
ICLR 2025 Spotlight:音頻生成新突破!港科北郵團隊首次通過文本控制聲源方向生成音頻
通過文本控制生成多通道音頻在影視娛樂、AR/VR等領域擁有重要應用。
BEWO團隊 投稿
量子位 | 公眾號 QbitAI
兔子通過兩只耳朵可以準確感知捕食者的一舉一動,造就了不同品種廣泛分布在世界各地的生命奇跡;同樣人也需要通過雙耳沉浸式享受電影視聽盛宴、判斷駕駛環境和感知周圍活動狀態。
那應用火爆的diffusion生成模型是否可以做到直接生成符合物理世界規律的空間音頻呢?
此前,經典的Text2Audio的工作可以通過文本抽象的語義生成較為準確的單通道音頻。
但是這忽略了人類與生俱來的感知雙通道音頻的能力。應用角度來說,通過文本控制生成多通道音頻在影視娛樂、AR/VR等領域擁有重要應用。
在這個趨勢的背景下,為了增強文本對于多通道音頻生成的控制,港科大北郵團隊首次從數據、模型和評價標準角度都創新性的將控制聲源方向納入到生成范圍內。
什么是空間音頻生成?
什么是空間音頻?
似乎能夠通過聲音判斷事物方向和狀態是自然人與生俱來的能力。生物聲學 (Bioacoustics)是早在20世紀便進行了深入的探索。人能感知聲音的方位,主要來自以下三個方面:
- ITD (主要不同):Interaural Time Difference-耳間時間差。即由于雙耳耳間距離導致聲音到達兩只耳朵的時間不一樣。這一點是雙通道的主要差異。
- ILD:Interaural Level Difference-耳間聲強差。即由于雙耳耳間距離導致聲音到達兩只耳朵的強度和衰減不一樣。這一點是輔助方式,在實際生成中發現這點較難度量,基本能量一致。
- 耳蝸、耳道和頭骨等生理結構:由于人的感知系統非常復雜,并且涉及物理及生理研究,是一門非常深的學問。在Bioacoustic領域,很多人用深度學習方法構建合理的的HRTF (Head-related transfer function),才能夠很好的模擬生理結構。但是鑒于本文為先期探索工作,文中不考慮這點的影響。

實現空間音頻生成相關的技術路線?
1、雙階段方案:首先通過普通text2audio的模型生成單通道音頻,然后通過仿真或者可學習的濾波器進行串聯。使得最終能夠獲得多通道的空間音頻。這種系統顯然不夠魯棒并且無法適應復雜場景的生成任務。
2、此前的單階段方案:雖然這類系統能夠生成stereo音頻,但是遠遠不具備生成spatial音頻的控制能力。
3、該研究方案:提出了從數據集、方法和評估指標的一條龍解決方案,較好的提升了對于spatial音頻的控制。

數據構造:讓機器“耳聽八方”的數據工廠
在本項研究中,數據構造是整個系統的基石!
想要生成各個方向上的音頻,就必須讓生成模型理解方向上的區別。比如想要讓系統生成摩托自左向右行進,就需要提供摩托在左、在右、自左向右和自右向左的音頻讓系統明白區別。這樣音頻收集的成本顯然是非常巨大的,為什么不做一個高效的“數據工廠”呢?
接下來,帶大家揭秘BEWO-1M(Both Ears Wide Open 1M)數據集的“生產流水線”。
為什么需要BEWO-1M?
現如今一般的音頻-文字數據集都缺乏明確的空間信息描述,比如即便有雙通道音頻,配套的文字描述也只是“汽車駛過”,而沒有具體方位信息(比如“汽車從右前方駛向左前方”)。這對于生成具有方向感的空間音頻完全不夠用!
所以,需要一個超大規模的、帶有豐富空間描述的雙通道音頻數據集,而 BEWO-1M 應運而生。它包含超過100萬條音頻-文本對,并且支持動態聲源、多聲源等復雜場景。

借助近些年的熱門的GPT-4和嚴謹的仿真實驗,最終通過思維鏈(Chain of Thought)構造了一個包含100萬條、共計約2800小時音頻的大規模數據集,其中包括:
- 單聲源靜態音頻子集(Single Stationary):比如“貓在左邊叫”。
- 單聲源動態音頻子集(Single Dynamic):比如“直升機從左飛到右”。
- 多聲源音頻子集(Double, Mixed):比如“左側有雷聲,右側有狗叫”。
- 真實世界音頻子集(Real World):還手動標注了少部分真實錄制的雙通道音頻,確保測試集的真實性。
數據多樣性一覽:

