
英偉達NLP公開課第1期:使用NeMo快速入門NLP、實現機器翻譯任務,英偉達專家實戰講解,內附代碼
對話式AI是當前AI領域最火熱的細分領域之一,其中自然語言處理(NLP)是最為困難的問題之一。
那么,零基礎、對會話式AI感興趣的小伙伴們如何快速入門 NLP領域?
近日,英偉達x量子位發起的NLP公開課上,英偉達開發者社區經理李奕澎老師分享了【使用NeMo快速入門自然語言處理】,介紹了NLP相關理論知識,并通過代碼演示講解了如何使用NeMo方便地調用NLP函數庫及NLP預訓練模型,快速完成NLP各類子任務的應用。
直播回放:
以下為分享內容整理,文末附課程PPT&代碼下載鏈接。
大家好,我是英偉達開發者社區經理李奕澎。今天的課程中,我將首先對自然語言處理(NLP)做出介紹,包括NLP的定義、發展歷程、應用場景;然后帶大家了解NLP的工作流程及原理;接下來將詳細闡述從Word2Vec到Attention注意力機制、從Transformer到BERT模型的內部原理;最后,將通過代碼實戰介紹如何在NeMo中結合BERT模型,快速實現命名實體識別、機器翻譯等任務。
自然語言處理簡介
自然語言處理(NLP)是對話式AI場景中的一個子任務。

對話式AI本質上是一個人機交互的問題,它讓機器能夠聽懂人說的話、看懂人寫的文字,同時機器寫出人看得懂的句子、說出人聽得懂的話。機器能夠“聽”的過程,是由自動語音識別(ASR)技術實現的,機器能夠“說”的過程,是由語音合成(TTS)技術實現的。
本次課程中,我們將把重心放在如何讓機器去理解、懂得人類的語言這一過程,即對話式AI的重中之重—自然語言處理(NLP)技術。
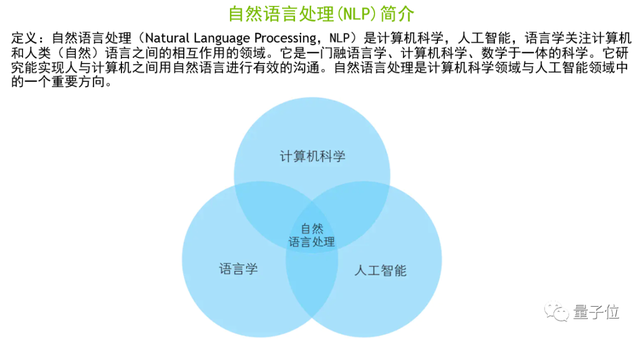
上圖是維基百科對NLP的定義。簡單來說,NLP是一個語言學、計算機科學、人工智能的交叉學科,其目標是實現人與機器之間有關語義理解方面的有效溝通。
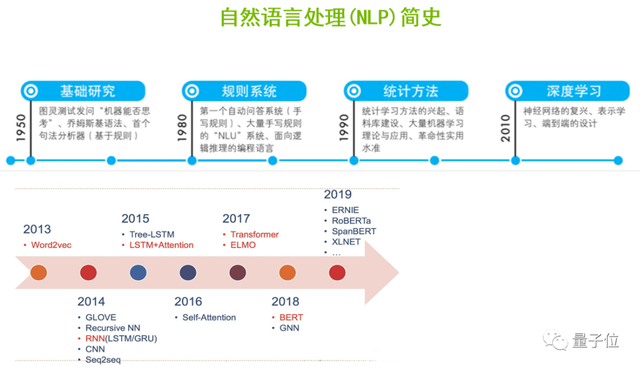
NLP主要經歷了5個重要的發展階段。首先是基礎階段,在1950年從圖靈測試發問“機器是否能夠思考”開始,研究者就根據喬姆斯基語法,基于規則實現了第一個句法分析器。
1980年,由于基于規則系統的研究不斷的發展,第一個基于大量的手寫規則的自動問答系統就誕生了。
1990年,隨著統計學習方法開始興起,結合語料庫的建設和大量機器學習算法不斷的創新和迭代,革命性的應用相繼出現。
到了2010年,隨著深度學習的崛起、神經網絡的復興,包括文字表示學習、端到端設計等思想的進步,讓NLP的應用在效果上得以進一步的提升。
此后,隨著2013年Word2Vec算法的出現、2018年劃時代的BERT模型的誕生,以及從BERT延伸出來的一系列更優秀的算法,NLP進入黃金時代,在工業界的應用領域、實用性和效果得到了大大的提升,實現了落地和產業化。

