
百度EasyDL AI開發公開課第1期:實戰解析真實AI場景下,極小目標檢測與精度提升
主講人 | 哈利 百度高級研發工程師
量子位整理編輯
目前,各個企業行業在AI落地應用中,常常會遇到極小目標檢測問題。在這些AI應用中,都需要在一個大圖中精準識別出極小目標,其檢測至關重要,也面臨很多難點。
比如,檢測框高寬比不固定,圖片背景雜亂,數據源稀缺,檢測框相比圖片非常小,這些難點都會導致較高的漏檢率。
10月21日,「EasyDL?AI開發系列公開課」第一期直播中,百度高級工程師以真實的產業場景為例,深入解析了如何解決這些難點、有效提高極小目標檢測的準確率,并手把手演示了如何用EasyDL構建高精度物體檢測模型。
講解分為4個部分:
- EasyDL平臺整體介紹
- 物體檢測任務綜述
- 極小目標檢測場景難點分析以及效果的優化
- EasyDL經典版實操演示
直播回放:
以下為直播文字實錄:
EasyDL平臺介紹
在和某咨詢公司的聯合調研中,我們發現有86%的市場需求需要定制開發業務場景下的AI模型。比如工業場景需要統計原材料的數量,食品安全場景需要監測廚房廚師是否佩戴安全帽,在零售場景需要檢查貨品的陳列是否滿足標準……諸如此類的定制化需求,難以用統一的、標準化的服務去涵蓋,是需要定制開發的。

△需要定制開發AI模型的場景
2017年到2020年,百度AI開發平臺收到的定制化需求增長速度非常快。但是我們知道,機器學習系統構建涉及到非常多的模塊,這些模塊的組合開發具有很大的挑戰性,需要投入大量的人力來做。因此,百度也總結了AI定制需求開發與應用中的核心的痛點:
第一個痛點:數據。用戶很難獲得和場景匹配的數據,并且數據清洗標注、數據的多樣性等方面都存在一些問題。
第二個痛點:開發訓練。用戶開發模型的成本非常高,算力資源不足,算法的調優比較困難,并且訓練耗時長。
第三個痛點:部署。部署的成本非常高,難以落地,模型的適配、遷移難,并且還會有重復開發,預測性能差,硬件成本高等問題。
為了解決這些痛點,百度面向AI開發全流程,提供了一站式的AI開發平臺—EasyDL。EasyDL主要分成三個部分。

第一部分是智能數據服務(EasyData),包括數據采集、數據清洗、數據擴充、數據標注四大能力。
EasyData智能數據服務大幅降低了AI定制模型的數據成本。用戶如果需要進行全流程的數據采集、數據標注、模型迭代,就會涉及非常多環節,而且需要不斷的迭代。而EasyData把整個流程抽象成了5個模塊:軟硬一體數據采集方案,自動數據清洗/擴充,智能標注,模型訓練與發布,自動數據閉環。通過這五大模塊的能力,幫助用戶把數據采集、模型訓練以及最后人工部署的成本都盡可能降低。

第二部分是開發與訓練,提供了AutoDL工具,幫助用戶自動進行模型調優;并引入了百度自有的超大規模預訓練模型,并且預置了很多場景化算法和網絡;在訓練方面提供分布式訓練加速的能力。
EasyDL訓練平臺可以幫助用戶使用更少的數據,獲得更優的效果,而且訓練速度更快。具體來說,基于百度自研的大規模預訓練模型,大幅降低了數據成本;模型的調優方面,采用了領先的AutoDL技術;在訓練方面,應用了飛槳內的訓練加速機制。

第三部分是端云一體服務部署,支持公有云部署、私有化部署和設備端部署(EasyEdge)。
EasyDL提供了靈活豐富的服務部署形態,包含公有云部署、本地服務器部署、設備端SDK以及軟硬一體產品。

