
騰訊混元開源AI繪畫新框架:24維度對齊人類意圖,讓AI讀懂復雜指令
準確率提升17%
騰訊混元團隊 投稿
量子位 | 公眾號 QbitAI
AI繪畫總“畫不對”,讓創作者一再崩潰。
如今,騰訊混元團隊開源的PromptEnhancer框架,為這一難題提供了解決方案。

無需修改任何預訓練T2I模型的權重,僅通過 “思維鏈(CoT)提示重寫” 這一簡單思路,就能讓AI繪畫的文本-圖像對齊精度大幅提升。
在抽象關系理解、數值約束等復雜場景中,準確率甚至能提升17%以上。

同時,為了助力研究人員進一步深入探索提示優化技術,騰訊混元團隊同步開源了一個全新的高質量人類偏好基準測試數據集。
該數據集圍繞復雜場景構建,包含大量標注數據,不僅為PromptEnhancer的訓練與評估提供了有力支撐,更為相關研究領域提供了重要參考。
核心創新:兩大模塊破解 “理解難題”,實現 “即插即用” 優化
近年來,從Stable Diffusion、Imagen到HunyuanDiT、Flux,T2I擴散模型已能生成超寫實、風格多樣的圖像,但它們對 “人類指令” 的解讀能力,仍存在明顯短板。
騰訊混元團隊在研究中發現,T2I模型的核心問題集中在三大領域:
- 屬性綁定混亂:無法將 “紅色”“條紋” 等屬性精準匹配到 “帽子”“衣服” 等對象上;
- 否定指令失效:輸入 “沒有蔥的牛肉面”,生成的圖像里卻總會出現蔥;
- 復雜關系失控:難以理解 “貓在狗左邊,且比狗小一半” 這類空間與比較關系,更無法渲染 “用橘子瓣拼成的貓” 這種抽象組合場景。
這些問題的根源,在于用戶輸入的簡潔指令與模型需要的 “精細化描述” 之間存在巨大鴻溝。
此前的解決方案要么需要針對特定T2I模型微調,難以通用;要么依賴CLIP分數等粗糙評價指標,無法定位具體錯誤。
這就導致AI繪畫更像 “開盲盒”,而非可控的創作工具。
PromptEnhancer的突破,在于構建了一套與生成模型完全解耦的提示優化框架,核心包含 “CoT-based重寫器” 與 “AlignEvaluator獎勵模型” 兩大模塊,通過兩階段訓練讓AI 學會“精準說話”。

圖1:PromptEnhancer技術架構
由上圖可以看出,PromptEnhancer由兩部分組成,分別是SFT監督訓練用于激活CoT改寫能力,基于AlignEvaluator的GRPO強化學習對齊24個維度。
CoT-based 重寫器:像人類設計師一樣拆解指令
不同于傳統 “關鍵詞堆砌” 式的提示優化,PromptEnhancer的重寫器引入了 “思維鏈(CoT)” 機制——模擬人類設計師的思考過程,將簡潔指令拆解為 “核心元素-潛在歧義-細節補充” 三步驟。