BEWO-1M是目前首個包含方向描述的大規模雙通道音頻數據集,它不僅適用于空間音頻生成,還可以擴展到空間音頻字幕生成(Appendix.G.5)、音頻-文本檢索(Appendix.G.6)等其他任務。在實驗中,發現它能夠顯著提升生成模型的空間控制能力,讓機器真正做到“耳聽八方”。
生成方法簡述
感謝Stability AI的研究者們,他們開發了用于生成雙通道的模型。但是這里生成模型存在比較顯然的音頻生成問題。比如:在Stable Audio中輸入prompt “A piano sound exists on the left side”, 最終生成的鋼琴聲音的方向是不可控的。這是由于他們的雙通道音頻完全由真實數據訓練得到,方向上并不具有足夠的多樣性。所以可控方向的音頻生成模型迫在眉睫。
有了BEWO-1M直接finetune行不行?行!直接使用帶有方位自然語言的prompt,直接進行finetune就能夠讓模型獲取最基本的生成指定方向音頻的能力。對此作者提供了一個通過自然語言控制的Gradio Demo.
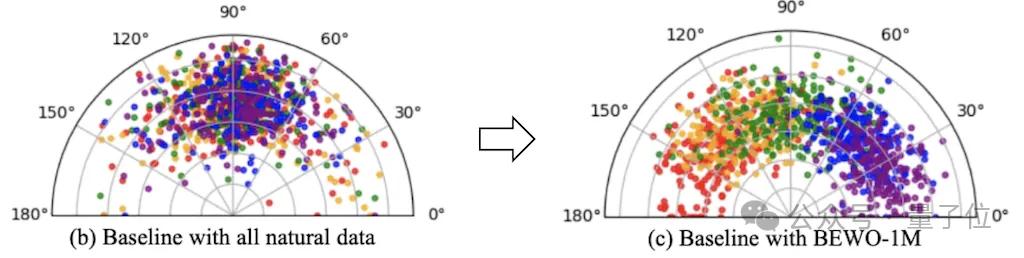
但是涉及到方向自然語言理解的時候存在非常多樣化的表達。這些多樣化的表達對文本的encoder帶來了極大的挑戰。對于T5這個非常經典的編碼模型來說,更長的文本長度會帶來更長的編碼和更大的理解難度。
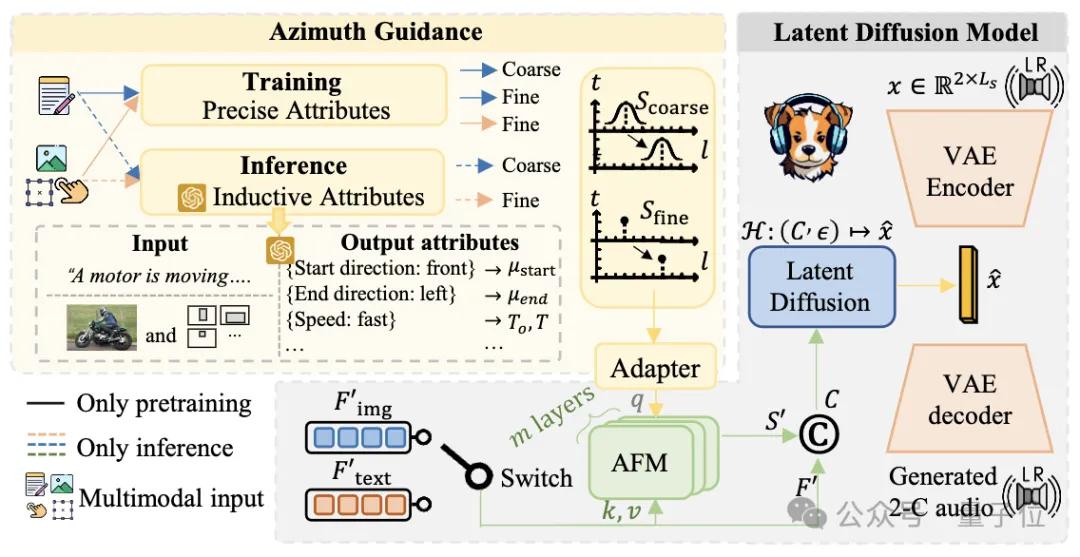
那更進一步地,為了應對這樣的挑戰有兩個非常自然的想法。(1)將空間控制和文本控制解耦;(2)利用大模型對于文本的理解能力。
將空間控制和文本控制解耦.就意味著增加空間控制的引導!空間控制的實現主要來自仿真的訓練數據,作者有極為準確的仿真建模,所以在訓練時的角度是精確到小數點后4位的。那么在訓練的時候使用這個角度是非常自然的。對此作者提供了一個通過精確方位信息控制的Gradio Demo.
利用大模型對于文本的理解能力可以在推理的時候用推理和上下文學習獲取可靠的方向信息(詳見論文),這個方向在人工驗證中正確率高達90%。