NLP的應用領域非常之多,比如文本檢索、文本摘要、機器翻譯、問答系統、文本分類/情感分析、對話系統、信息抽取、文本聚類、序列標注、知識圖譜等,上圖介紹了在不同領域的具體應用。
NLP的工作流程和實現原理
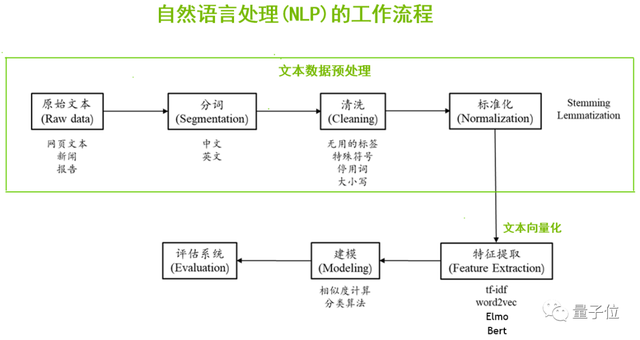
一般來說,當我們拿到一個NLP的項目,首先需要做的是數據預處理,尤其是文本數據預處理。數據的來源比較廣泛,可以通過爬蟲、開源數據集、各種合作渠道等獲得原始的文本數據;我們需要對這些數據進行分詞、清洗、標準化等預處理工作。
接下來,我們要讓計算機認識這些文本,也就是文本向量化,把人類可讀的文字轉換成計算機可以認識的、數字化的過程。可以通過tf-idf、Word2Vec、Elmo、BERT等算法提取到文本的詞向量。
最后再根據相似度計算、分類算法進行建模,訓練模型,并進行推理測試、模型評估、應用部署等。
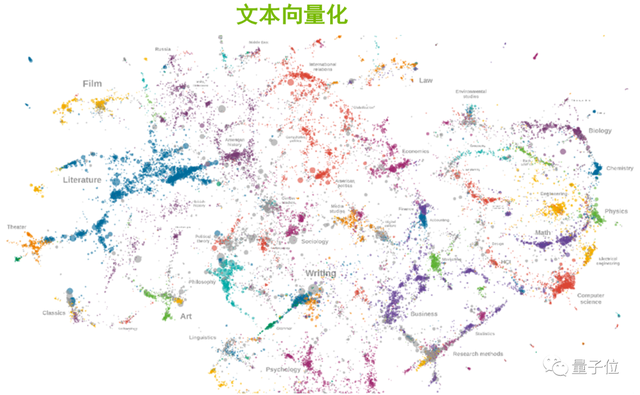
對于其實現原理,比較難理解的是“文本向量化”這一部分,我重點聊一下。俗話說“物以類聚、人以群分”,同樣的,對文本進行向量化之后,能夠發現屬性相近的單詞,在向量空間的分布上更加接近。
那么這些單詞是怎么實現向量化的?
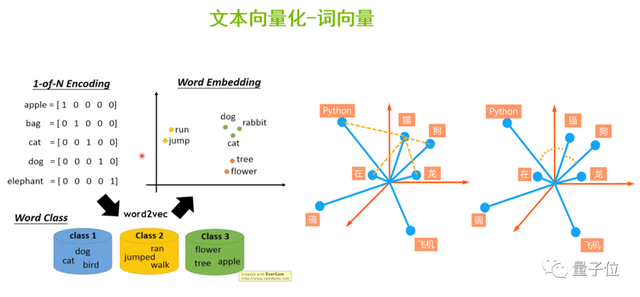
計算機只認識二進制的數據,因此我們需要給語料庫中的每一個單詞進行編碼,從而讓計算機可以認識不同的單詞,并且進行相關的計算。
我們可以采用Onehot編碼,如上圖左側,apple的第一維是1其它是0,bag的第二維是1其它是0,以此類推。但它有一些缺點,一是當語料庫非常龐大時,比如100萬個單詞,這將導致每個單詞都需要表示成100萬維的向量,這種向量是很稀疏的,不利于計算。二是Onehot編碼無法表達相似的單詞之間的相似長度,比如說英文單詞beautiful和pretty,二者意思相近,但是無法通過Onehot編碼的方式表達出來。
為了解決這一問題,我們將Onehot編碼作為輸入,通過Word2Vec算法對它進行降維壓縮,生成更加稠密的詞向量,并投射到向量空間中。這樣,表示動作的動詞run和jump之間的向量位置會比較接近,dog、rabbit、cat等表述動物的名詞會離得比較近。
也就是說,通過Word2Vec生成稠密的詞向量后,便于我們計算單詞間的相似度。
從Word2Vec到Attention注意力機制

