
谷歌爆改Transformer,“無限注意力”讓1B小模型讀完10部小說
114倍信息壓縮
明敏 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
谷歌大改Transformer,“無限”長度上下文來了。
現(xiàn)在,1B大模型上下文長度可擴展到1M(100萬token,大約相當(dāng)于10部小說),并能完成Passkey檢索任務(wù)。
8B大模型在500K上下文長度的書籍摘要任務(wù)中,拿下最新SOTA。
這就是谷歌最新提出的Infini-attention機制(無限注意力)。

它能讓Transformer架構(gòu)大模型在有限的計算資源里處理無限長的輸入,在內(nèi)存大小上實現(xiàn)114倍壓縮比。
什么概念?
就是在內(nèi)存大小不變的情況下,放進去114倍多的信息。好比一個存放100本書的圖書館,通過新技術(shù)能存儲11400本書了。
這項最新成果立馬引發(fā)學(xué)術(shù)圈關(guān)注,大佬紛紛圍觀。

加之最近DeepMind也改進了Transformer架構(gòu),使其可以動態(tài)分配計算資源,以此提高訓(xùn)練效率。
有人感慨,基于最近幾個新進展,感覺大模型越來越像一個包含高度可替換、商品化組件的軟件棧了。

引入壓縮記憶
該論文核心提出了一種新機制Infini-attention。
它通過將壓縮記憶(compressive memory)整合到線性注意力機制中,用來處理無限長上下文。
壓縮記憶允許模型在處理新輸入時保留和重用之前的上下文信息。它通過固定數(shù)量的參數(shù)來存儲和回憶信息,而不是隨著輸入序列長度的增加而增加參數(shù)量,能減少內(nèi)存占用和計算成本。
線性注意力機制不同于傳統(tǒng)Transformer中的二次方復(fù)雜度注意力機制,它能通過更小的計算開銷來檢索和更新長期記憶。
在Infini-attention中,舊的KV狀態(tài)({KV}s-1)被存儲在壓縮記憶中,而不是被丟棄。
通過將查詢與壓縮記憶中存儲的鍵值進行匹配,模型就可以檢索到相關(guān)的值。
PE表示位置嵌入,用于給模型提供序列中元素的位置信息。

對比來看Transformer-XL,它只緩存最后一段KV狀態(tài),在處理新的序列段時就會丟棄舊的鍵值對,所以它只能保留最近一段的上下文信息。

對比幾種不同Transformer模型可處理上下文的長度和內(nèi)存占用情況。
Infini-attention能在內(nèi)存占用低的情況下,有效處理非常長的序列。

Infini-attention在訓(xùn)練后,分化出了兩種不同類型的注意力頭,它們協(xié)同處理長期和短期上下文信息。
- 專門化的頭(Specialized heads):這些頭在訓(xùn)練過程中學(xué)習(xí)到了特定的功能,它們的門控得分(gating score)接近0或1。這意味著它們要么通過局部注意力機制處理當(dāng)前的上下文信息,要么從壓縮記憶中檢索信息。
- 混合頭(Mixer heads):這些頭的門控得分接近0.5,它們的作用是將當(dāng)前的上下文信息和長期記憶內(nèi)容聚合到單一的輸出中。

研究團隊將訓(xùn)練長度增加到100K,在Arxiv-math數(shù)據(jù)集上進行訓(xùn)練。
在長下文語言建模任務(wù)中,Infini-attention在保持低內(nèi)存占用的同時,困惑度更低。
對比來看,同樣情況下Memorizing Transformer存儲參數(shù)所需的內(nèi)存是Infini-attention的114倍。
消融實驗比較了“線性”和“線性+增量”記憶兩種模式,結(jié)果顯示性能相當(dāng)。

實驗結(jié)果顯示,即使在輸入只有5K進行微調(diào)的情況下,Infini-Transformer可成功搞定1M長度(100萬)的passkey檢索任務(wù)。
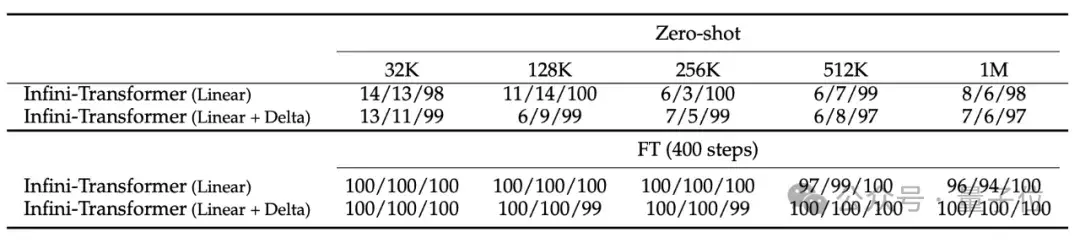
在處理長達500K長度的書籍摘要任務(wù)時,Infini-Transformer達到最新SOTA。

Bard成員參與研究
該研究由谷歌團隊帶來。
其中一位作者(Manaal Faruqui)在Bard團隊,領(lǐng)導(dǎo)研究Bard的模型質(zhì)量、指令遵循等問題。

最近,DeepMind的一項工作也關(guān)注到了高效處理長序列數(shù)據(jù)上。他們提出了兩個新的RNN模型,在高效處理長序列時還實現(xiàn)了和Transformer模型相當(dāng)?shù)男阅芎托省?/p>

感覺到谷歌最近的研究重點之一就是長文本,論文在陸續(xù)公布。
網(wǎng)友覺得,很難了解哪些是真正開始推行使用的,哪些只是一些研究員心血來潮的成果。
不過想象一下,如果有一些初創(chuàng)公司專門做內(nèi)存數(shù)據(jù)庫,但是模型能已經(jīng)能實現(xiàn)無限內(nèi)存了,這可真是太有趣了。

論文地址:
https://arxiv.org/abs/2404.07143
參考鏈接:
[1]https://twitter.com/Joby_Fi/status/1778240236201386072
[2]https://twitter.com/omarsar0/status/1778480897198612839
[3]https://twitter.com/swyx/status/1778553757762252863
- DeepSeek-V3.2-Exp第一時間上線華為云2025-09-29
- 你的AI助手更萬能了!天禧合作字節(jié)扣子,解鎖無限新功能2025-09-26
- 你的最快安卓芯片發(fā)布了!全面為Agent鋪路2025-09-26
- 任少卿在中科大招生了!碩博都可,推免學(xué)生下周一緊急面試2025-09-20
相關(guān)閱讀