以上是EasyDL在移動端/設備端的應用案例,以深圳旅影為例,用戶訓練一個場景識別的模型,僅僅迭代兩版就獲得了97%以上的準確率,效果非常不錯。
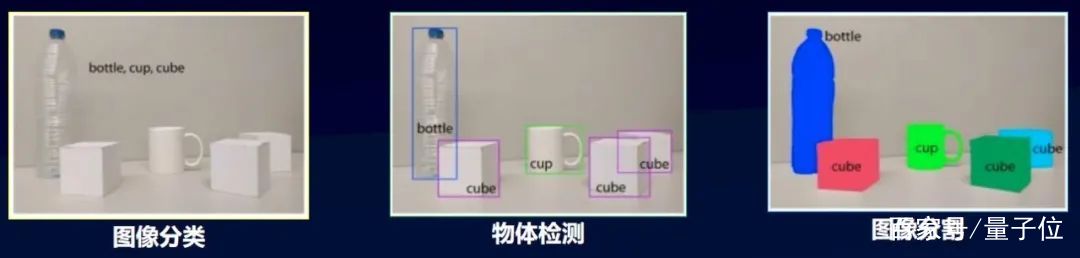
EasyDL目前支持的圖像任務類型包括圖像分類、物體檢測、圖像分割。在企業應用中,圖像分類和物體檢測占比較高,因此百度在這兩方面投入了很多的人力來進行優化。
物體檢測任務綜述
物體檢測定義
物體檢測是指,給定一張圖片,識別出圖片中的物體屬于哪個類別,并對相應的物體進行位置的定位。

物體檢測技術已經發展了很久,從13年至今,主要有兩個方面的發展,一是兩階段檢測器,二是單階段檢測器。總體來說技術朝著越來越自動化、越來越高效的方向發展,來滿足商業化的需求。
檢測器的通用框架
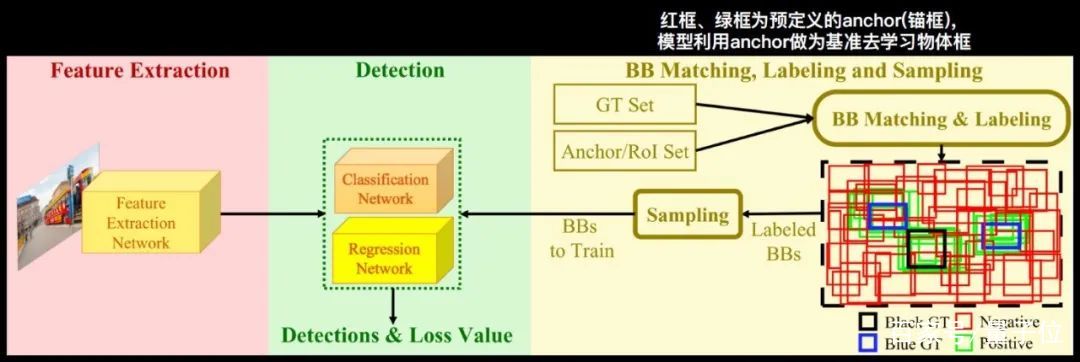
第一個部分是Feature Extraction特征提取模塊,圖像通過這個網絡可以提取出相應的特征。
第二個部分是bonding box Matching,Labeling and Sampling模塊,輸入一系列的物體標注框,會有一系列的anchor(錨框),比如上圖最右邊的紅色和綠色框就是我們預先定義好的anchor,模型就會用這些anchor作為一個基準,再去學習物體的定位。有了這些anchor之后,我們要和這些GT框進行匹配,去挑選出與物體比較吻合的框,稱為正樣本,就是綠色的框,不符合的框是負樣本。
從上圖中可以看出,這里的負樣本的數量非常多,無法直接拿來學習。所以接下來要增加一個采樣的模塊,挑選出適合模型訓練的正負樣本,再輸入到下一個模塊—Detection檢測器,并進行分類網絡和回歸網絡的學習。
極小目標檢測場景難點分析及效果優化
以COCO數據集中的物體定義為例,小物體是指小于32×32個像素點。在實際場景中,我們更傾向于使用相對于原圖的比例來定義。

