
任務(wù)級(jí)獎(jiǎng)勵(lì)提升App Agent思考力,淘天提出Mobile-R1,3B模型可超32B
提出具有任務(wù)級(jí)獎(jiǎng)勵(lì)的交互式強(qiáng)化學(xué)習(xí)框架
Mobile-R1團(tuán)隊(duì) 投稿
量子位 | 公眾號(hào) QbitAI
現(xiàn)有Mobile/APP Agent的工作可以適應(yīng)實(shí)時(shí)環(huán)境,并執(zhí)行動(dòng)作,但由于它們大部分都僅依賴于動(dòng)作級(jí)獎(jiǎng)勵(lì)(SFT或RL)。
而這些獎(jiǎng)勵(lì)只能引導(dǎo)代理預(yù)測(cè)每一步中最佳的單一動(dòng)作,因此難以應(yīng)對(duì)不斷變化的移動(dòng)環(huán)境。
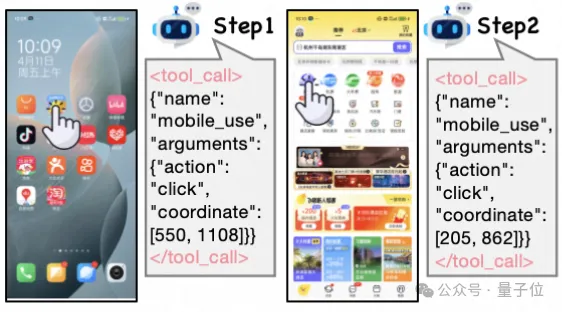
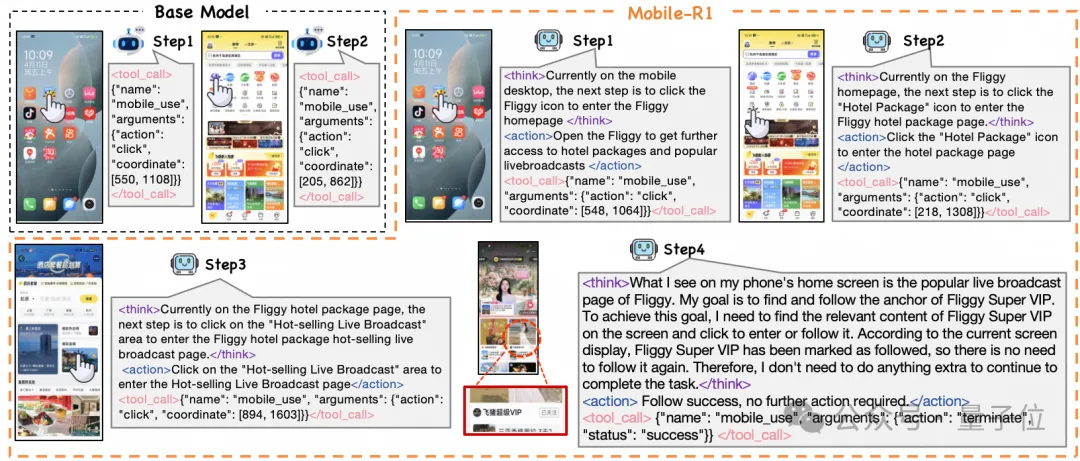
比如一句指令:“打開飛豬,進(jìn)入酒店套餐,進(jìn)入熱門直播,找到飛豬超級(jí)VIP,并關(guān)注主播”。Qwen2.5-VL-3B-Instruct在第二步失敗。
淘天集團(tuán)算法技術(shù)-未來生活實(shí)驗(yàn)室&點(diǎn)淘算法團(tuán)隊(duì)聯(lián)合提出,采用多回合、任務(wù)導(dǎo)向的學(xué)習(xí)方式,結(jié)合在線學(xué)習(xí)和軌跡糾錯(cuò),也許能提高Agent的適應(yīng)性和探索能力。
他們提出了個(gè)具有任務(wù)級(jí)獎(jiǎng)勵(lì)(Task-level Reward)的交互式強(qiáng)化學(xué)習(xí)框架,即Mobile-R1。

為了確保訓(xùn)練的穩(wěn)定性,團(tuán)隊(duì)提出了一個(gè)三階段訓(xùn)練過程:格式微調(diào)、動(dòng)作級(jí)訓(xùn)練和任務(wù)級(jí)訓(xùn)練。此外引入新的中文基準(zhǔn)和高質(zhì)量軌跡數(shù)據(jù)集,證明了該方法在移動(dòng)代理領(lǐng)域的有效性。
結(jié)果Mobile-R1順利地完成了這一任務(wù)。
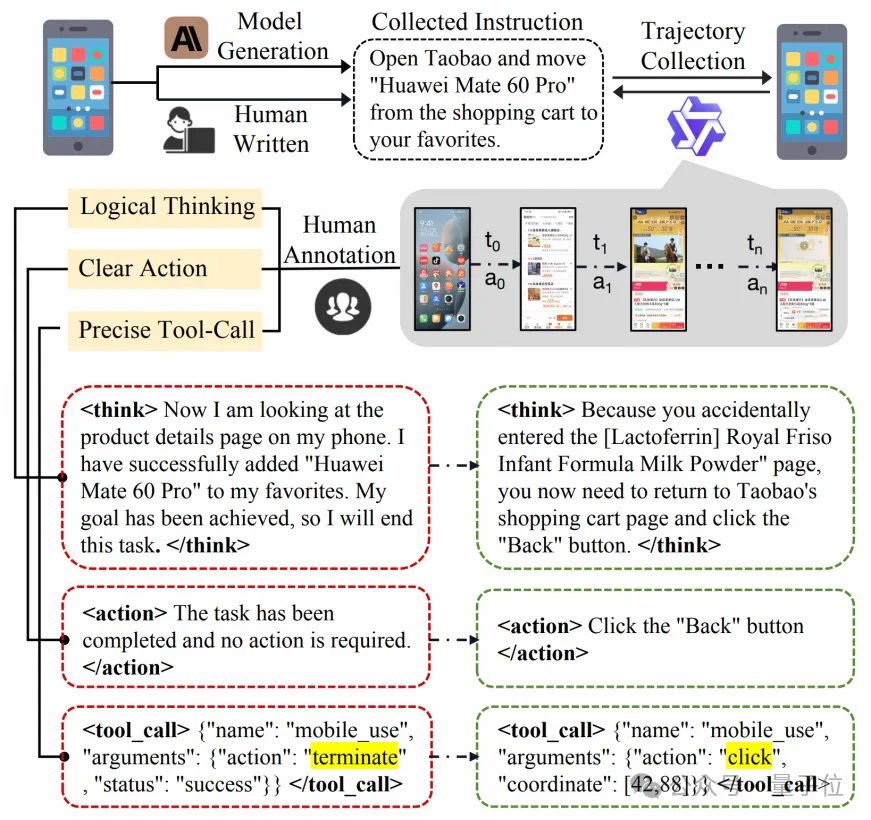