可以說,Word2Vec的出現是NLP領域中非常重要的一個節點,下面簡單介紹下。
Word2Vec是連續詞袋模型(CBOW)和跳字模型(Skip-Gram)兩種算法的結合。
CBOW模型的主要思想是用周圍的詞、即上下文來預測中間詞。比如上圖左半部分,首先以pineapples、are、and、yellow這幾個詞的Onehot編碼作為輸入,與初始化的權重矩陣進行矩陣相乘,得到n維的向量;然后進行加權平均,把它作為隱藏層的向量h;再用向量h和另外一個初始化的權重矩陣進行矩陣相乘,最后再經過激活函數的處理,就可以得到一個v維的向量y。向量y當中的每一個元素代表了它相對應的每一個單詞的概率分布,其中概率最大的元素所指的單詞就是我們想要預測的中間詞。
而Skip-Gram模型是通過中間詞來預測上下文。如上圖右半部分,首先是將spikey這個詞的Onehot編碼作為輸入,與初始化的權重矩陣進行矩陣相乘,得到隱藏層的向量h;然后將h與每一個輸出單元的初始化權重矩陣進行矩陣相乘,就可以得到輸出詞及相對的概率。
CBOW與Skip-Gram相結合就是Word2Vec算法,但這種算法也存在一定問題,比如無法解決一詞多義的問題,也就是對上下文語義關系的理解還不夠深入。
為了解決一詞多義的問題,一些更先進的算法,如ELMO、BERT、GPT等算法就相繼出現了。
BERT和GPT都是基于Transformer的結構,而Transformer的核心是注意力機制。
舉個例子,人類瀏覽一段手機介紹的文字時,除了注意價格等因素,男性可能會把更多注意力放在性能、技術參數相關字段,女性則更注意外觀、顏色等字段。
在NLP中,機器也可以模擬人類的注意力機制,根據信息的重要程度更深入的理解文本。

首先介紹下“自注意力機制”的工作流程。
給定兩個單詞,比如Thinking和Machines,第一步是要輸入這兩個單詞的詞向量x1、x2。
第二步,將x1、x2分別與初始化的 q、k、v權重矩陣進行矩陣相乘,得到q1、k1、v1、q2、k2、v2矩陣。其中q矩陣是用來做搜索的,k矩陣是用來被搜索的,v矩陣是值矩陣,是文本內容的本身。
第三步,將q1和k1進行矩陣相乘,將q1和k2進行矩陣相乘,用來計算 Thinking與Machines兩個詞的相關度,來打出注意力的分數。這個分數就體現了上下文中不同單詞間的關聯程度。
第四步,為了防止矩陣點乘后的結果過于龐大,這里需做縮放處理和softmax歸一化的處理。
第五步,將歸一化的結果與值矩陣分別進行點乘,加權求和,就可以得到做完注意力機制之后的z矩陣。
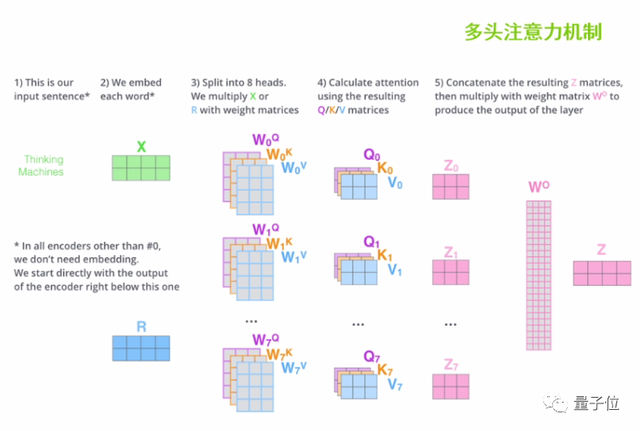
在實際的操作當中,我們可以設置多個自注意力機制的疊加,初始化多個q、k、v權重矩陣參與文本向量的特征提取,也就是“多頭注意力機制”。最后把這多個注意力的頭拿到的注意力矩陣z進行加權求和,就可以得到最終的注意力矩陣Z,便于后續的計算。
從Transformer結構到BERT模型

