒變360°全景,還能直接還原可漫游的3D世界



LeCun、河北大學(xué)校長康樂當(dāng)選美國科學(xué)院院士,另有6位華人學(xué)者位列其中
新增院士120名,其中女性科學(xué)家占總?cè)藬?shù)約1/2