通過對空間控制和文本解耦實現了如上圖可視化的更精準的音頻方向的控制。其控制性能相比直接finetune有了精準性的提升。
實驗過程中,作者發現如果使用極為準確的角度建模方式可以生成方向較為準確的音頻,但是生成的音頻語義多樣化欠佳。所以同時開發了coarse建模方式可以獲得更多樣化的音頻生成,但是會出現方向控制不準確的情況。
“多樣性 or 控制” 這個生成千古難題依然在這里是個trade off。
有了基于大量文本音頻對的數據得到的文本控制的模型?那么如何遷移到其他模態上呢。而且文本編碼用的是T5編碼。
眾所周知,T5作為encoder+decoder的model在大模型的現今已經淘汰了。研究團隊簡單借助前人的VL-T5接著做了簡單的對齊實現了簡單的image到spatial audio的生成,這僅僅是給社區提供一個簡單粗糙的圖像引導的音頻生成的baseline。
評價和結果
為了和其他模型比較,研究團隊開發了多種語義和聲源方向上的評估算法。
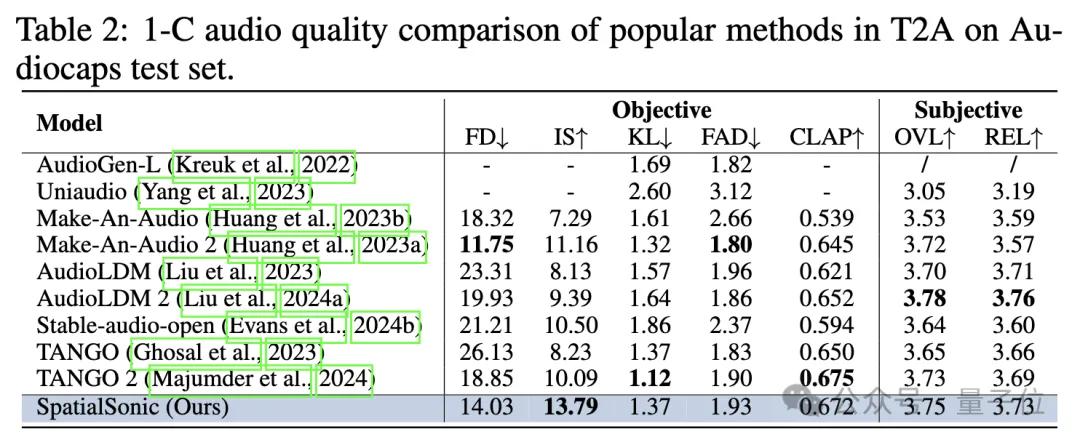
語義層面,此前Text2Audio的生成的評估算法依然有效。作者直接聲道平均后評測語義層面上的相似程度。下表展示了以單通道模型的評估標準評估SpatialSonic模型依然具有一定的先進性。
聲源方向層面,研究團隊創新性地首次提出通過ITD求出方位誤差。根據背景所述,人主要通過ITD來判斷物體的大致方位,同樣也采用ITD作為評估方法。
此前ITD的評估一般由2種方法而來:
- 傳統信號方法:代表為GCC-Phat
- 深度學習方法:代表為StereoCRW
本文利用這兩種ITD評估方法,開發了對兩段音頻的ITD進行不同程度的評估算法(GCC MSE、CRW MSE和FSAD)。通過這些指標很好地展示了模型在文本引導的空間音頻生成上的優越性。

由于音頻本身具有的耦合性,研究團隊堅信這并不是生成音頻ITD相似度的評估算法的最終形態。團隊會不斷在GitHub上更新更優質的算法。更多的實驗結果請參考論文。
如果你好奇如下幾個問題,請向論文中尋求答案!
1、方向的參與程度是否會影響音頻的生成質量?(Appendix.G.9)
是的。作者發現加入方向距離中間偏差越大,生成音頻質量會逐漸下降。比如,質量上,純左<左前<正中。
2、由于方向的加入,必然導致caption長度的增加,這是否會影響音頻的生成質量?(Appendix.G.10)
是的。作者發現caption長度越長,生成質量會下降。
3、不同類別的控制方向能力是否相同?是否存在一些類別聲音控制方向能力較強,一些較弱的Bias?(Appendix.G.11)
確實不同。作者發現對于個別類控制能力較強,其他類控制能力稍弱。推測這與數據分布和GPT induction都存在關聯。
未來展望
未來在以下多方面存在改進空間:
引入HRTF模擬耳道等真實感知。
當前Visual由于使用Coco數據集存在較強的in domain問題。OOD(Out of Distribution)或者OV (Open Vocabulary)會有非常大的進步空間。
Interactive的實現依賴于SAM的性能,實現依然不是非常優雅且存在錯誤累積。
VL-T5早已落后時代,或許作為初步探索足夠,但是未來必然會有更優雅的方式。
項目主頁: https://peiwensun2000.github.io/bewo/
Gradio Demo (自然語言控制): http://143.89.224.6:2436/
Gradio Demo(滑條控制控制): http://143.89.224.6:2437/
Github代碼: https://github.com/PeiwenSun2000/Both-Ears-Wide-Open
Arxiv論文: https://arxiv.org/abs/2410.10676
數據集: https://github.com/PeiwenSun2000/Both-Ears-Wide-Open/tree/main/datasets
- DeepSeek-V3.2-Exp第一時間上線華為云2025-09-29
- 你的AI助手更萬能了!天禧合作字節扣子,解鎖無限新功能2025-09-26
- 你的最快安卓芯片發布了!全面為Agent鋪路2025-09-26
- 任少卿在中科大招生了!碩博都可,推免學生下周一緊急面試2025-09-20
相關閱讀