因此,我們給出相對的定義,物體標注框的長寬乘積,除以整個圖像的長寬乘積,再開根號,如果結果小于3%,就稱之為小物體。

常見的極小目標檢測場景如圖示。這些檢測場景有什么難點呢?總結來說:
難點1:檢測框的高寬比多變,甚至出現極端的高寬比,漏檢率比較高;
難點2:背景雜亂,誤檢率比較高;
難點3:數據源稀缺,沒有豐富的數據訓練;
難點4:圖片非常大,檢測框非常小,所以漏檢率高。
優化案例1:以貨架擋板檢測場景為例

如圖中綠框所示,貨架擋板檢測的難點在于貨架擋板的高寬比非常極端,我們先選一些基礎的模型來訓練。
比如我們取SSD、YOLO、Faster RCNN等,就發現Faster RCNN達到了最好的效果—0.812。怎么進一步優化呢?
針對上述難點1,業界有Anchor自適應算法可以解決這類問題:
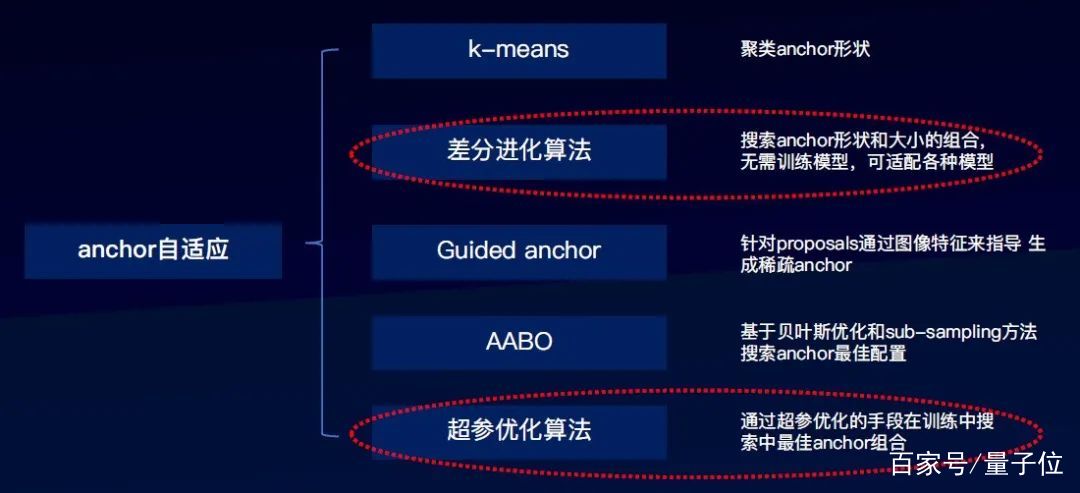
△Anchor自適應算法概覽
我們重點介紹差分進化算法、超參優化算法這兩種具有通用性的技術。
1、差分進化算法
其特點是簡單、高效、可拓展。搜索超參是anchor的高寬比和尺度,優化目標是所有檢測框與匹配的anchor的iou總和最大。
算法上,第一步是初始化種群。第二步是開始迭代的差分進化,保留優秀個體,淘汰劣質個體。包含變異-交叉-選擇3個操作:
變異:從種群中隨機挑選兩個個體,用一定的規則去產生一個變異個體;
交叉:變異個體與事先指定的某個目標個體進行參數混合,生成實驗個體;
選擇:將實驗個體的優化指標與目標個體進行對比,保留優化指標較好的個體;
以上3個操作迭代循環,實現優勝劣汰的能力。
這個方案的優點就是速度快,無需訓練模型,并且可以廣泛的適用于各種檢測模型,這種算法已經在EasyDL經典版上集成了。
2、超參優化算法
其特點是優化目標和訓練模型是一致的。優化目標是訓練中的模型指標(AP)最優,可以運用貝葉斯優化、進化算法等超參優化算法。
優點是以模型評估指標作為優化的目標,效果更佳,并可廣泛適用于各種檢測模型。
其缺點是比較耗費計算資源。但是相關算法能力已經在EasyDL專業版集成,用戶可以通過EasyDL專業版創建項目,實現自動超參搜索。
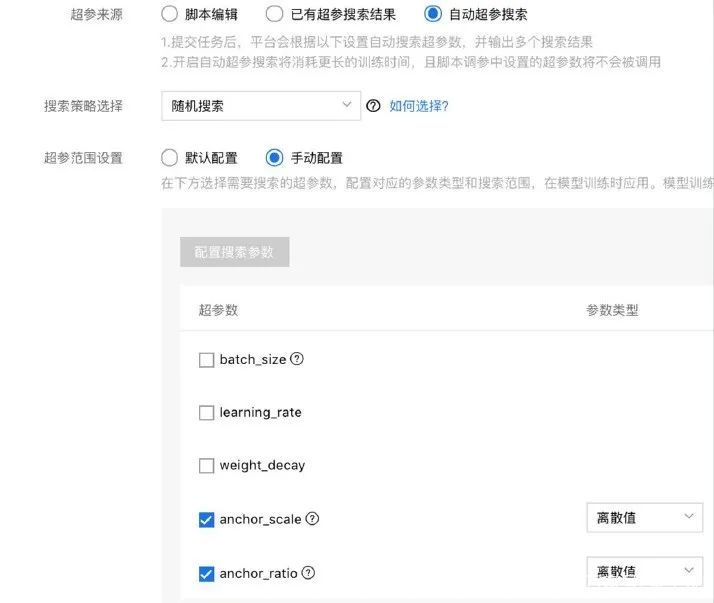
貨架擋板檢測優化—anchor優化
我們將anchor自適應的方法應用在本案例上。相對于默認ratios來說,自適應算法算出了5個比例,也就是說5個比例比較適合于這個模型。

