
魚羊 發自 副駕寺
智能車參考 報道 | 公眾號 AI4Auto
通常,自動駕駛汽車通過單目攝像頭看到的世界長這個樣子:

馬路上的其他車輛、物體,都被統一建模成一個個立方體,具體的結構細節則被忽略。
想要更精準地勾勒出車輛的真實形態,當然也不是不行,但那就需要用上激光雷達、雙目相機等更加昂貴的傳感器。
不過現在,一項最新研究賦予了單目攝像頭新的能力——
是的,僅憑單目相機,就能實時感知物體的3D形狀,進而提高3D目標檢測性能。
這項研究來自百度,論文已經入選ICCV 2021。
考慮2D/3D形狀感知約束的3D檢測框架
具體如何實現?
大體上可以分為三步:
- 首先,引入CAD模型,在CAD模型上預先定義幾個不同的3D關鍵點。
- 然后利用深度學習網絡,來建立3D關鍵點和它們在圖像上的2D投影之間的關聯。
- 最后,利用這樣的對應關系為每個目標物體建立2D/3D約束。
整體的網絡架構如上圖所示,8個分支頭分別對應中心點分類、中心點偏移、2D關鍵點、3D坐標、關鍵點置信度、物體方向、維度,以及3D檢測置信度得分。所有回歸信息最后都會被用來恢復物體在攝像機坐標中的3D邊界框。
而為了自動生成2D/3D關鍵點的真實標注,研究人員還提出了一種自動模型擬合方法。也就是根據攝像頭觀測到的2D圖像,自動擬合不同的3D物體模型和物體掩碼。
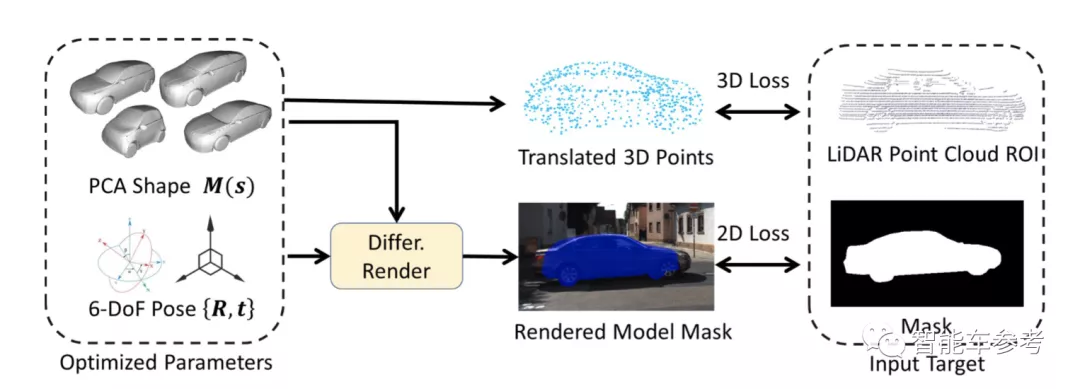
具體而言,該方法是基于不同種類的車輛CAD模型,以及KITTI數據集中的3D物體樣本實現的。