軌跡數(shù)據(jù)集
團(tuán)隊(duì)使用Qwen2.5-VL-3B執(zhí)行一系列任務(wù)獲得初始軌跡,并人工標(biāo)注這些初始軌跡,得到了高質(zhì)量的軌跡數(shù)據(jù)集。
其構(gòu)造可以分為數(shù)據(jù)收集和軌跡標(biāo)注兩部分,最終得到了4,635條高質(zhì)量的人工標(biāo)注軌跡,包含24,521個(gè)單步數(shù)據(jù)。
△軌跡數(shù)據(jù)集構(gòu)造流程
首先,選擇了28個(gè)中國移動(dòng)應(yīng)用程序,通過人工設(shè)計(jì)和自動(dòng)生成相結(jié)合的方法創(chuàng)建了多樣化的任務(wù)指令,隨后統(tǒng)一經(jīng)過人工審核,去除了部分不合理指令。在使用Qwen2.5-VL-3B模型執(zhí)行這些指令后,成功收集了大量動(dòng)作執(zhí)行軌跡,軌跡中的每一步都包含模型輸出的思考,需要執(zhí)行的動(dòng)作以及對(duì)應(yīng)的工具調(diào)用。
得到軌跡后,針對(duì)模型的輸出做了以下三個(gè)維度的標(biāo)注:
- 邏輯思考:將所有思考修正為“當(dāng)前狀態(tài)+下一步的動(dòng)作+動(dòng)作目的”的格式,比如“當(dāng)前在手機(jī)主屏(當(dāng)前狀態(tài)),下一步是點(diǎn)擊淘寶圖標(biāo)(下一步動(dòng)作)來進(jìn)入淘寶(動(dòng)作目的)”。如果原思考內(nèi)容錯(cuò)誤也會(huì)人工標(biāo)注者會(huì)按照該格式重寫思考。
- 清晰動(dòng)作:清晰動(dòng)作是單步可執(zhí)行操作的一句話描述,動(dòng)作應(yīng)符合思考的內(nèi)容并且可推動(dòng)任務(wù)的完成。
- 準(zhǔn)確調(diào)用:人工標(biāo)注者會(huì)修正錯(cuò)誤的操作調(diào)用,包括類型錯(cuò)誤以及參數(shù)錯(cuò)誤。
訓(xùn)練流程
訓(xùn)練流程由三個(gè)階段構(gòu)成,基于Qwen2.5-VL-3B。這三個(gè)階段分別是初始格式微調(diào)、動(dòng)作級(jí)在線訓(xùn)練和任務(wù)級(jí)在線訓(xùn)練。