我們用anchor自適應的算法進行優化,效果從0.812提升到0.87。
那么如何進一步優化?我們之前提到了難點2(背景雜亂)和難點3(數據稀缺),現在繼續采用自動數據增強的方案,去優化數據本身。

△自動數據增強算法概覽
我們概覽下自動數據增強的一些主要算法。AutoAugment是第一個能得到很好效果的增強算法,但其搜索成本很高。
PBA算法采用優勝劣汰的思路,在多個網絡的并發訓練中不斷“利用”和“擾動”網絡的權重,以期獲得最優的數據增強調度策略。這個思路直覺上是可以通過優勝劣汰來搜索到最優策略。
DADA借鑒了DARTS的可微設計思路,搜索成本低,但增強算子權重梯度更新的方式限制了數據讀取速度。
以PBA為例,其特點是靈活、可拓展。
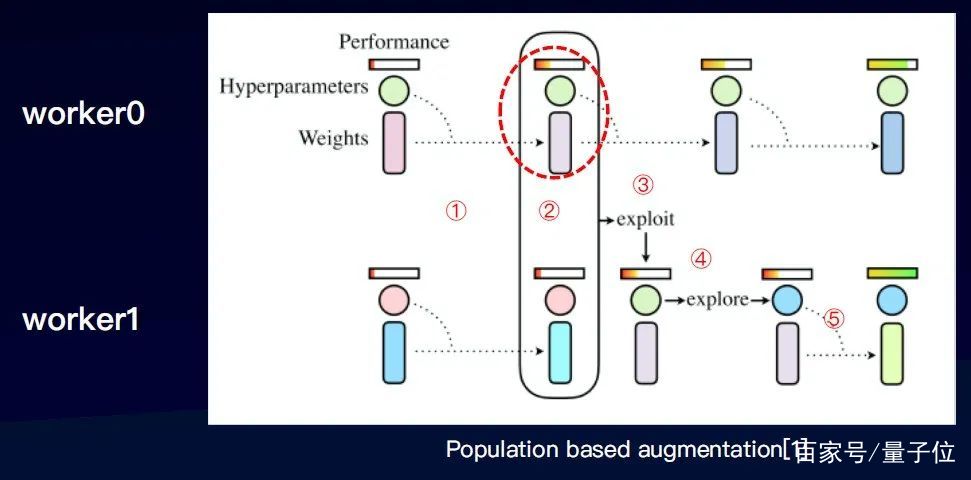
如圖,起兩個進程分別訓練模型,訓練模型的主要參數一是超參,另外一個是權重(模型本身的參數)。
