
GPT-4o連驗(yàn)證碼都解不了??SOTA模型成功率僅40%
MetaAgentX團(tuán)隊(duì) 投稿
量子位 | 公眾號(hào) QbitAI
當(dāng)前最強(qiáng)多模態(tài)Agent連驗(yàn)證碼都解不了?
MetaAgentX團(tuán)隊(duì)推出首個(gè)專注于“多模態(tài)交互智能體×CAPTCHA(人機(jī)驗(yàn)證)問題”的開放式研究平臺(tái)——Open CaptchaWorld。
該平臺(tái)專門用于測(cè)試Agent解驗(yàn)證碼的能力。

實(shí)測(cè)結(jié)果顯示:人類平均成功率達(dá)93.3%,SOTA多模態(tài)模型平均僅5%-40%不等。
連GPT-4o都被難住了。
驗(yàn)證碼是現(xiàn)階段Agent部署的一大瓶頸
在真實(shí)網(wǎng)頁場(chǎng)景中部署多模態(tài)Agent,你是否也被人機(jī)驗(yàn)證(CAPTCHA)卡住過?
項(xiàng)目團(tuán)隊(duì)發(fā)現(xiàn),不少大型Benchmarks(包括AgentBench、VisualWebArena等)在構(gòu)建過程中都刻意跳過了含驗(yàn)證碼的網(wǎng)頁,仿佛這道攔路虎根本不存在。
但現(xiàn)實(shí)很骨感:驗(yàn)證碼從不是“特例”,而是任何實(shí)際任務(wù)中不可回避的存在,尤其在電商、登錄、票務(wù)等高價(jià)值網(wǎng)頁中更是常見。
于是,Open CaptchaWorld這個(gè)測(cè)試平臺(tái)以及Benchmark應(yīng)運(yùn)而生:一個(gè)針對(duì)多模態(tài)大模型Agent的CAPTCHA解題平臺(tái)與評(píng)估基準(zhǔn)——專為視覺-語言-動(dòng)作交互任務(wù)設(shè)計(jì)。
無論是OpenAI的o3、Anthropic的Claude?3.7-sonnet、還是Gemini?2.5-pro,這些最新的多模態(tài)大模型Agent盡管在靜態(tài)感知任務(wù)(如圖文問答、UI理解)中表現(xiàn)出色,但在真實(shí)交互環(huán)境中常常卡在了CAPTCHA環(huán)節(jié):
- WebAgent在執(zhí)行end-to-end任務(wù)時(shí),常因驗(yàn)證碼而被“卡死”;
- AgentBench、VisualWebArena等主流評(píng)估集普遍過濾掉含CAPTCHA的網(wǎng)頁;
- 過去的驗(yàn)證碼研究(如reCAPTCHA、DeepCAPTCHA)更聚焦靜態(tài)識(shí)別,對(duì)交互、多步規(guī)劃與狀態(tài)跟蹤能力評(píng)估嚴(yán)重不足。
為了系統(tǒng)性地評(píng)估Agent在驗(yàn)證碼中的真實(shí)表現(xiàn),研究團(tuán)隊(duì)設(shè)計(jì)了一個(gè)全新的開放基準(zhǔn)與平臺(tái)——Open CaptchaWorld。
這個(gè)平臺(tái)不僅包含最新的現(xiàn)代驗(yàn)證碼而且類型豐富(20種),全部在真實(shí) Web 瀏覽環(huán)境中進(jìn)行操作,真正復(fù)現(xiàn) Agent 實(shí)際遇到的挑戰(zhàn):
“解圖+理解規(guī)則+計(jì)劃操作+逐步交互” = Agent能力的真實(shí)考驗(yàn)。

