
AI繪圖模型不會寫字的難題,被阿里破解了
支持中英日韓四種語言
克雷西 發自 凹非寺
量子位 | 公眾號 QbitAI
能準確寫漢字的AI繪圖工具,終于登場了!
包括中文在內一共支持四種語言,而且還能文字的位置還能任意指定。
從此,人們終于可以和AI繪圖模型的“鬼畫符”說再見了。

這款名為AnyText的繪圖工具來自阿里巴巴,可以按照指定位置精準地向圖中加入文字。
此前的繪圖模型普遍無法準確地向圖中添加文字,即便有也很難支持像中文這樣結構復雜的文字。
而目前Anytext支持中英日韓四種語言,不僅字形準確,風格也可以與圖片完美融合。

除了可以在繪制時加入文字,修改圖片中已有的文字,甚至向其中加字也都不是問題。

究竟AnyText效果如何,我們也實際體驗了一番。
各種風格輕松駕馭
官方在GitHub文檔中提供了AnyText的部署教程,也可以在魔搭社區中體驗。
此外還有網友制作了PyTorch筆記,可以在本地或Colab中一鍵部署,我們采用的也是這種方式。
AnyText支持中英文Prompt,不過從程序日志來看,中文提示詞會被自動翻譯成英文。
比如我們想讓AnyText給馬斯克換上一件白色T恤,讓他來給量子位(QbitAI)打個call。
只需要輸入提示詞,然后設定文本的位置,然后直接運行就可以了。

如果需要調整尺寸等參數,可以將上方的菜單展開;如果不會操作,頁面中還附有中英雙語教程。

最終,在搭載V100的Colab上,AnyText用了10多秒繪制出了四張圖片。
效果還是不錯的,不論是圖本身還是文字,看上去都沒有什么破綻。

而且各種文字材質AnyText都能準確模仿,比如黑板上的粉筆字,甚至是傳統書法……

街景中的文字,甚至是電商促銷海報,都難不倒AnyText。

而且不僅是平面上各式各樣的文字,立體風格同樣也不在話下。

而其中的文本編輯功能,還可以修改已有圖片中的文字,幾乎不會留下破綻。

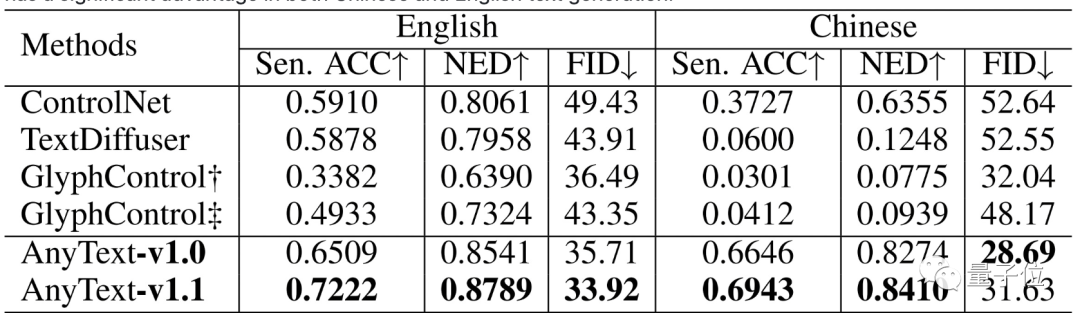
在測試當中,AnyText也是取得了不錯的成績——無論是中英文,準確度都顯著高于ControlNet,FID誤差也大幅減少。
此外,如果自行部署,還可以對字體進行自定義,只需準備好字體文件并對代碼簡單修改就可以了。

那么,研究人員是怎樣讓AnyText學會寫字的呢?
文本渲染獨立完成
AnyText是基于擴散模型開發的,主要分為兩個模塊,文字生成的過程是相對獨立的。
這兩個模塊分別是隱空間輔助模塊和文本嵌入模塊。

其中,輔助模塊對字形、文字位置和掩碼這三種信息進行編碼并構建隱空間特征圖像,用來輔助視覺文字的生成;
文本嵌入模塊則將描述詞中的語義部分與待生成文本部分解耦,使用圖像編碼模塊單獨提取字形信息后,再與語義信息做融合。
在實際工作過程中,嵌入的文本輸送給繪圖模塊時被用星號代替,在嵌入空間預留位置并用符號填充。
然后文本嵌入模塊得到的字形圖像被輸入預訓練OCR模型,提取出字形特征,然后調整其維度并替換預留位置中的符號,得到新的序列。

最后,這個序列表示被輸入到CLIP的文本編碼器中,形成最終指導圖像生成的指令。
這種“分而治之”的方式,既有助于文字的書寫精度,也有利于提升文字與背景的一致性。
此外,AnyText還支持嵌入其他擴散模型,為之提供文本生成支持。
論文地址:
https://arxiv.org/abs/2311.03054
GitHub:
https://github.com/tyxsspa/AnyText
魔搭社區:
https://modelscope.cn/models/damo/cv_anytext_text_generation_editing/summary
筆記:
https://colab.research.google.com/github/camenduru/AnyText-colab/blob/main/AnyText_colab.ipynb
- 14歲華人小孩,折個紙成美國天才少年2025-12-06
- 智能體A2A落地華為新旗艦,鴻蒙開發者新機遇來了2025-12-06
- 《三體》“宇宙閃爍”成真!免佩戴裸眼3D屏登Nature2025-12-06
- ROCK & ROLL!阿里給智能體造了個實戰演練場 | 開源2025-11-26
相關閱讀





免費報名 |《MNN For Swift》移動端機器學習實戰課程
MNN for Swift 正式來啦!伴隨著這個項目一同發布的,還有系列實踐性教程 -《MNN x Swift 機器學習實戰》。