通過第一步訓練,第二步需在某一個時間點,比較兩個進程的效果,效果更優的進程就會取代效果差的進程的權重。第三步,直接復制權重。第四步,擾動原來的超參,產生一組新的超參,并繼續訓練。
迭代循環這個訓練流程,就可以產生一個增強算子的調度組合,并且是比較適合于這個數據集本身的。
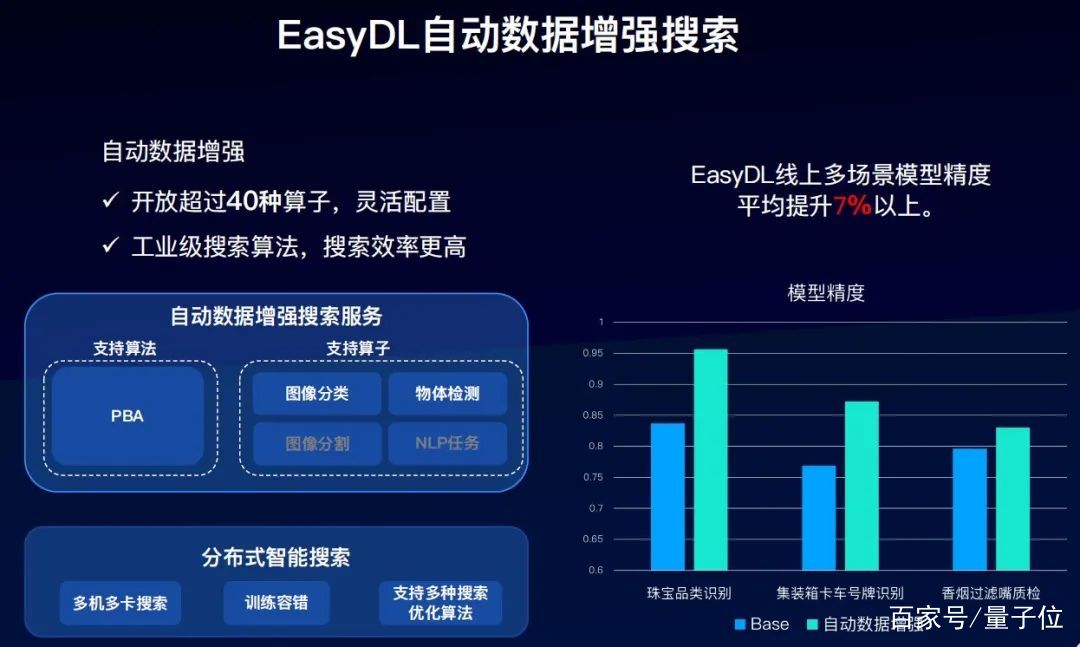
EasyDL也上線了自動數據增強搜索的能力,基于百度自研的分布式智能搜索的能力,目前支持PBA算法。算子方面,支持圖像分類和物體檢測兩種,開放了超過40種的算子。
并且提供了工業級的搜索算法,搜索的效率更高。在EasyDL線上的多場景模型精度上,平均提升了7%以上。
貨架擋板檢測優化—自動數據增強
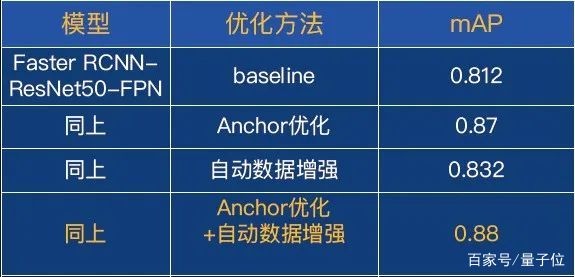
我們把自動數據增強應用在貨架擋板檢測案例上,從原來的0.87提升到了0.88。
我們再考慮一個問題,模型訓練本身的超參非常多,如何才能搜索出最佳超參下的效果呢?
我們可以采用自動超參搜索的技術。