圖2:穿宇航服的湯姆貓在太空漂浮
例如,用戶輸入 “可愛的湯姆穿宇航服在太空漂浮,油畫風格”。
重寫器會先明確 “湯姆是《貓和老鼠》IP角色” 這一背景知識,再補充 “宇航服是米白色多層設計,頭盔帶黃色高光”“太空背景用厚涂技法,星體是白色黃色點彩” 等細節,最終生成結構化的精細化提示。
為讓重寫器掌握這種能力,團隊首先通過 “監督微調(SFT)” 進行初始化。
利用Gemini-2.5-Pro等大模型生成48.5萬組 “原始提示(user prompt)-思維鏈(think)-精細化提示(reprompt)” 數據,讓重寫器學會從 “宏觀概述” 到 “微觀細節” 的描述邏輯。
AlignEvaluator:24維度 “打分”,精準定位錯誤
傳統獎勵模型(如CLIP分數)只能給出 “整體相似度”,無法判斷AI錯在哪。
PromptEnhancer則構建了覆蓋6大類別、24個關鍵維度的評價體系,讓錯誤定位更精準。
這24個關鍵維度幾乎涵蓋了T2I模型的所有 “盲區”,例如:
語言理解:否定指令、代詞指代(如 “它是金屬做的,所以砸壞了桌子” 中的 “它” 是否指 “球”);
視覺屬性:物體數量(3只以上)、材質(冰雕 vs 石雕)、表情(輕蔑 vs 微笑);
復雜關系:包含關系(杯子里裝著蘇打水)、相似關系(湖的形狀像吉他)、反事實場景(女孩抓著蒲公英梗懸在云端)。
AlignEvaluator通過大規模標注數據訓練,能針對每一個維度給出生成圖像的 “精準分數”。
例如 “牛肉面沒畫蔥” 在 “否定指令” 維度得高分,“貓的顏色錯了” 在 “屬性綁定” 維度得低分,從而為提示優化提供明確方向。

圖3:AlignEvaluator評估維度
兩階段訓練:從 “會寫” 到 “寫得好”
有了基礎能力與評價標準,PromptEnhancer通過兩階段訓練讓重寫器持續進化:
階段 1:SFT初始化:掌握結構化描述能力,能生成符合語法邏輯的精細化提示;
階段 2:GRPO強化學習:將重寫器生成的8個候選提示輸入凍結的T2I模型(如Hunyuan-Image 2.1),用AlignEvaluator對生成圖像打分。
通過 “獎勵越高的提示越受重視” 的邏輯,讓重寫器逐漸學會 “生成能讓T2I模型讀懂的提示”。
20個維度準確率提升,復雜場景突破明顯
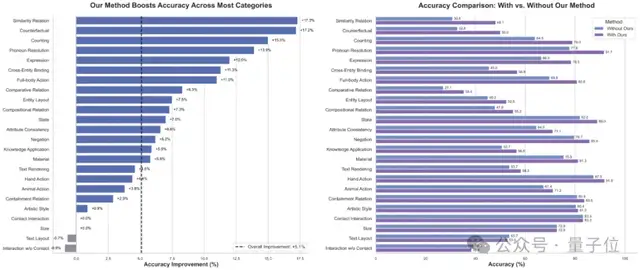
圖4:在24個維度benchmark的文生圖語義準確率
在HunyuanImage 2.1模型上的測試顯示,PromptEnhancer帶來了全方位的性能提升:
整體準確率+5.1%:在24個評價維度中,20個維度實現正提升,僅2個維度出現輕微下降(文本布局-0.7%、無接觸交互-0.9%);
復雜場景突破顯著:在最具挑戰性的 “相似關系”(如 “湖像吉他”)、“反事實推理”(如 “蒲公英梗懸云端”)、“數量計數”(如 “4只狗”)維度,準確率分別提升17.3%、17.2%、15.0%;
風格與細節更精準:在 “面部表情”(如 “輕蔑的表情”)、“跨對象屬性綁定”(如 “男人短發藍襯衫,女人長發黃襯衫”)維度,準確率提升超10%,油畫、點彩等風格的還原度也大幅提高。
從定性效果看,原始提示生成的 “湯姆穿宇航服” 圖像中,宇航服細節模糊、太空背景單調。
而經過PromptEnhancer優化后,不僅角色IP特征清晰,宇航服的紋理、背景的繪畫技法都完全符合用戶預期。
PromptEnhancer的 “即插即用” 特性,在HunyuanImage 2.1、Flux dev、Qwen-Img等主流 T2I 模型上的圖文對齊,真實感,美感均有一定提升,驗證了對不同架構生成模型的適配性。
以下為典型場景的提示詞經過PromptEnhancer改寫前后的效果對比:

圖5:Qwen-Image生成
User Prompt:沒有糖霜的草莓蛋糕,放在鋪著格子餐布的木桌上,油畫質感。

圖6:Qwen-Image生成
Reprompt:一幅油畫作品描繪了一個沒有糖霜的草莓蛋糕,它被放置在一張鋪有格子餐布的木質桌子上。蛋糕主體為圓形,呈現出明顯的厚涂油畫技法,其表面布滿了粗獷的brushstrokes。蛋糕的內部是草莓色的海綿體,結構松軟,層與層之間填充著粉色的果醬。蛋糕頂部裝飾著幾顆新鮮的紅色草莓,其形態和顏色均由厚重的油畫顏料表現。蛋糕下方是一塊格子圖案的餐布,由藍色和白色交織的筆觸構成,鋪設在一張深棕色的木質桌面上,桌面的木紋grain也以明顯的油畫筆觸刻畫出來。整體畫面呈現出強烈的油畫質感,色彩飽和且厚重,筆觸感強烈,是一幅典型的Still-life painting(靜物畫)作品。

圖7:FLUX Dev生成
User Prompt:三只戴著不同顏色領結的兔子,最大的在最左邊,最小的在最右邊,中間的兔子抱著胡蘿卜,低多邊形風格。

圖8:FLUX Dev生成
Reprompt:一幅圖像描繪了三只大小不一、戴著不同顏色領結的兔子,它們以從大到小的順序從左至右排列在一個低多邊形風格的場景中。畫面最左側是體型最大的一只兔子,它身體呈淺灰色,由清晰的多邊形平面構成,脖子上戴著一個紅色的多邊形領結。中間位置是一只中等大小的兔子,它身體為白色,前爪緊緊抱著一個橙色的胡蘿卜,胡蘿卜的葉子是綠色的,同樣呈現出明顯的多邊形結構,它的領結是藍色的。畫面最右側是體型最小的一只兔子,它身體呈淡粉色,脖子上戴著一個黃色的領結,它靜靜地站立著。它們站立的地面是由多邊形塊狀拼接而成,背景是簡單的幾何色塊。整體畫面呈現出鮮明的低多邊形(Low Poly)風格。

圖9:HunyuanImage-2.1生成
User Prompt:手繪作業,一個方塊、兩個三角形和三個圓形,所有圖形的輪廓都是粉色的。

圖10:HunyuanImage-2.1生成
Reprompt:手繪作業。多個基本幾何圖形排列在一個白色的紙張背景上。中央是一個正方形,其輪廓由一條明顯的粉色線條勾勒而成,線條粗細不均,帶有手繪感。在正方形的上方,擺放著兩個三角形,它們的輪廓同樣為粉色。在這些圖形的周圍,散落著三個圓形,它們的邊界也是粉色的線條。所有圖形的內部均為白色,與粉色的輪廓形成對比。背景是白色的畫紙,上面有一些輕微的褶皺或污漬,增加了手繪的真實感。兒童手繪或概念草圖的風格。
這些跨模型測試表明,PromptEnhancer無需針對特定T2I模型做定制化修改,僅通過 “提示重寫+AlignEvaluator 反饋” 的通用邏輯,就能提升不同架構的生成模型的復雜指令理解能力。
這意味著產業界可低成本將該技術嫁接至現有工作流,快速提升AI繪畫的可控性與創作效率。
為了推動提示優化技術的可解釋性與可復現性研究,騰訊混元團隊同步開源了包含6000條Prompt及對應多個維度精細標注的高質量基準測試集。
這套數據集不僅覆蓋 “屬性綁定”“復雜關系”“否定指令” 等T2I模型核心痛點場景,更通過多維度統計分析,為研究人員揭示AI繪畫指令理解的深層規律。
數據集概覽:6k Prompt覆蓋復雜創作場景
該基準測試集的6000條Prompt,圍繞 “人類意圖精準表達” 核心目標構建,涵蓋三類復雜場景:
- 日常創作延伸:如 “穿條紋圍裙的廚師在大理石臺面上切紅蘋果,chiaroscuro明暗對比風格”;
- 抽象關系挑戰:如 “用云朵形狀組成的鯨魚在紫色天空游動,像素藝術風格”;
- 反事實與推理場景:如 “如果貓長著大象的耳朵,它會如何趴在櫻花樹上,浮世繪風格”。
每條Prompt均配備AlignEvaluator所需的24維度標注,確保對 “人類意圖” 的精準捕捉。
Prompt長度分布:指令復雜度的直觀映射