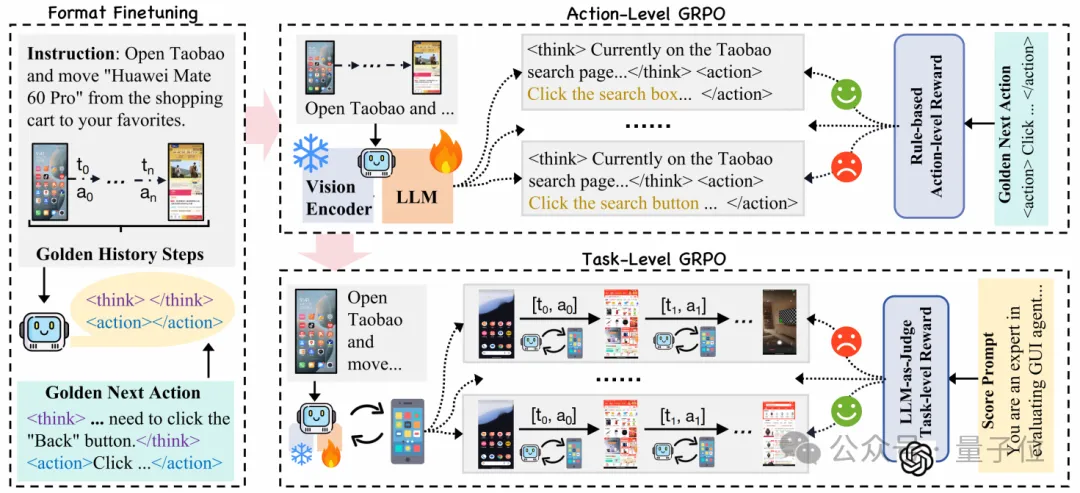
Stage1:初始格式微調(diào)
在第一階段,對(duì)模型進(jìn)行初始格式微調(diào)。這一步是通過監(jiān)督微調(diào)(SFT)的方式進(jìn)行的,使用的是之前人工標(biāo)注的高質(zhì)量軌跡數(shù)據(jù)集。在微調(diào)過程中,模型不僅會(huì)學(xué)習(xí)如何將用戶的指令與當(dāng)前的GUI狀態(tài)對(duì)應(yīng)起來,還會(huì)調(diào)整輸出格式以符合預(yù)期的結(jié)構(gòu),包括邏輯思考、清晰動(dòng)作和準(zhǔn)確調(diào)用。
Stage2:動(dòng)作級(jí)在線訓(xùn)練
在第二階段,模型通過群體相對(duì)策略優(yōu)化(GRPO)進(jìn)行動(dòng)作級(jí)在線訓(xùn)練。此階段使用動(dòng)作級(jí)獎(jiǎng)勵(lì)(Action-level Reward)來評(píng)估每個(gè)動(dòng)作的正確性,同時(shí)確保輸出格式的完整性。動(dòng)作級(jí)獎(jiǎng)勵(lì)由可驗(yàn)證動(dòng)作獎(jiǎng)勵(lì)和格式獎(jiǎng)勵(lì)組成,其中可驗(yàn)證動(dòng)作獎(jiǎng)勵(lì)能夠量化動(dòng)作的正確性,而格式獎(jiǎng)勵(lì)則確保模型輸出是結(jié)構(gòu)化、可解釋的。
- 動(dòng)作級(jí)獎(jiǎng)勵(lì)。1)對(duì)于基于坐標(biāo)的動(dòng)作(如點(diǎn)擊、滑動(dòng)),如果預(yù)測(cè)的坐標(biāo)落在目標(biāo)GUI元素的真實(shí)邊界框內(nèi),則獎(jiǎng)勵(lì)為1,否則為0。2)對(duì)于非坐標(biāo)的動(dòng)作(如輸入文本),如果預(yù)測(cè)的動(dòng)作或參數(shù)與真實(shí)值完全匹配,則獎(jiǎng)勵(lì)為1,否則為0。
- 格式獎(jiǎng)勵(lì)。格式獎(jiǎng)勵(lì)促使模型生成符合標(biāo)簽和結(jié)構(gòu)要求的輸出,確保響應(yīng)的邏輯思考、動(dòng)作以及工具調(diào)用的格式化。