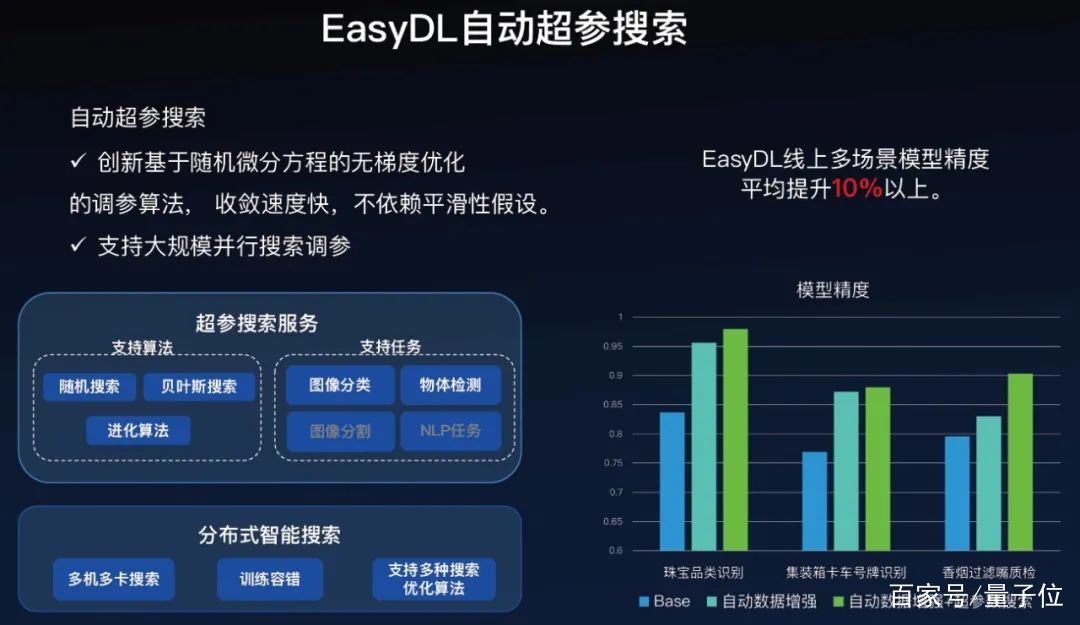
EasyDL的自動超參搜索技術是基于百度內部的分布式智能搜索服務,目前支持隨機搜索、貝葉斯搜索和進化算法三種算法,支持圖像分類和物體檢測兩類任務。
有兩大特點,一是其中的一些算法可以進行無梯度優化,不依賴于平滑性假設。二是支持大規模并行搜索調參。
在EasyDL線上多場景上面,加上我們自動數據增強,再加上超參搜索,檢測精度平均提升10%以上。
貨架擋板檢測優化—自動超參搜索效果
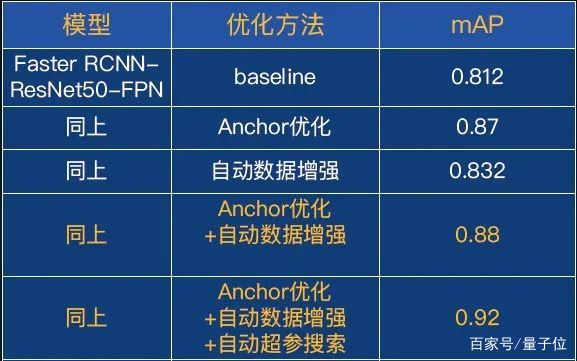
繼續把自動超參搜索應用到本案例中,效果從0.88提升到0.92。總體來說,我們通過一系列的效果優化,從最初的0.812提升到了現在的0.92,效果上非常可觀。
優化案例2:以電力巡檢缺陷檢測為例
接下來我們再看電力巡檢缺陷檢測案例的優化。這個案例的難點在于圖片非常大(4k分辨率),但是檢測框卻非常小,所以其漏檢率非常高。

