
秒秒鐘揪出張量形狀錯誤,這個工具能防止ML模型訓練白忙一場
首爾大學最新開發PyTea
函擎 發自 凹非寺
量子位 報道 | 公眾號 QbitAI
模型吭哧吭哧訓練了半天,結果發現張量形狀定義錯了,這一定沒少讓你抓狂吧。
那么針對這種情況,是否存在較好的解決方法呢?
這不最近,韓國首爾大學的研究者就開發出了一款“利器”——PyTea。
據研究人員介紹,它在訓練模型前,能幾秒內幫助你靜態分析潛在的張量形狀錯誤。
那么PyTea是如何做到的,到底靠不靠譜,讓我們一探究竟吧。
PyTea的出場方式
為什么張量形狀錯誤這么重要?
神經網絡涉及到一系列的矩陣計算,前面矩陣的列數必需匹配后面矩陣的行數,如果維度不匹配,那后面的運算就都無法運行了。

上圖代碼就是一個典型的張量形狀錯誤,[B x 120] * [80 x 10]無法進行矩陣運算。
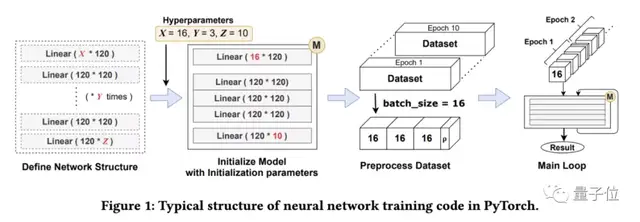
無論是PyTorch,TensorFlow還是Keras在進行神經網絡的訓練時,大多都遵循圖上的流程。
首先定義一系列神經網絡層(也就是矩陣),然后合成神經網絡模塊……
那么為什么需要PyTea呢?
以往我們都是在模型讀取大量數據,開始訓練,代碼運行到錯誤張量處,才可以發現張量形狀定義錯誤。
由于模型可能十分復雜,訓練數據非常龐大,所以發現錯誤的時間成本會很高,有時候代碼放在后臺訓練,出了問題都不知道……
PyTea就可以有效幫我們避免這個問題,因為它能在運行模型代碼之前,就幫我們分析出形狀錯誤。
網友們已經在熱烈討論了。
PyTea是如何運作的,它能否有效地檢查出錯誤呢?
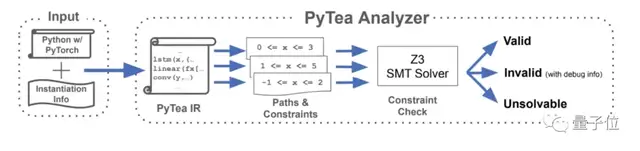
受各種約束條件的影響,代碼可能的運行路徑有很多,不同的數據會走向不同的路徑。
所以PyTea需要靜態掃描所有可能的運行路徑,跟蹤張量變化,推斷出每個張量形狀精確而保守的范圍。
上圖就是PyTea的整體架構,一共分為翻譯語言,收集約束條件,求解器判斷和給出反饋四步。

首先PyTea將原始的Python代碼翻譯成一種內核語言。PyTea內部表示法(PyTea IR)。
接著PyTea追蹤PyTea IR每個可能的執行路徑,并收集有關張量形狀的約束條件。
判斷約束條件是否被滿足,分為線上分析和離線分析兩步:
- 線上分析 node.js(TypeScript / JavaScript):查找張量形狀數值上的不匹配和誤用API函數的情況。如果PyTea發現問題,就會停止在當前位置,然后給用戶報錯。
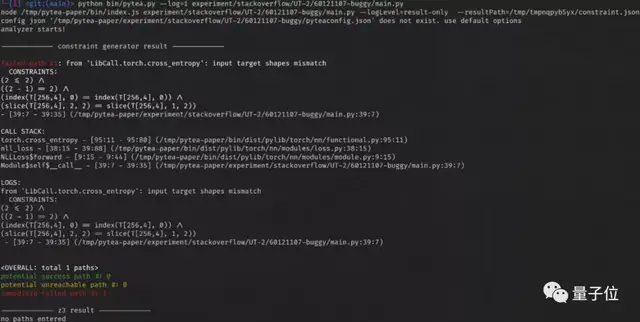
- 離線分析 Z3/Python:如果線上分析沒有問題,PyTea將收集到的約束條件傳給SMT(Satisfiability Modulo Theories)求解器 Z3,求解器負責查看每條路徑的約束條件是否都能被滿足,如果不能,返回給用戶第一條出錯路徑的約束條件。
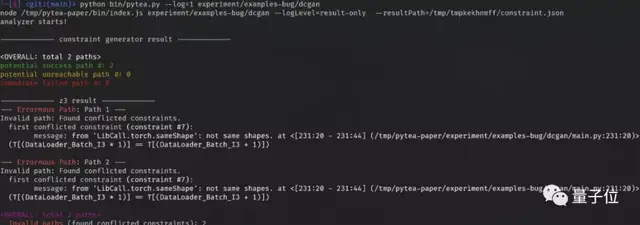
如果求解器過久沒有反應,PyTea會返回不知道是否存在問題。
然而追蹤所有可能的路徑是指數級別的任務,對于復雜的神經網絡來說,一定會發生路徑爆炸這個問題。

比如說在這個例子中,網絡的最終結構是由24個相同模塊塊構成的(第17行),那么可能的路徑就有16M之多。
所以路徑爆炸是一定要處理的,PyTea是怎么做的?
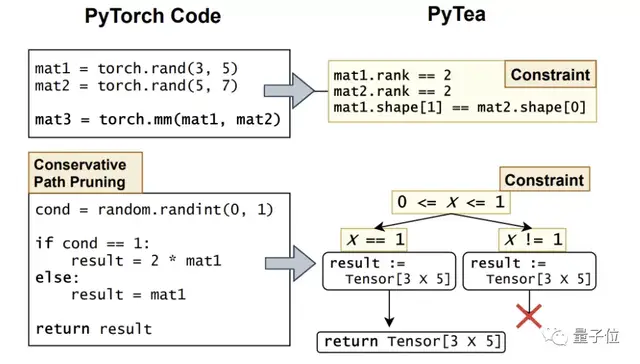
PyTea選擇保守的地對路徑剪枝和超時判斷來處理這種路徑爆炸。
什么樣的路徑可以被剪枝?
PyTea給出的答案是,如果該前饋函數不改變全局值,并且它的輸出值不受分支條件影響,對于每條路徑都是相等的,我們就可以忽略許多完全一致的路徑,來節約計算資源。
如果路徑剪枝還是不行,那么就只能按超時處理了。
原理就介紹這么多了,感覺還是值得一試的,現在代碼已經在GitHub上面開源了,快去看看吧!
使用方法
依賴庫:

安裝方法:

運行命令:

參考鏈接:
[1]https://github.com/ropas/pytea
[2]https://arxiv.org/abs/2112.09037
- 商湯Seko上線一個月,超10萬創作者選擇它2025-09-29
- 戴爾 x OpenCSG,推出?向智能初創企業的?體化 IT 基礎架構解決方案2025-12-10
- 看完最新國產AI寫的公眾號文章,我慌了!2025-12-08
- 共推空天領域智能化升級!趨境科技與金航數碼強強聯手2025-12-09
相關閱讀



「AI崗面試必備」XGBoost、Transformer、BERT、水波網絡原理解析
貪心學院特此組織了這次的學習小組計劃,深入淺出講解每個算法模型的每一個技術細節。對于想了解算法底層的朋友們來說,參加這次活動絕對有很大收獲!