Stage3:任務(wù)級(jí)在線訓(xùn)練
在第三階段,通過多步驟任務(wù)級(jí)在線訓(xùn)練來提高模型的泛化能力和探索能力。
在動(dòng)態(tài)的移動(dòng)環(huán)境中,模型需要進(jìn)行自由探索和錯(cuò)誤糾正,因此我們將問題定義為馬爾可夫決策過程,以允許多回合的互動(dòng)。
任務(wù)級(jí)獎(jiǎng)勵(lì)由格式獎(jiǎng)勵(lì)和軌跡級(jí)獎(jiǎng)勵(lì)組成,旨在鼓勵(lì)模型在整個(gè)軌跡中保持對(duì)響應(yīng)格式的遵循,同時(shí)評(píng)估任務(wù)的完成情況。
- 軌跡級(jí)獎(jiǎng)勵(lì)。軌跡級(jí)獎(jiǎng)勵(lì)使用外部高精度的MLLM,GPT-4o來評(píng)估整個(gè)歷史互動(dòng)軌跡,確保步驟和動(dòng)作的一致性以及任務(wù)的完成情況。
- 格式獎(jiǎng)勵(lì)。格式獎(jiǎng)勵(lì)在此階段仍然起著重要作用,為整個(gè)軌跡計(jì)算平均格式獎(jiǎng)勵(lì),并通過[-1, 1]的范圍來對(duì)錯(cuò)誤施加更嚴(yán)格的懲罰,以增強(qiáng)輸出的精確度。
訓(xùn)練的部分階段在淘天自研的強(qiáng)化學(xué)習(xí)框架ROLL上進(jìn)行實(shí)驗(yàn)。
實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)中,主要評(píng)估了模型在自定義benchmark上的性能,并進(jìn)行了針對(duì)模型泛化能力的魯棒性分析,以驗(yàn)證Mobile-R1的表現(xiàn)。
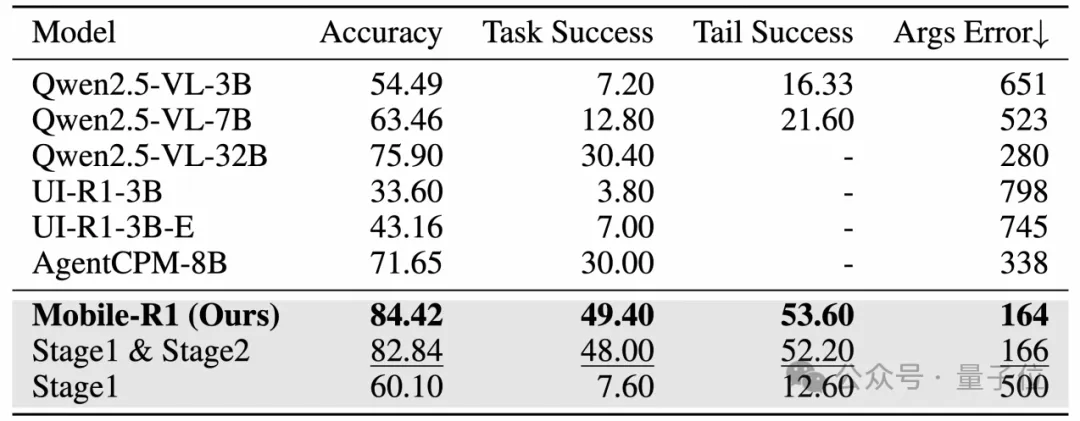 △整體實(shí)驗(yàn)結(jié)果,粗體表示最佳結(jié)果,下劃線表示次優(yōu)結(jié)果
△整體實(shí)驗(yàn)結(jié)果,粗體表示最佳結(jié)果,下劃線表示次優(yōu)結(jié)果結(jié)果顯示,Qwen2.5-VL-32B 和 AgentCPM-8B 在性能上表現(xiàn)類似。
