
Meta為元宇宙建全球最快AI超算,1.6萬個A100 GPU,英偉達都賺麻了
今年年中建成
曉查 發自 凹非寺
量子位 | 公眾號 QbitAI
今天,扎克伯格宣布,Meta要建造全球最快的AI超級計算機,而且就在2022年年中建成。
這臺超算被命名為“AI研究超級集群”(RSC),包含16,000個英偉達A100 GPU,算力達5 EFLOPS(混合精度)。
而目前全球最快超算富岳在混合精度下的最高算力為2 EFLOPS。

Meta要這么強的超算干什么?當然是為了公司的元宇宙。
Meta工程師Kevin Lee在官方博客中說:
我們希望RSC將幫助我們構建全新的AI系統,例如可以為大量人提供實時語音翻譯,每個人都可以說著不同的語言,這樣他們就可以無縫協作研究項目或一起玩AR游戲。
最終,使用RSC完成的工作將為下一個主要計算平臺元宇宙發揮重要作用。
要讓不同語言的人在元宇宙無障礙交流,背后的自然語言處理訓練需要巨大的算力。
雖然超算還未建成,但Meta已經開始了訓練超大NLP和CV模型的研究,將用它來訓練數萬億參數模型,其規模比現在的GPT-3還高一個數量級。

1.6萬個A100核心
超算RSC的組建工作始于一年半以前。
英偉達和數據存儲公司Pure Storage、服務器公司Penguin Computing是Meta超算的主要供應商。
RSC的第一階段已經啟動并運行,它由760個Nvidia DGX A100系統組成,總共包含6080個GPU。
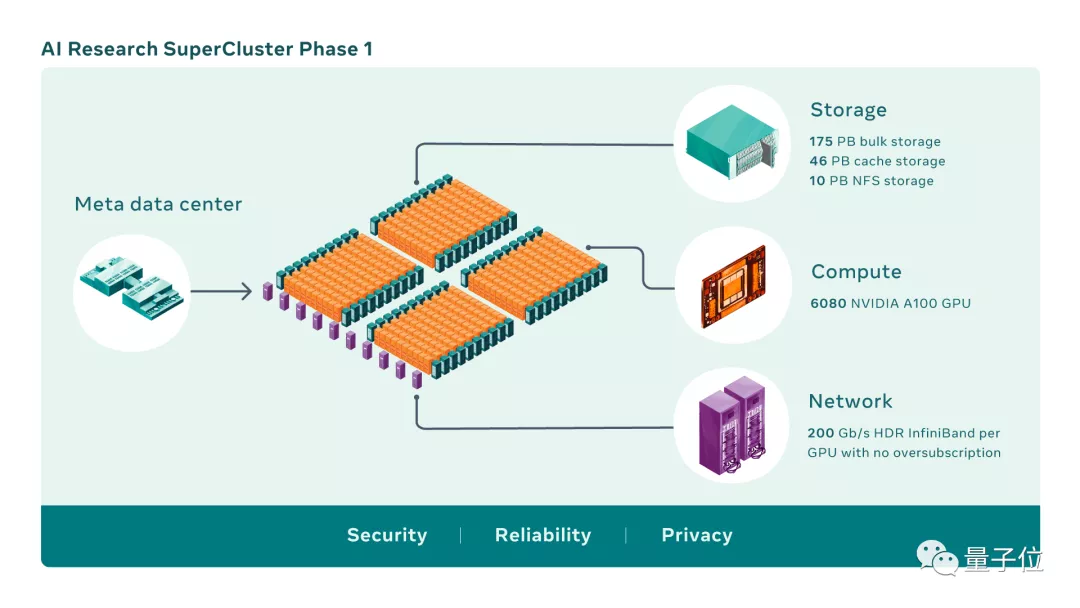
等到完全建成時,RSC將總共擁有16,000個GPU,成為使用A100數量最多的超算。
Meta(當時還叫Facebook)的第一代AI超算設計于2017年,這臺超算集群中擁有22,000個NVIDIA V100 GPU,每天運行35,000個訓練作業。
2020年,Meta的工程師開始利用新的GPU和網絡結構技術,從頭設計新一代超算的冷卻、電力、網絡和布線等各種系統。
相比第一代超算,RSC運行CV工作流程的速度提高了20倍,運行NVIDIA集體通信庫(NCCL)的速度提高了9倍,訓練大型NLP模型的速度提高了3倍。

現在訓練一個具有數百億參數的模型只需三周,而之前是九周。
16TB/s帶寬
除了核心系統本身,Meta還打造一個強大的存儲系統,可以提供16TB/s的存儲帶寬和EB級別的存儲容量。
為了滿足AI訓練日益增長的帶寬和容量需求,Meta從頭開始開發了一種存儲服務,即人工智能研究商店(AIRStore)。
為了優化AI模型,AIRStore利用一個新的數據準備階段,來預處理用于訓練的數據集。經過準備的數據集可用于多次訓練運行。
AIRStore還優化了數據傳輸,從而最大限度地減少了Meta數據中心間主干上的跨區域流量。
最后,在疫情和半導體芯片缺貨的情況下,Meta能一次買下這么多GPU,恐怕英偉達才是最大贏家,老黃真的是賺麻了。
參考鏈接:
[1]https://ai.facebook.com/blog/ai-rsc
[2]https://venturebeat.com/2022/01/24/meta-is-developing-a-record-breaking-supercomputer-to-power-the-metaverse/
- 腦機接口走向現實,11張PPT看懂中國腦機接口產業現狀|量子位智庫2021-08-10
- 張朝陽開課手推E=mc2,李永樂現場狂做筆記2022-03-11
- 阿里數學競賽可以報名了!獎金增加到400萬元,題目面向大眾公開征集2022-03-14
- 英偉達遭黑客最后通牒:今天必須開源GPU驅動,否則公布1TB機密數據2022-03-05
相關閱讀