首先,選擇一個基礎模型,這里選擇了retinanet和Faster RCNN,mAP最高是0.61。
anchor自適應優化

接下來用anchor自適應優化進行調節,藍框是K-means聚類的結果;粉紅框是差分進化的結果,可以看出差分進化算法在匹配效果上更加優秀。
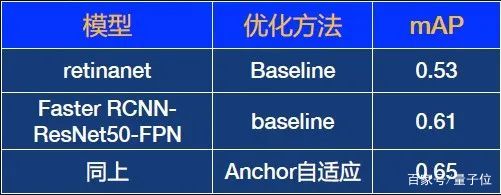
利用anchor自適應優化算法,檢測結果從0.61提升到0.65。效果有所提升,但對于商用場景來說不夠理想。那么,如何從根本上提升效果?
自動切圖優化
這里涉及到了上述的第4個難點,圖片非常大,檢測框非常小。因此,這里就考慮用到自動切圖技術,既能夠不放大圖片尺寸,又能夠放大檢測目標。

我們把這張圖切成了9個子圖,9個子圖有一定的相交。問題是這9張子圖全部都要參與訓練,也就是會增加9倍的簡單的負樣本,而且模型并沒有可以選擇的機會。就會導致模型越學越簡單,無法檢測很難的案例。
如何解決這個問題?首先,挑選出包含較難負樣本的Negative chips切圖,把包括這些較難的負樣本的區域提取出來,作為一個子圖,實現自動挑難負樣本的能力。

△SNIPER-正樣本切圖策略
其次,用切圖代替原圖,并降低計算量。
SNIPER論文考慮到了這個問題,以正樣本的切圖為例,小尺寸圖對應小GT框。

△SNIPER-負樣本切圖策略
對于負樣本,則先訓練幾個epochs,使模型具有一定的分辨能力,標記假陽性的難負樣本,并學習錯誤的樣本。通過這種方式,可以找到最難的一批負樣本切圖。
接下來,把這些正負樣本切圖直接送入到模型的訓練中。SNIPER切圖技術本質上就是一種切圖采樣策略,也就是說,針對任意一個檢測器,都可以采用這樣的前置策略。
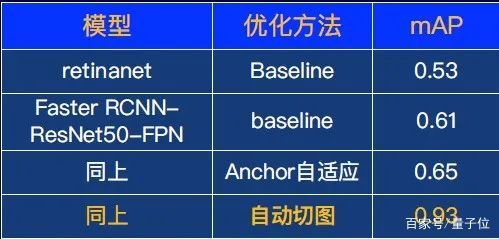
回到案例,采用這種自動切圖技術,效果從0.65直接提升到0.93,這個效果的跨越幅度非常大。這也證明了自動切圖算法能夠從根本上能夠解決小目標檢測的問題。
EasyDL經典版實操演示

詳細操作指南可參考百度EasyDL官網介紹文檔,不再贅述。
—完—
- 天云數據CEO雷濤:從軟件到數件,AI生態如何建立自己的“Android”?| 量子位·視點分享回顧2022-03-23
- 火熱報名中丨2022實景三維創新峰會成都站將于4月13日召開!2022-03-21
- 從軟件到數件,AI生態如何建立自己的“Android”?天云數據CEO直播詳解,可預約 | 量子位·視點2022-03-11
- 什么樣的AI制藥創企才能走得更遠?來聽聽業內怎么說|直播報名2022-03-03