圖11:Prompt的字符長度分布
長度集中于80-120字符區間,峰值約在100字符處,體現數據集以 “中等復雜度指令” 為核心 —— 既覆蓋日常簡短指令的延伸,又能挑戰模型對長指令中多元素關系的理解。
120字符以上的 “長尾區間” 仍有較高頻率,代表 “極復雜指令”(多對象、多屬性、多關系組合指令)的存在,為模型極限能力測試提供素材。
這種分布與真實創作場景高度契合:創作者既會用簡潔指令表達核心想法,也會在專業創作中補充大量細節。
關鍵維度共現:指令復雜度的 “組合密碼”

圖12:Top 24維度共現熱力圖
顏色越深(數值越高),代表兩個維度在同一條Prompt中共同出現的頻率越高。例如,“Style(風格)” 與 “Action-Contact Interaction Between Entities(實體接觸交互)” 共現頻率達676次,說明 “帶風格的動態交互場景” 是創作者高頻需求。
“Attribute-Expression(屬性-表情)” 與 “Action-Character/Anthropomorphic Full Body Movement(角色全身動作)” 共現332次,反映 “角色動作+表情細節” 的組合需求普遍存在。
小眾但關鍵的維度組合也被呈現,如 “Logical Reasoning(邏輯推理)” 與 “Relationship-Comparative(比較關系)” 共現,對應 “貓比狗小一半所以跳得更高” 這類需邏輯鏈條的指令。
未來與展望
PromptEnhancer的意義,不僅在于提升了單模型的生成精度,更從技術與生態層面為 AI 繪畫領域帶來三大突破:
- 通用性:無需修改T2I模型權重,可作為 “即插即用” 模塊適配混元、Stable Diffusion、Imagen等任意預訓練模型,降低優化成本;
- 可解釋性:通過CoT思維鏈與24維度評價,讓 “提示優化” 不再是黑箱,開發者可清晰定位模型的理解盲區;
- 生態補全:團隊同步發布了高質量人類偏好基準,包含大量針對復雜場景的標注數據,為后續提示優化研究提供了重要參考。
隨著AI繪畫從 “娛樂工具” 向 “工業設計、廣告創作” 等專業領域滲透,“精準理解人類意圖” 將成為核心競爭力。
PromptEnhancer通過 “優化指令而非修改模型” 的思路,為這一方向提供了可落地的技術路徑。
未來,創作者或許只需輸入簡單想法,AI就能自動補全專業細節,讓 “所想即所得” 的創作成為現實。
項目主頁:https://hunyuan-promptenhancer.github.io
Github:https://github.com/Hunyuan-PromptEnhancer/PromptEnhancer
PromptEnhancer-7B: https://huggingface.co/tencent/HunyuanImage-2.1/tree/main/reprompt
- 快手進軍AI編程!“模型+工具+平臺”一口氣放三個大招2025-10-24
- 匯報一下ICCV全部獎項,恭喜朱俊彥團隊獲最佳論文2025-10-22
- OpenAI以為GPT-5搞出了數學大新聞,結果…哈薩比斯都覺得尷尬2025-10-20
- 首創“AI+真人”雙保障模式!剛剛,百度健康推出7×24小時「能聊、有料、會管」AI管家2025-10-18
相關閱讀