Open CaptchaWorld平臺(tái)
具體特點(diǎn)
1、 大規(guī)模、多樣性以及覆蓋全面:研究團(tuán)隊(duì)創(chuàng)作了商用的最新的20類現(xiàn)代驗(yàn)證碼,累計(jì)225個(gè)樣例;類型涵蓋點(diǎn)擊順序、滑塊對(duì)齊、圖像選擇、數(shù)字計(jì)數(shù)、拖拽匹配等。
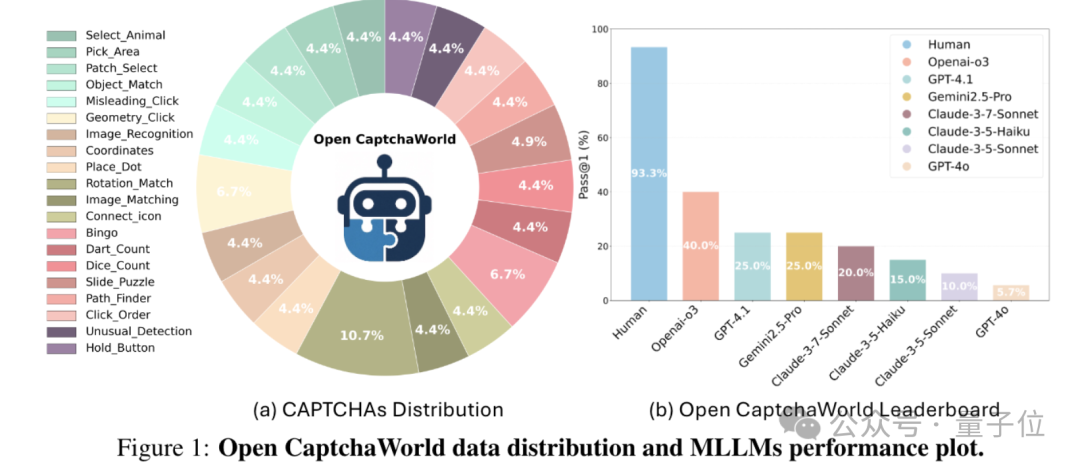
2、 交互真實(shí):所有驗(yàn)證碼均部署在網(wǎng)頁環(huán)境中,Agent必須通過觀察截圖、點(diǎn)擊、拖動(dòng)等方式完成操作,模擬真實(shí)用戶交互流程。
3、 提出新評(píng)估指標(biāo)CAPTCHA Reasoning Depth:用于量化一個(gè)驗(yàn)證碼背后需要多少步“視覺理解+認(rèn)知計(jì)劃+動(dòng)作控制”的過程;是對(duì)傳統(tǒng)“靜態(tài)圖像分類”評(píng)價(jià)方式的重要補(bǔ)充,更貼近Agent真實(shí)解題難度。
4、 對(duì)比分析詳盡:對(duì)OpenAI-o3、GPT-4o、Claude-3.7、Gemini2.5-Pro等模型進(jìn)行系統(tǒng)評(píng)估;人類解題成功率高達(dá)93.3%,最強(qiáng)模型OpenAI-o3僅為40.0%;并從策略偏差、視覺錯(cuò)誤、執(zhí)行失敗等維度剖析失敗原因。
數(shù)據(jù)構(gòu)造方法