研究人員指出,實際上,3D形狀標注的過程可以看作一個優化問題,其目的是計算出最佳參數組合,來適應AI通過“視覺觀察”得到的結果(如2D物體掩碼、3D邊界框、3D點云等)。
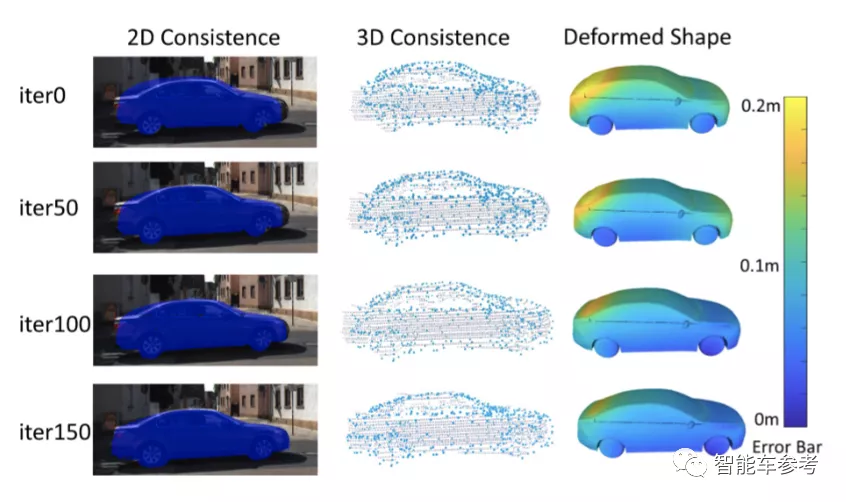
實驗結果
研究人員在KITTI 3D目標檢測基準上測試了這一新方法的性能。
KITTI 3D目標檢測基準包含7481張訓練圖像、7518張測試圖像,以及對應的點云,總共包括80256個標記對象。
在這項研究中,由于測試集的真實數據不可用,研究人員將訓練數據分為訓練集(3712個樣本)和驗證集(3769個樣本),用以完善模型。
另外,用以測試的模型是在2塊英偉達V100上訓練完成的,批量大小設為16。
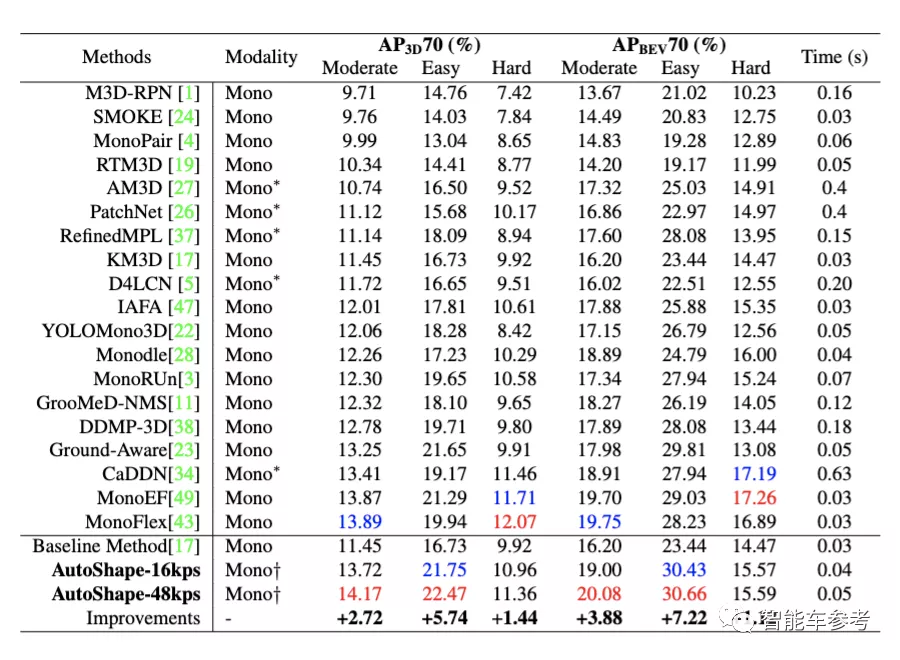
△紅色代表最佳結果,藍色代表次佳結果
可以看到,在全部6個任務中,采用了48個關鍵點的AutoShape方法取得了4項第一。而采用16個關鍵點的AutoShape速度更快,準確性損失也并不大。

此外,從上圖中可以看出,模型預測的3D形狀與真實物體一致性較高。
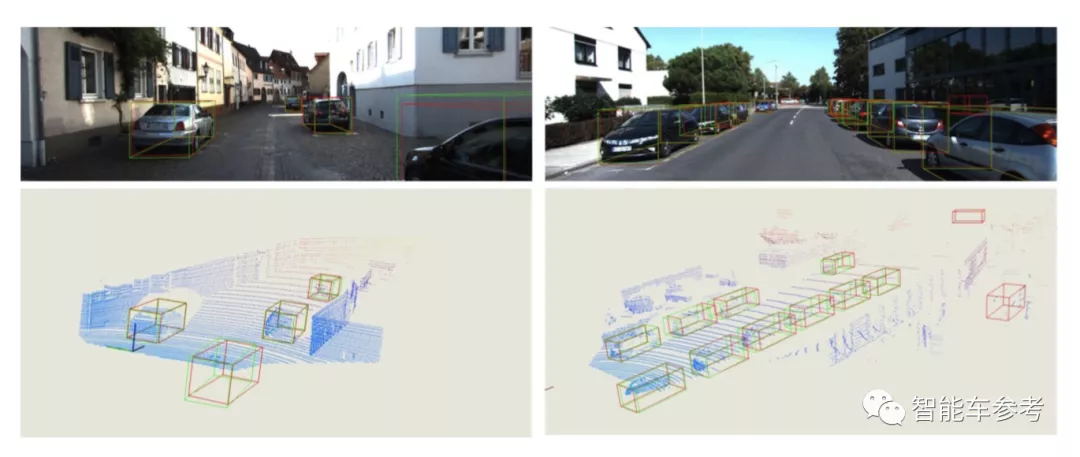
即使是畫面中位置較遠的車輛、被截斷/遮擋的物體,其位置也能被準確檢測到。
總而言之,相比于其他現有方法,AutoShape更準確,并且推理速度更快,可以達到25FPS的處理速度,也就是說可以實現實時檢測的效果。
論文地址:
https://arxiv.org/abs/2108.11127
項目地址:
https://github.com/zongdai/AutoShape