其中,AgentCPM-8B 由于專為中國移動(dòng)生態(tài)系統(tǒng)優(yōu)化,因此在中文場(chǎng)景中表現(xiàn)優(yōu)異。更為顯著的是,Mobile-R1在所有基準(zhǔn)中表現(xiàn)最佳,任務(wù)成功率達(dá)到49.40,比最優(yōu)秀的baseline model高出將近20點(diǎn)。
Stage 3的訓(xùn)練進(jìn)一步增強(qiáng)了Mobile-R1的表現(xiàn),其成功率比只有階段1和階段2訓(xùn)練的模型高出1.4點(diǎn),這得益于任務(wù)級(jí)GRPO的有效應(yīng)用。
特別值得注意的是,通過階段1和階段2的訓(xùn)練,Qwen2.5-VL-3B模型的表現(xiàn)超越了其標(biāo)準(zhǔn)版本,并在多項(xiàng)指標(biāo)上領(lǐng)先于其他基準(zhǔn)模型,突顯了動(dòng)作級(jí)和任務(wù)級(jí)獎(jiǎng)勵(lì)機(jī)制的重要性。
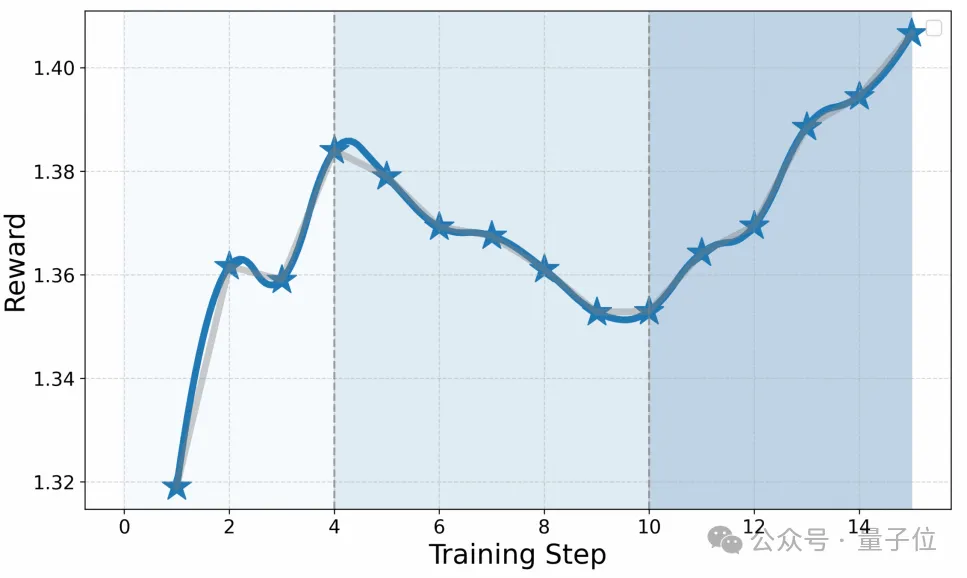 △Stage 3訓(xùn)練的獎(jiǎng)勵(lì)曲線
△Stage 3訓(xùn)練的獎(jiǎng)勵(lì)曲線此過程中,Stage 3的獎(jiǎng)勵(lì)分?jǐn)?shù)顯示出在前四個(gè)訓(xùn)練步驟中穩(wěn)步增長(zhǎng),表明學(xué)習(xí)過程是有效的。然而,在步驟5到10之間,獎(jiǎng)勵(lì)有所下降,這可能是由于策略過于激進(jìn)或探政策的改變導(dǎo)致的不穩(wěn)定性。最終從步驟11開始,獎(jiǎng)勵(lì)再次上升,這表明策略得到了有效的優(yōu)化和改進(jìn)。
Mobile-R1在處理未見應(yīng)用時(shí)表現(xiàn)出良好的泛化性,而其他模型在泛化能力上存在挑戰(zhàn)。Mobile-R1的優(yōu)異表現(xiàn)主要?dú)w功于Stage 3的訓(xùn)練,這一階段有效增強(qiáng)了模型的魯棒性和適應(yīng)性。
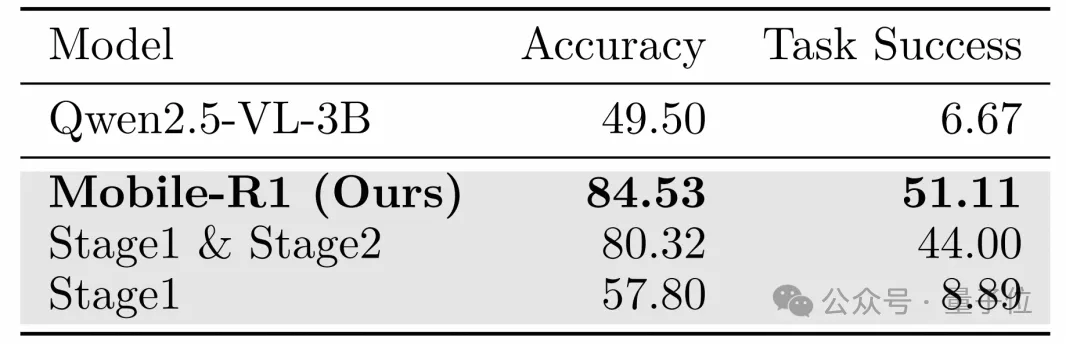 △魯棒性分析結(jié)果,粗體表示最佳結(jié)果
△魯棒性分析結(jié)果,粗體表示最佳結(jié)果最后總結(jié),在本文中,Mobile-R1通過在動(dòng)態(tài)環(huán)境中整合交互式強(qiáng)化學(xué)習(xí)與任務(wù)級(jí)獎(jiǎng)勵(lì),顯著提升了基于視覺語言模型(VLM)的移動(dòng)代理的能力。