Transformer的核心是注意力機制,下面一起了解下它的內部的結構。
如上圖左側,藍色框里的Encoder部分是Transformer的編碼器,紅色框里的Decoder部分是Transformer的解碼器。
編碼器的輸入是詞向量本身加上位置嵌入向量形成的向量的和,再經過一層多頭注意力機制層,再經歷帶有殘差網絡結構的Add&Norm層,就走完了第一個子模塊。接下來就進入第二個編碼器子模塊,先經過一個前饋神經網絡層,再接一層基于殘差網絡結構的Add&Norm層,就完成整體的編碼工作。
解碼器除了基于注意力機制、考慮自身的文字信息的輸入之外,它在第二個解碼器子模塊中還考慮了編碼器的輸出結果。
上述就是Transformer的一個編碼器和一個解碼器的工作流程,實際使用中可以重復n次。Transformer論文發表的作者使用了6個編碼器和6個解碼器來實現機器翻譯的任務,取得了非常不錯的效果。

BERT是基于Transformer的雙向語言模型,同時也是一個預訓練模型。
我們可以將BERT理解成Transformer結構中的編碼器,是由多個編碼器堆疊而成的信息特征抽取器。BERT有3個重要的特點:
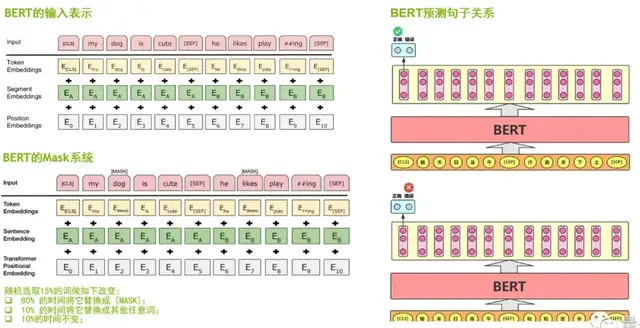
從BERT的輸入表示方面來看,BERT的輸入既有詞嵌入(Token Embeddings),又有位置嵌入(Position Embeddings),同時還加入了分割嵌入(Segment Embeddings),所以BERT的輸入是三個Embeddings求和結果。
從BERT的Mask系統來看,它類似于我們做完型填空的任務。給定一個句子,將其中的某個詞遮擋起來,讓模型根據上下文信息來預測被遮擋起來的詞。這樣能夠讓模型對上下文的語義有更深的理解。
第三點是BERT預測句子關系,即句對分類任務,對被打亂順序的段落進行重新排序,這就需要對整個文章做出充分、準確的理解。因此,我們認為BERT是一個句子級別、甚至文章級別的語言模型,并且在句子分類、問答系統、序列標注、閱讀理解等11項 NLP的任務中都取得了非常好的應用效果。
在NeMo中如何使用BERT
BERT模型如此優秀,那么我們如何快速、方便地利用起來呢?接下來我將通過代碼實戰演示,分享如何在開源工具庫NeMo中玩轉BERT。
接下來,李老師通過代碼演示,分享了如何安裝NeMo、如何在NeMo中調用BERT模型,實現命名實體識別、機器翻譯等任務。大家可觀看直播回放繼續學習。(代碼演示部分從第43分鐘開始)
代碼&課程PPT下載鏈接:https://pan.baidu.com/s/1AXMv7e0EY8ofzgdm4gy-pQ
提取碼: nhk2
下期直播預告
7月14日晚8點第2期課程中,奕澎老師將直播分享使用NeMo快速完成NLP中的信息抽取任務,課程大綱如下:
- 介紹信息抽取技術理論
- 介紹命名實體識別(NER)
- 構建適合NeMo的自定義NER數據集
- 介紹NeMo中的信息抽取模型
- 代碼演示:使用NeMo快速完成NER任務
直播報名:
掃碼-關注“NVIDIA開發者社區”,并根據提示完成報名:

△請準確填寫您的郵箱、便于接收直播提醒&課程資料哦~
—?完?—
- 天云數據CEO雷濤:從軟件到數件,AI生態如何建立自己的“Android”?| 量子位·視點分享回顧2022-03-23
- 火熱報名中丨2022實景三維創新峰會成都站將于4月13日召開!2022-03-21
- 從軟件到數件,AI生態如何建立自己的“Android”?天云數據CEO直播詳解,可預約 | 量子位·視點2022-03-11
- 什么樣的AI制藥創企才能走得更遠?來聽聽業內怎么說|直播報名2022-03-03
相關閱讀