Open CaptchaWorld的數(shù)據(jù)集構(gòu)建遵循四階段流程,旨在生成多樣化、高質(zhì)量、可交互的CAPTCHA樣本,用于評(píng)估多模態(tài)智能體在真實(shí)網(wǎng)頁場(chǎng)景下的表現(xiàn)。
第一步:圖像素材構(gòu)建(Type Related CAPTCHA Image Curation)
根據(jù)每類CAPTCHA的設(shè)計(jì)需求,由人類設(shè)計(jì)師或者GPT-4o生成具有變化性的圖像素材。
包括目標(biāo)位置、觀察角度、對(duì)象排布、數(shù)字與元素分布等多種視覺因素的系統(tǒng)調(diào)整,確保每類任務(wù)在結(jié)構(gòu)上具有足夠的多樣性與泛化性。
第二步:驗(yàn)證碼生成(CAPTCHA Generation)
圍繞構(gòu)造好的圖像素材,為每個(gè)實(shí)例配套生成自然語言指令,任務(wù)描述由人類設(shè)計(jì)或由大模型輔助生成,確保語言表達(dá)清晰,易于Agent理解。
指令內(nèi)容涵蓋點(diǎn)擊、滑動(dòng)、拖動(dòng)、計(jì)數(shù)、比對(duì)等典型交互操作,結(jié)合網(wǎng)頁前端組件實(shí)現(xiàn)真實(shí)交互邏輯。
第三步:推理深度估計(jì)(Reasoning Depth Estimation)
為精確刻畫每道CAPTCHA的解題復(fù)雜度,引入“CAPTCHA Reasoning Depth”指標(biāo)。
該指標(biāo)通過人工注釋者對(duì)解題過程的逐步分解,記錄人類在完成任務(wù)時(shí)涉及的視覺識(shí)別、邏輯判斷、記憶操作與交互控制等原子推理步驟,并據(jù)此評(píng)估任務(wù)的綜合認(rèn)知深度。
第四步:標(biāo)準(zhǔn)注釋生成(Annotation)
最終由標(biāo)注人員確認(rèn)每個(gè)CAPTCHA實(shí)例的標(biāo)準(zhǔn)答案,包括操作路徑、點(diǎn)擊位置或數(shù)值輸入結(jié)果。
所有任務(wù)均保證為人類易解(成功率高),同時(shí)具備統(tǒng)一的判定邏輯和網(wǎng)頁反饋接口,為模型訓(xùn)練與評(píng)估提供穩(wěn)定可靠的標(biāo)簽支撐。
多模態(tài)Agent在驗(yàn)證碼面前“過度思考、頻繁失敗”
該團(tuán)隊(duì)發(fā)現(xiàn),多數(shù)先進(jìn)Agent在CAPTCHA面前顯得手足無措,不僅成功率低,而且解題行為遠(yuǎn)不如人類高效。
例如在“序列點(diǎn)擊”任務(wù)中:人類通常只需識(shí)別圖案 → 記住順序 → 一次性點(diǎn)擊完成;
模型(如OpenAI-o3)往往會(huì)把操作細(xì)化為十余步,比如“記住第一個(gè)圖標(biāo)”、“確認(rèn)當(dāng)前狀態(tài)”、“點(diǎn)擊后等待反饋”…… 這種“過度分解任務(wù)”的現(xiàn)象。不僅拖慢操作流程,還增加了出錯(cuò)概率。
這類現(xiàn)象反映出當(dāng)前Agent在高交互、高動(dòng)態(tài)場(chǎng)景下的顯著劣勢(shì):缺乏人類式的抽象、泛化與控制能力。