通過包括格式微調(diào)、動(dòng)作級(jí)GRPO訓(xùn)練和任務(wù)級(jí)GRPO訓(xùn)練在內(nèi)的三階段訓(xùn)練過程,克服了以往方法僅依賴單一動(dòng)作預(yù)測(cè)的局限性。
實(shí)驗(yàn)結(jié)果表明,Mobile-R1在所有指標(biāo)上都超越了所有基準(zhǔn)。此外,團(tuán)隊(duì)計(jì)劃全面開源相關(guān)資源以促進(jìn)進(jìn)一步的研究。
論文鏈接:https://arxiv.org/abs/2506.20332
項(xiàng)目主頁:https://mobile-r1.github.io/Mobile-R1/
訓(xùn)練框架參考:https://github.com/alibaba/ROLL/
開源數(shù)據(jù): https://huggingface.co/datasets/PG23/Mobile-R1
相關(guān)閱讀

靈快科技獲數(shù)百萬元天使輪融資,發(fā)布能自主進(jìn)化的AI數(shù)據(jù)分析師TabTab
未來將持續(xù)完善“技術(shù)-場(chǎng)景-商業(yè)”閉環(huán)


中科聞歌發(fā)布智川X-Agent平臺(tái)、優(yōu)雅音視頻大模型更新
助力政企極速落地AI應(yīng)用與創(chuàng)意靈感,讓AI技術(shù)精細(xì)化滿足真實(shí)業(yè)務(wù)場(chǎng)景,加速AI普惠落地。

企業(yè)級(jí)Agent已進(jìn)入生產(chǎn)力階段|BetterYeah AI張毅@MEET
關(guān)鍵是數(shù)據(jù)和AI驅(qū)動(dòng),建立反饋評(píng)估-自學(xué)習(xí)-驗(yàn)證的閉環(huán)

數(shù)字技術(shù)工人已到崗!時(shí)序大模型+Agent已掌握了工廠生產(chǎn)管控技術(shù)
個(gè)個(gè)都是資深專家級(jí)別

PPIO亮相WAIC 2025,重磅推出國內(nèi)首個(gè)Agentic AI基礎(chǔ)設(shè)施服務(wù)平臺(tái)
給Agent裝上“大腦”和“手腳”