除此之外研究團(tuán)隊(duì)還展示了當(dāng)前主流多模態(tài)大模型Agent在Open CaptchaWorld上的成本-性能權(quán)衡關(guān)系。
從下圖所示,橫軸為評(píng)估成本(以對(duì)數(shù)刻度表示),縱軸為CAPTCHA解題任務(wù)中的Pass@1成功率(百分比)。每個(gè)點(diǎn)代表一個(gè)具體模型的運(yùn)行結(jié)果。
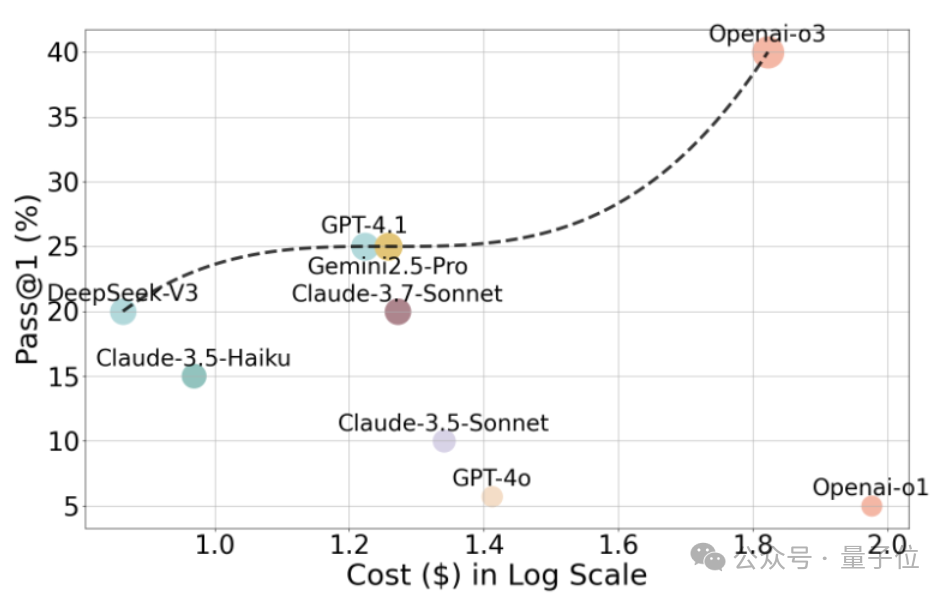
從圖中可以看出,OpenAI-o3雖然在成功率方面顯著領(lǐng)先(達(dá)40.0%),但同時(shí)也是成本最高的模型,顯示出較強(qiáng)的能力但較差的性價(jià)比。
而Gemini2.5-Pro和GPT-4.1等模型在保持相對(duì)較高成功率(約25%)的同時(shí),成本控制更為合理,展現(xiàn)出較好的“單位預(yù)算表現(xiàn)”。
相比之下,Claude-3.5-Sonnet、GPT-4o與OpenAI-o1等模型盡管評(píng)估開銷中等或偏高,但解題成功率較低,顯示出在當(dāng)前CAPTCHA場(chǎng)景下的適配能力仍較弱。
DeepSeek-V3和Claude-3.5-Haiku成本較低,成功率保持在15%~20%區(qū)間,體現(xiàn)出更優(yōu)的成本效率平衡,適合作為輕量級(jí)基線。
總體來看,該圖揭示了多模態(tài) Agent 在真實(shí)交互任務(wù)中并不總是“越貴越強(qiáng)”,也突出了Open CaptchaWorld平臺(tái)在分析Agent實(shí)用性、可部署性方面的重要價(jià)值。
未來的模型設(shè)計(jì)應(yīng)更加關(guān)注效率與性能之間的協(xié)同優(yōu)化。
Open CaptchaWorld平臺(tái)為Agent開發(fā)者、基準(zhǔn)設(shè)計(jì)者提供了新的思路。
也揭示了——
- 當(dāng)前Agent的真實(shí)“短板”——長序列任務(wù)動(dòng)態(tài)交互和規(guī)劃交互能力;
- 現(xiàn)有Benchmark評(píng)估的盲區(qū)——大量省略了真實(shí)部署中不可或缺的“人機(jī)驗(yàn)證”環(huán)節(jié);
- 新模型設(shè)計(jì)方向——如何提升Agent在現(xiàn)實(shí)網(wǎng)頁任務(wù)中的自動(dòng)化與魯棒性。
- Agent時(shí)代下的新型Captcha設(shè)計(jì)——目前的Captcha遲早會(huì)被Agent能力增長而攻破,我們也需要實(shí)時(shí)更新設(shè)計(jì)新的Captcha來順應(yīng)技術(shù)的發(fā)展。
Open CaptchaWorld的提出旨在鼓勵(lì)研究者在訓(xùn)練和評(píng)估Agent時(shí),不再回避CAPTCHA問題,而是勇敢面對(duì)它,因?yàn)樵诂F(xiàn)實(shí)世界中,如果連驗(yàn)證碼都通過不了,這個(gè)Agent就無法落地。
更多細(xì)節(jié)歡迎閱讀原文。
論文鏈接:https://arxiv.org/abs/2505.24878
Huggingface Spaces:https://huggingface.co/spaces/YaxinLuo/Open_CaptchaWorld
代碼庫 & 數(shù)據(jù)鏈接: https://github.com/MetaAgentX/OpenCaptchaWorld
— 完 —
- 又一高管棄庫克而去!蘋果UI設(shè)計(jì)負(fù)責(zé)人轉(zhuǎn)投Meta2025-12-04
- 萬卡集群要上天?中國硬核企業(yè)打造太空超算!2025-11-29
- 學(xué)生3年投稿6次被拒,于是吳恩達(dá)親手搓了個(gè)評(píng)審Agent2025-11-25
- 波士頓動(dòng)力前CTO加盟DeepMind,Gemini要做機(jī)器人界的安卓2025-11-25
相關(guān)閱讀


數(shù)字技術(shù)工人已到崗!時(shí)序大模型+Agent已掌握了工廠生產(chǎn)管控技術(shù)
個(gè)個(gè)都是資深專家級(jí)別

技術(shù)、場(chǎng)景、生態(tài)共振:京東健康發(fā)起“AI普惠醫(yī)療加速計(jì)劃”
京東健康發(fā)布“AI醫(yī)院”、升級(jí)“京醫(yī)千詢2.0”


360重磅發(fā)布企業(yè)級(jí)智能體平臺(tái),啟動(dòng)“千行”計(jì)劃加速產(chǎn)業(yè)智變
實(shí)現(xiàn)智能體“能用、好用、放心用”

李開復(fù)入場(chǎng)Agent!直接對(duì)話CEO走獨(dú)特“一把手工程打法”
預(yù)言三層級(jí)演進(jìn)路徑




